【TiDB 使用环境】生产环境
【部署方式】腾讯云/32c128GNVME盘
【集群数据量】11T
【集群节点数】13
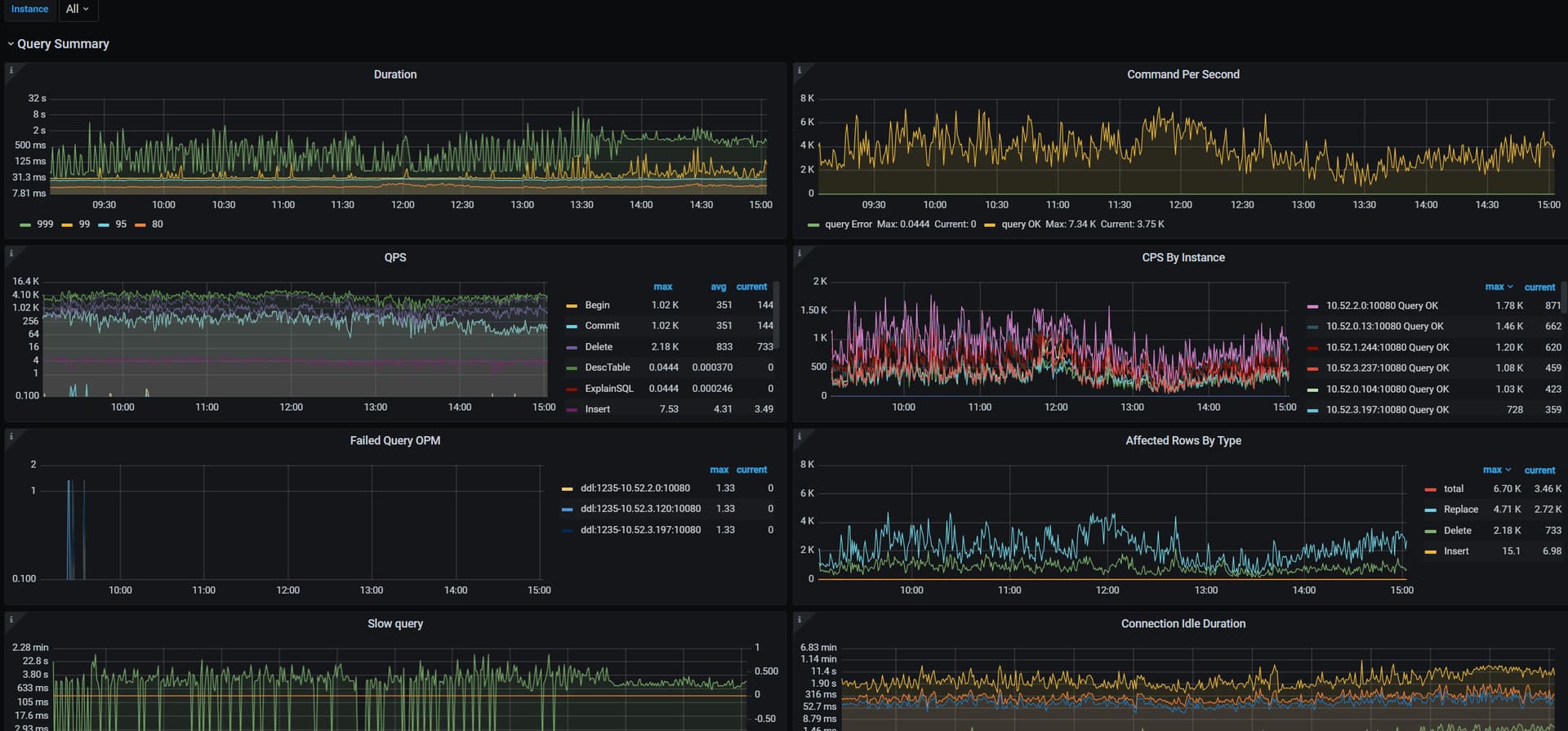
目前有八个同步任务,分了8个task且均为默认dm参数 但tidb未接入业务流量,会经常出现延迟 请教大家看如何优化
【TiDB 使用环境】生产环境
【部署方式】腾讯云/32c128GNVME盘
【集群数据量】11T
【集群节点数】13
目前有八个同步任务,分了8个task且均为默认dm参数 但tidb未接入业务流量,会经常出现延迟 请教大家看如何优化
猫哥 这边没接入业务流量 都是dm的流量 之前旧集群3副本的就没这个延迟 这个延迟是五副本的情况
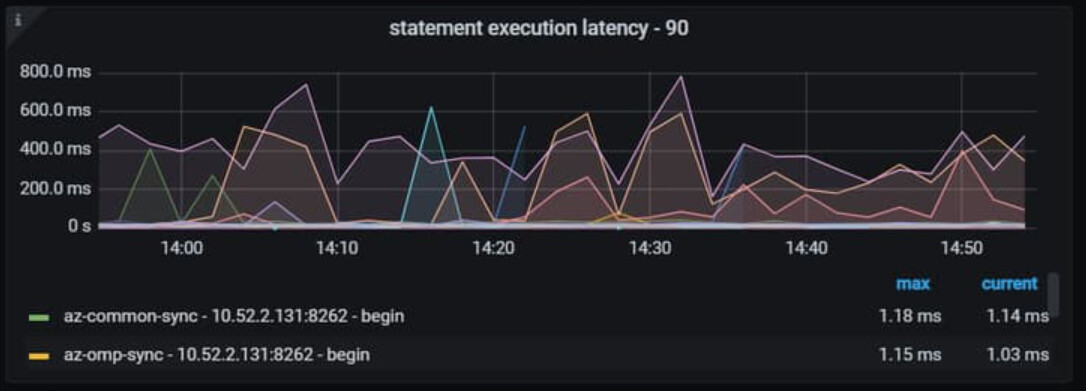
你怀疑没问题,还是要看看延迟拆解的图。确认一下。
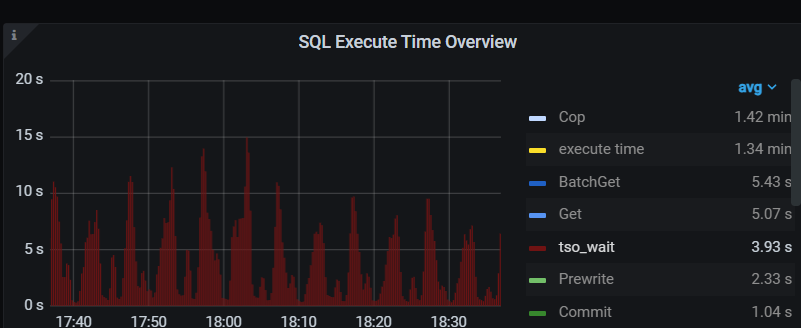
time:30.1s, loops:2, Get:{num_rpc:2, total_time:30s}, rpc_errors:{context deadline exceeded:1},tikvRPC_backoff:{num:1, total_time:56ms}, time_detail: {total_process_time: 308.4µs, total_wait_time: 349µs, total_kv_read_wall_time: 664.6µs, tikv_wall_time: 