![]() 2025 年,TiDB 社区特别策划了“TiDB vs MySQL :国产数据库替换 & 降本增效的不二选择 ”系列线上 Meetup,从不同视角、不同需求、业务形态、技术演进等多个维度和大家一起聊透国产数据库选型,也希望通过这一系列活动让大家更好地了解 TiDB,看看 TiDB 是否能帮到你解决目前面临的技术架构难题,为大家排忧解难。
2025 年,TiDB 社区特别策划了“TiDB vs MySQL :国产数据库替换 & 降本增效的不二选择 ”系列线上 Meetup,从不同视角、不同需求、业务形态、技术演进等多个维度和大家一起聊透国产数据库选型,也希望通过这一系列活动让大家更好地了解 TiDB,看看 TiDB 是否能帮到你解决目前面临的技术架构难题,为大家排忧解难。
![]() TiDB vs MySQL 系列第四期线上 Meetup,我们邀请了 TiDB 高级售后顾问谢泽群老师和大家分享了 70多页 TiDB 性能优化相关干货,涵盖 TiDB SQL 优化思路、工具、脚本,以及如何规避热点问题、不同 Join 方式适用场景、大事务拆分、资源管控等实践指南内容。
TiDB vs MySQL 系列第四期线上 Meetup,我们邀请了 TiDB 高级售后顾问谢泽群老师和大家分享了 70多页 TiDB 性能优化相关干货,涵盖 TiDB SQL 优化思路、工具、脚本,以及如何规避热点问题、不同 Join 方式适用场景、大事务拆分、资源管控等实践指南内容。
PPT 下载:
TiDB 性能调优最佳实践by泽群老师|TiDB vs MySQL Meetup 第四期.pdf (9.5 MB)
视频回顾
分享回顾
“在问题出现之前,提前进行 SQL 优化”。
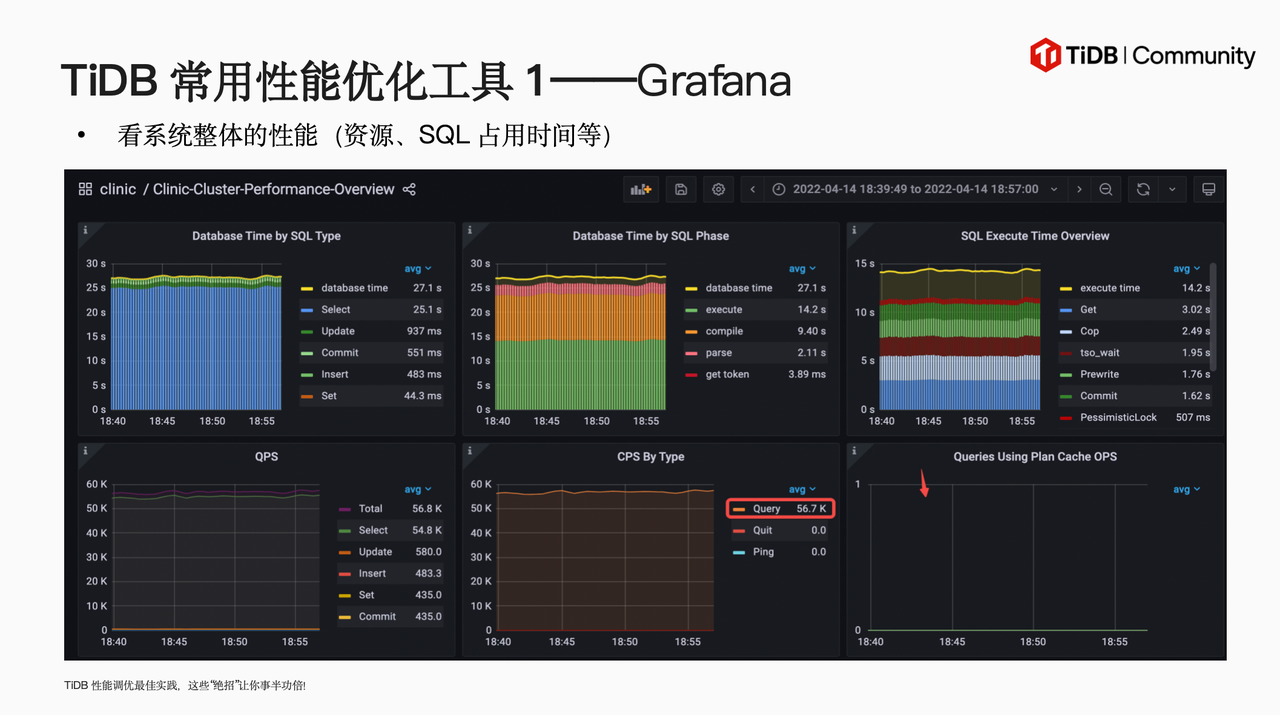
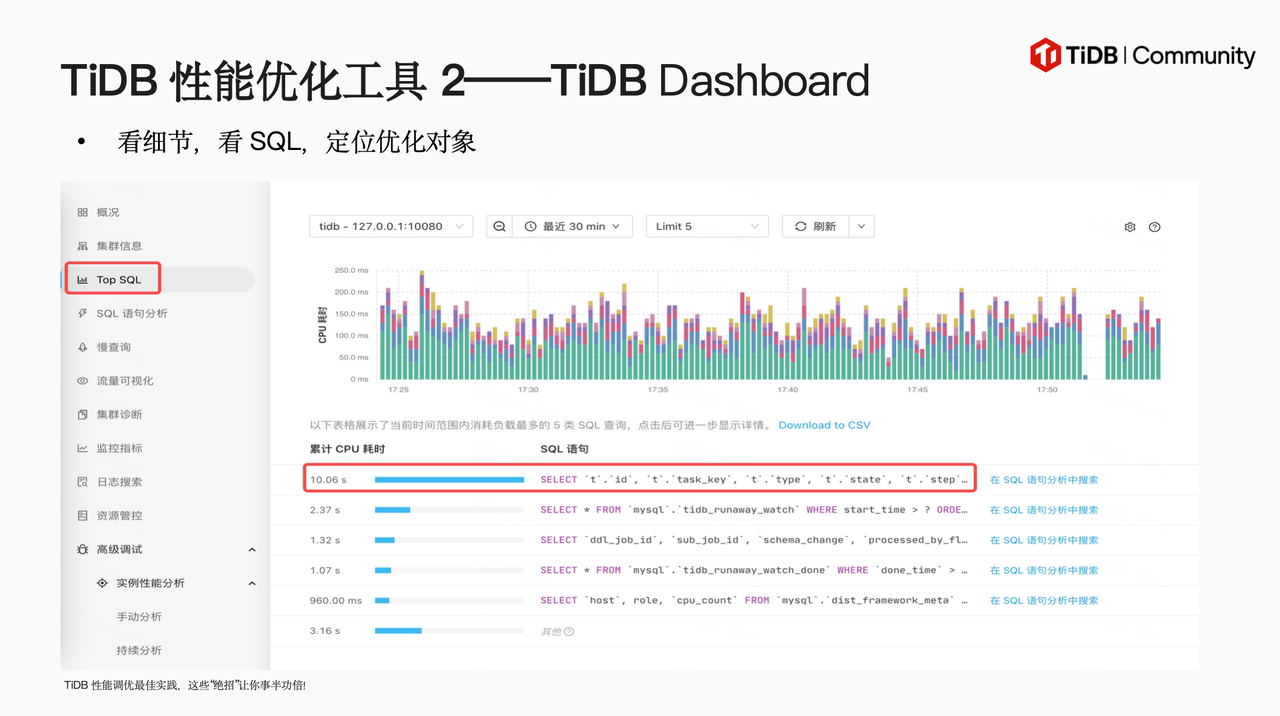
谢老师从 TiDB 性能优化思路开启本次分享,介绍了建立性能基线需要采集的各项性能数据,并向大家安利了两个 TiDB 性能优化工具 Grafana(用于查看系统整体性能)、Dashboard(用于定位优化对象)。
对于如何实现 TP 场景 TiDB ms 级优化、TiDB 批量场景性能优化,谢老师也分享了相关文档资料,帮助大家更好地应对不同运行场景下的性能分析和优化过程。
