julyxiong
(Hacker Jsjt Zo R8)
1
【TiDB 使用环境】生产环境
【TiDB 版本】 8.5.1
【操作系统】Rock Linux 9
【部署方式】物理机部署 CPU:56C/内存: 256G/硬盘: nvme 4T * 2
【问题复现路径】
【遇到的问题:问题现象及影响】
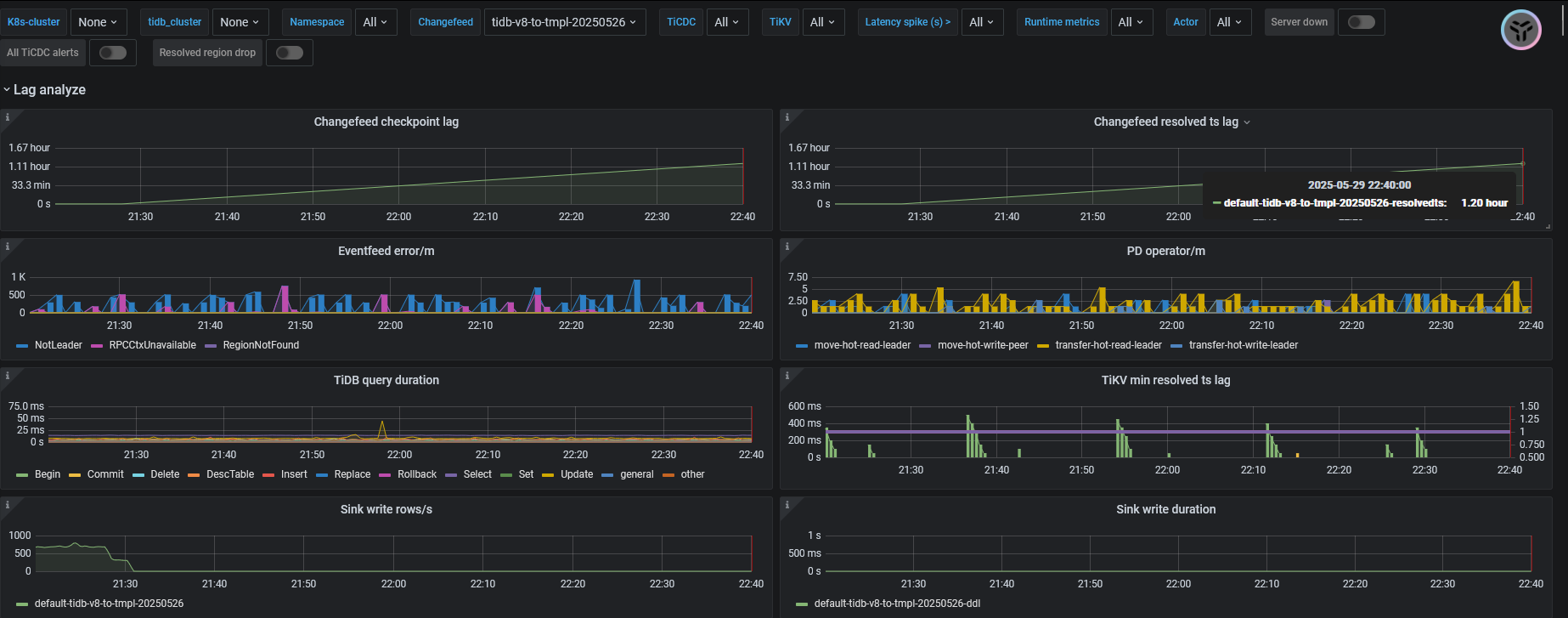
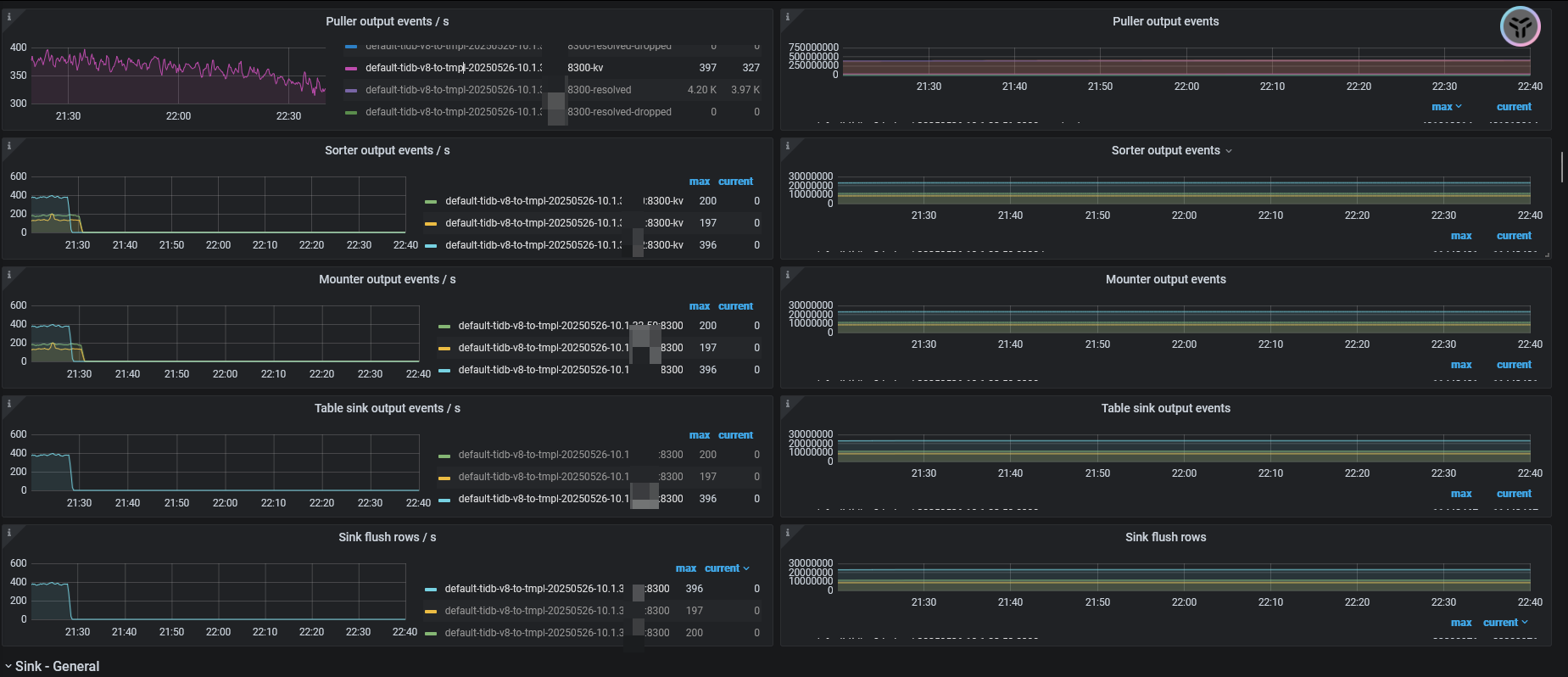
创建changefeed后正常跑的情况下,checkpoint lag 会突然增大,并且不能自行恢复,重启cdc后恢复正常。
【复制黏贴 ERROR 报错的日志】
无ERROR日志,CDC有很多warn日志,如下
[2025/05/29 21:28:56.576 +08:00] [WARN] [transport.go:138] [“schedulerv3: message send failed since ignored, retry