【TiDB 使用环境】生产环境
【TiDB 版本】 8.1.0
【操作系统】 ubuntu
【部署方式】阿里云 16核、32G内存、1TB磁盘
【集群数据量】 212G
【集群节点数】 3台
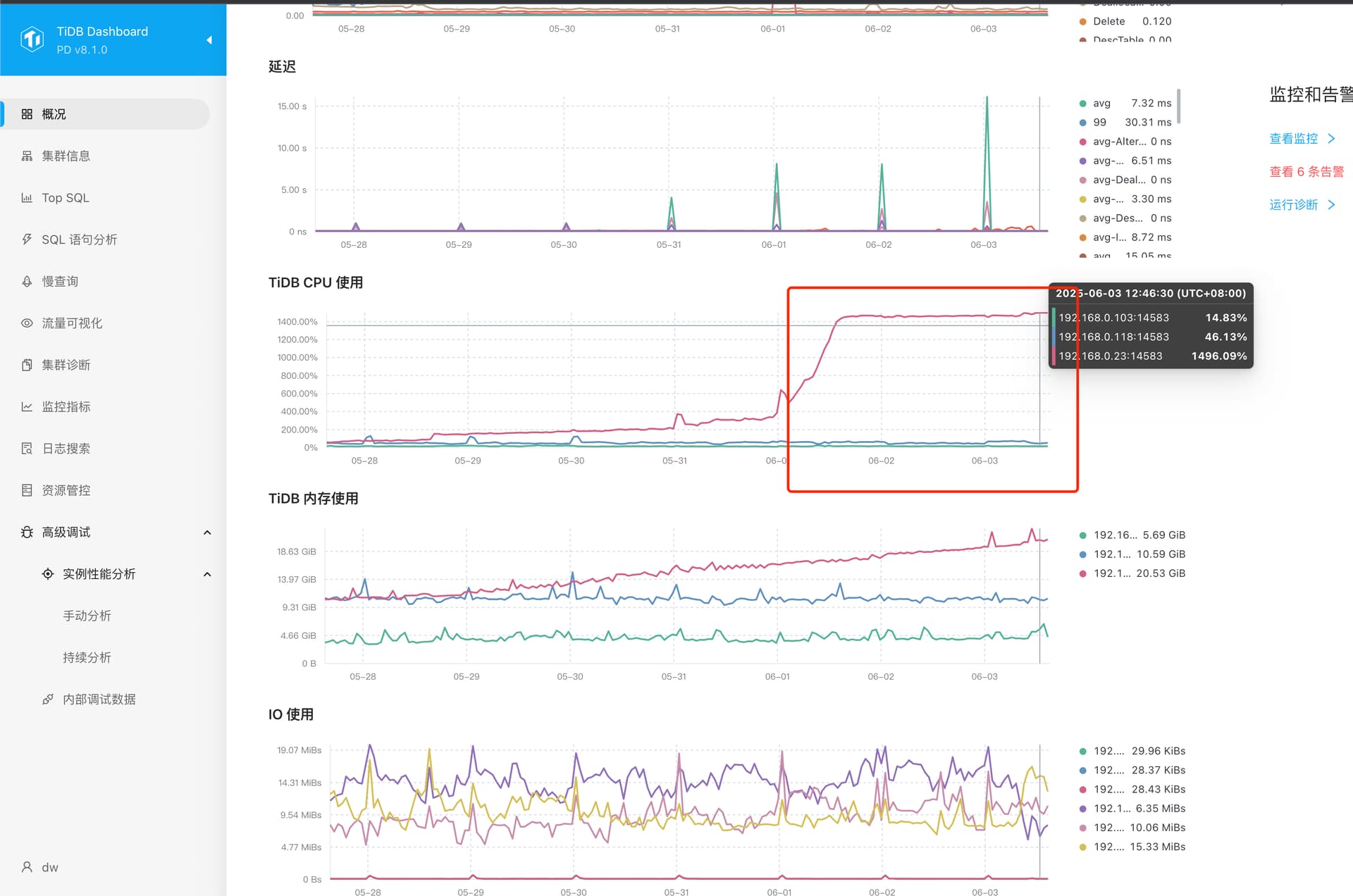
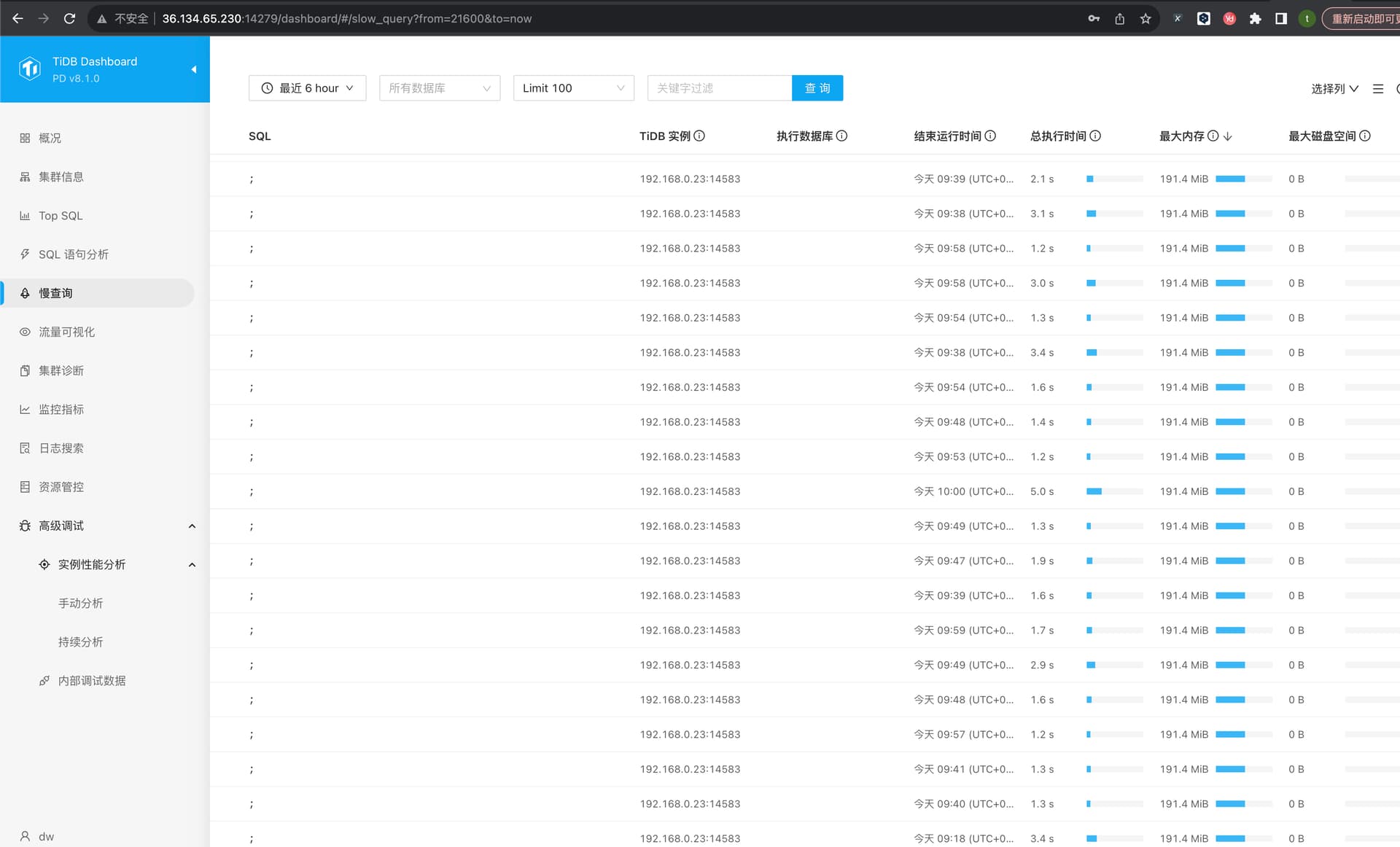