680.3µs}, scan_detail: {total_process_keys: 1, total_process_keys_size: 232, total_keys: 1, get_snapshot_time: 324.6µs, rocksdb: {block: {cache_hit_count: 14, read_count: 1, read_byte: 4.36 KB, read_time: 123.7µs}}} 猫哥 有空看看 集群节点网络是没啥问题的 最大延迟跨区10ms 为什么rpc调用时间那么久呢Get:{num_rpc:2, total_time:30s}
全部慢语句都是rpc时间很久
有一次rpc超时了没连上,同时期,网络有啥异常没有?
没啥异常的 所以很奇怪

这个就已经不正常了。高得离谱。仅获取tso已经是慢查询了。都不用干别的。
有那个节点跨子网了?这个按我的经验,应该是某个节点ping pd leader到25ms左右了。
是有跨区的 目前是10ms延迟
https://docs.pingcap.com/zh/tidb/stable/three-data-centers-in-two-cities-deployment/#参数配置优化
你要看看这个部分。
希望你没有弄3个子网,如果是2个子网还有救。
确保leader只在一个子网内,然后pd通过优先级也控制在这个子网内。
也就是所有的leader和pd在一个子网内,ping控制在1ms以下最好。
好的 我这边继续优化下 我看看效果
有后续发下 参考参考