later”] [namespace=default] [changefeed=tidb-v8-to-tmpl-20250526] [to=2a584e8c-b188-4737-a5f0-500e72ea3b34] [ignoreCount=540] [totalMsg=1852753] [ignoreRate=0.00029145817062501046] [role=scheduler]
[2025/05/29 21:28:56.649 +08:00] [WARN] [transport.go:138] [“schedulerv3: message send failed since ignored, retry later”] [namespace=default] [changefeed=tidb-v8tov3-task] [to=2a584e8c-b188-4737-a5f0-500e72ea3b34] [ignoreCount=541] [totalMsg=1856524] [ignoreRate=0.0002914047973524716] [role=scheduler]
【其他附件:截图/日志/监控】
julyxiong
(Hacker Jsjt Zo R8)
2
差不多每天都要发生一次,根据官网给的排错文档,也找不到原因。目前只能排查到出问题的cdc节点,然后重启下节点,同步就恢复正常了。
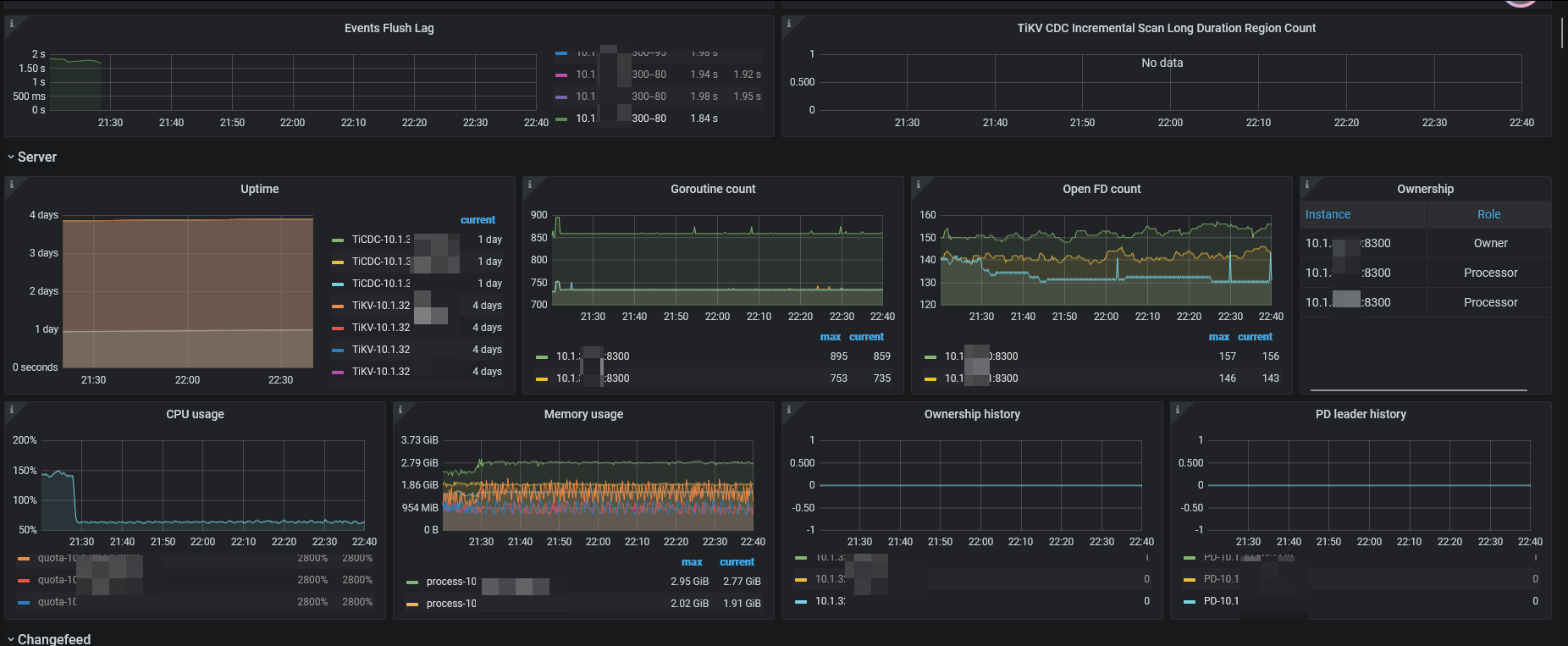
但是如果没有及时解决问题,tikv的sink memory 超过512M后,tikv的CPU就会暴涨,可能会潜在影响集群性能。
julyxiong
(Hacker Jsjt Zo R8)
3
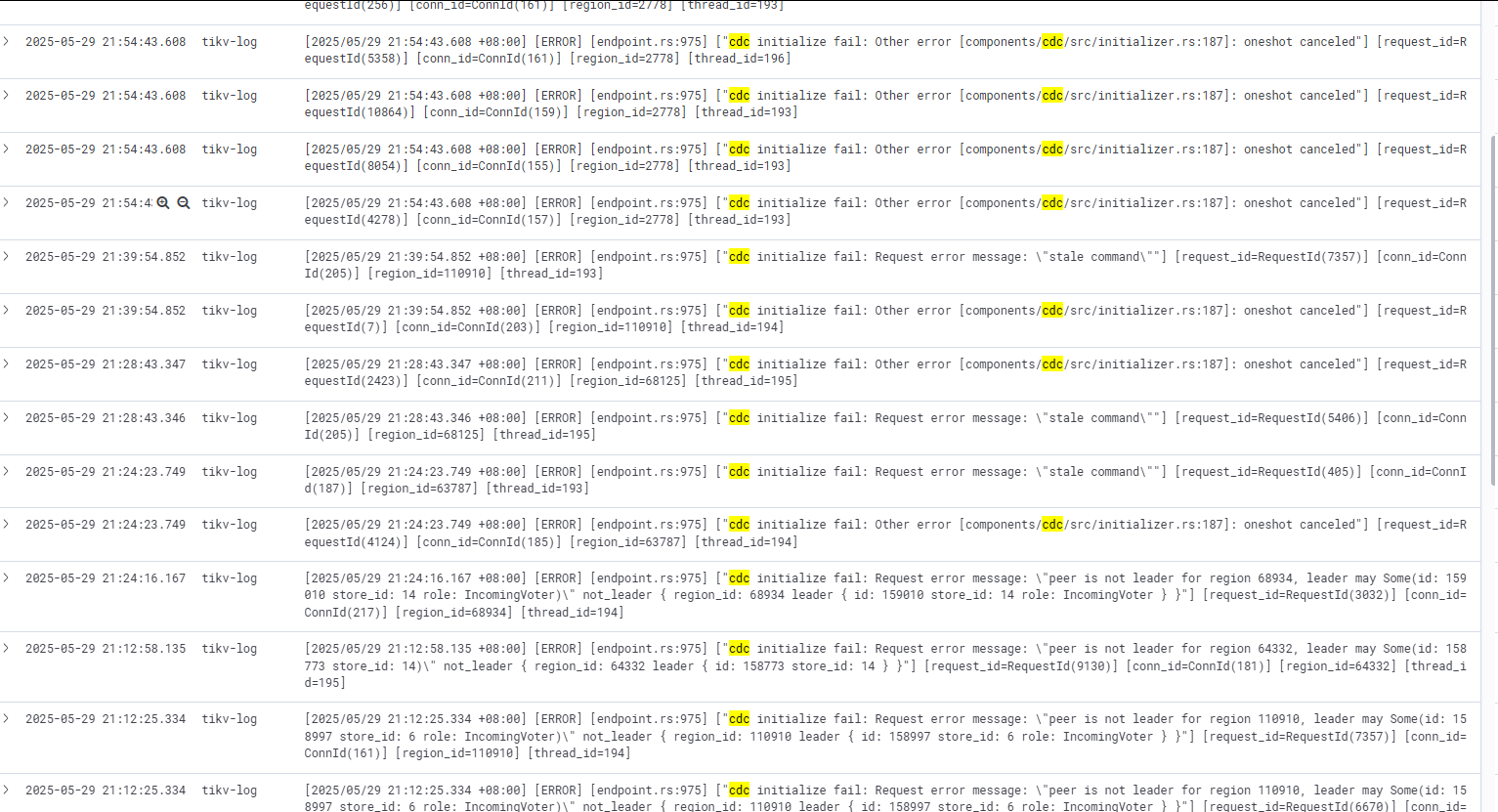
卡住时TIKV的错误日志。这些日志在平时也有出现。
试过centos吗?我之前用rocket9 测试,资源使用比centos7高
TiDBer_wk
(Ti D Ber Os7emy Bg)
6
每天发生的时间是固定时间吗?重启后第二天又出现了?这段时间有做什么操作吗
wenyi
(Wenyi)
7
tidb部署在centos7.9,要比rocky9.5,性能好?
message send failed since ignored, retry later
可能要检查下网络超时、对端数据库资源状态之类的信息吧
我年初的时候测试一个集群多个tikv节点不同系统 rocket9比centos7资源消耗多百分之20
wenyi
(Wenyi)
10
我的理解,tidb部署在rocky9性能应该比部署在centos7高
rocky9系统比centos7性能、安全性高
TiDBer_wk
(Ti D Ber Os7emy Bg)
11
julyxiong
(Hacker Jsjt Zo R8)
13
时间不固定的。
起初只有一个 changfeed,是同步到 tidb v8.5.1的,跑了几天都正常。后来添加一个同步到tidb v3.0.3 版本后,就经常卡住 。
julyxiong
(Hacker Jsjt Zo R8)
14
使用tiup收集诊断信息时碰到2个问题。
1, 收集日志卡了半小时,实际应该传好了。
2, 使用 upload在线上传包时,提示SSL证书错误。
julyxiong
(Hacker Jsjt Zo R8)
15
也有可能 3 个CDC节点中,非leader的一个节点异常引起的调度出错。