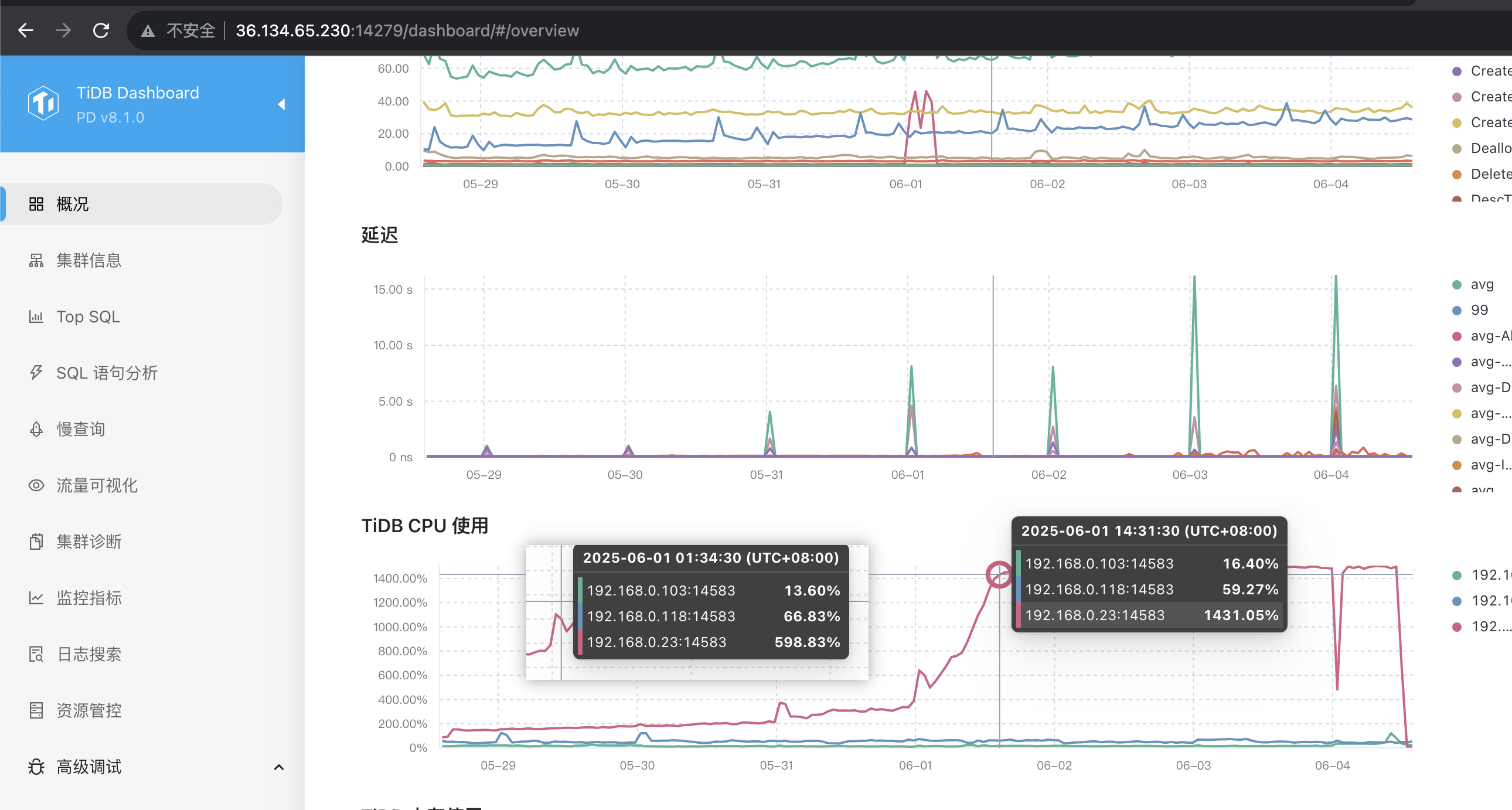
【问题复现路径】 重启后过了几天又开始采样异常,一直消耗某节点资源,只有再次重启后,循环出现该问题。
【遇到的问题:问题现象及影响】 浪费一个节点的资源
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
总共3台机器,3个tidb、3个tikv、3个pd都在这3台机器中。
清风明月
4
192.168.0.118是这台服务器出现的问题么
Ming
6
去Dashboard的TOP SQL观察对应服务器对应组件的资源占用SQL是什么
清风明月
7
tidb集群应该是混布的吧,有cdc、pd、tikv。最好tikv和其他的分开部署吧。
asmile
(TiDBer 叶明)
8
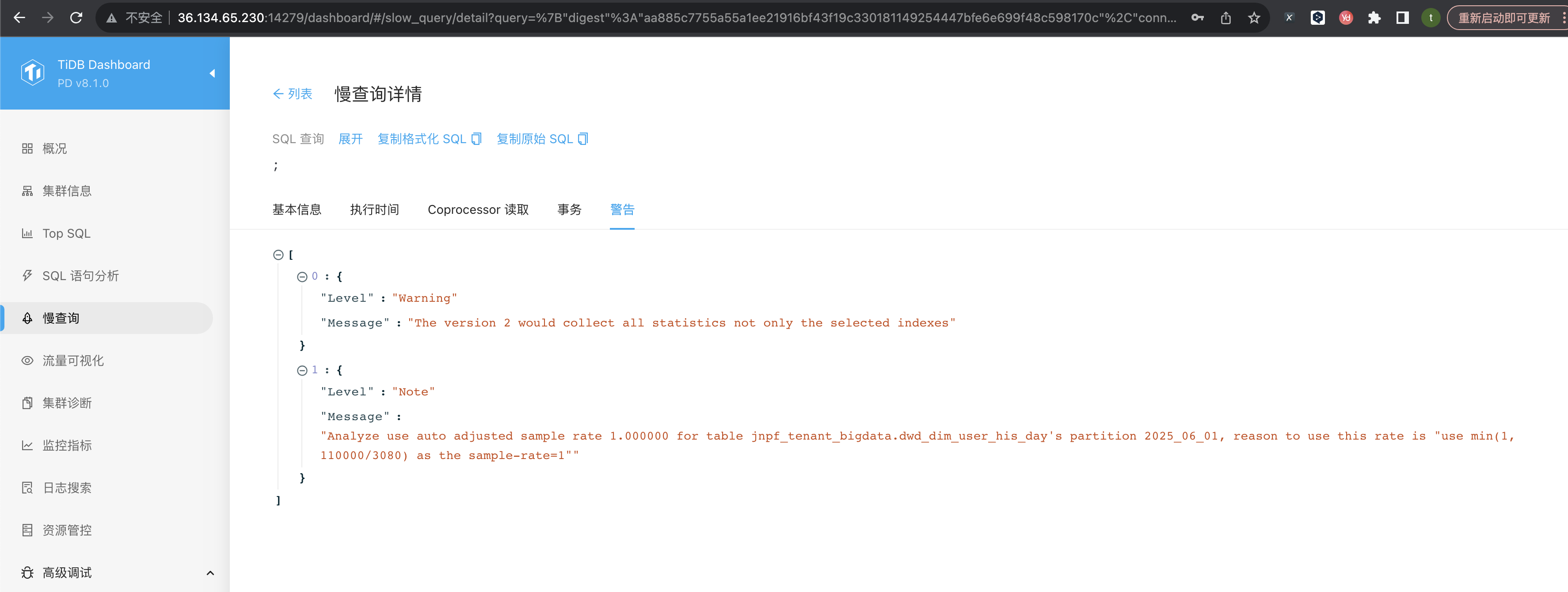
这什么也看不出来,没日志,慢查询也没,光看这个截图能看出什么?
如果有很大的表的话不建议自动收集,因为自动收集是单线程的,时间可能会很长,并且不一定成功,建议手动部署脚本修改并发参数按比例收集大表。