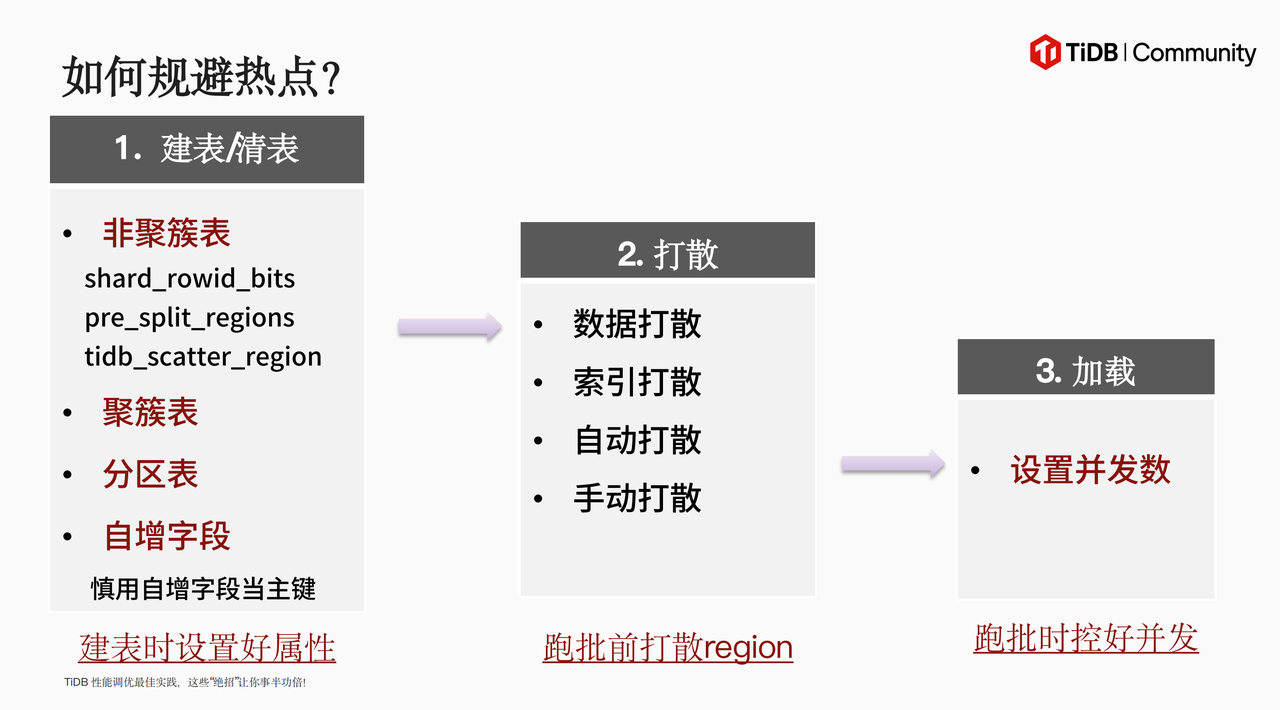
AP 场景数据加工流程第一步:文件入库。分享中介绍了 TiDB 数据导入三大工具(load data、lightning、import into)可以帮助大家让文件入库更丝滑。针对数据导入热点问题,谢老师从热点形成原因与如何规避热点两大角度进行解答,通过建表/清表、打散、加载的“三步走思路”,提升并发加载速度。
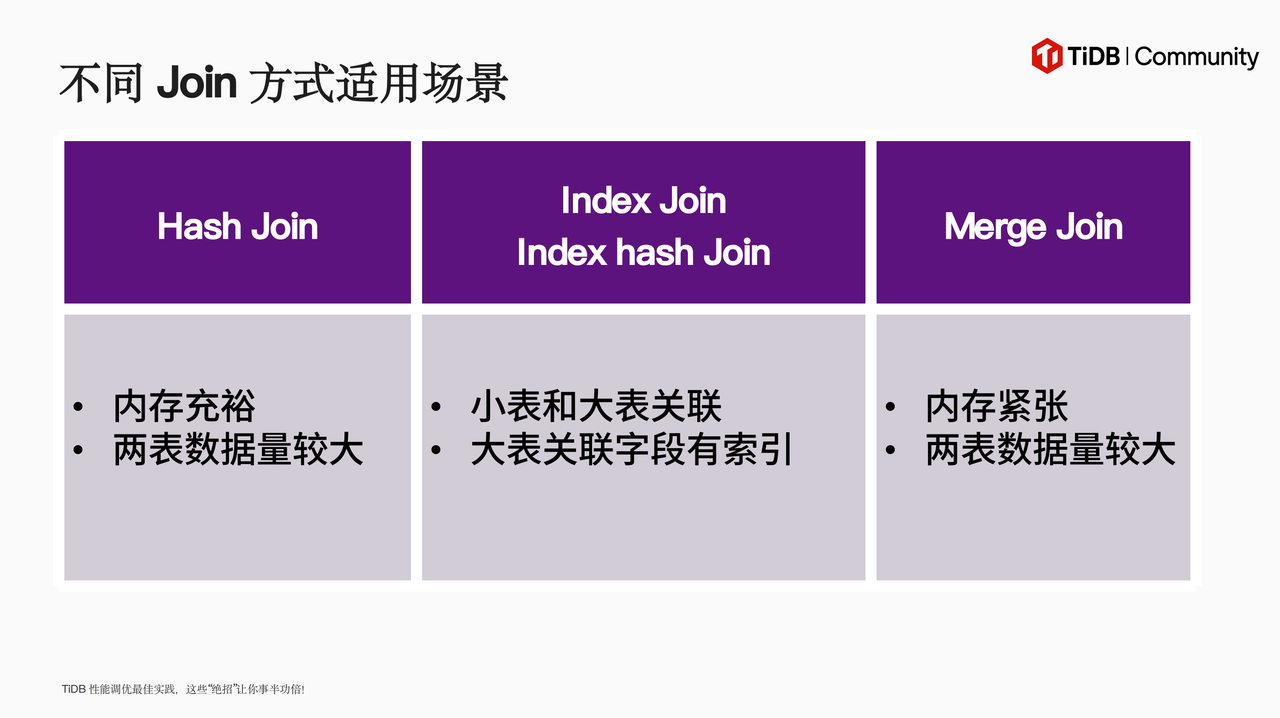
关于数据加工中的性能优化,谢老师详细分享了 Join 方式、大事务拆分、 SQL 优化、 SPM 四类实践,并为大家介绍了丰富的优化细节、提效工具。对于数据加工环节的注意事项也进行了总结,如 SQL 优化需要避免不必要的数据类型转换,使用分区表减少数据访问量等。针对十余项注意事项,谢老师为大家带来了许多实践过程可以应用的“小妙招”,例如在进行去重 SQL 优化时,可以根据去重中间结果是否大于最后关联结果来判断是否需要先关联后去重。
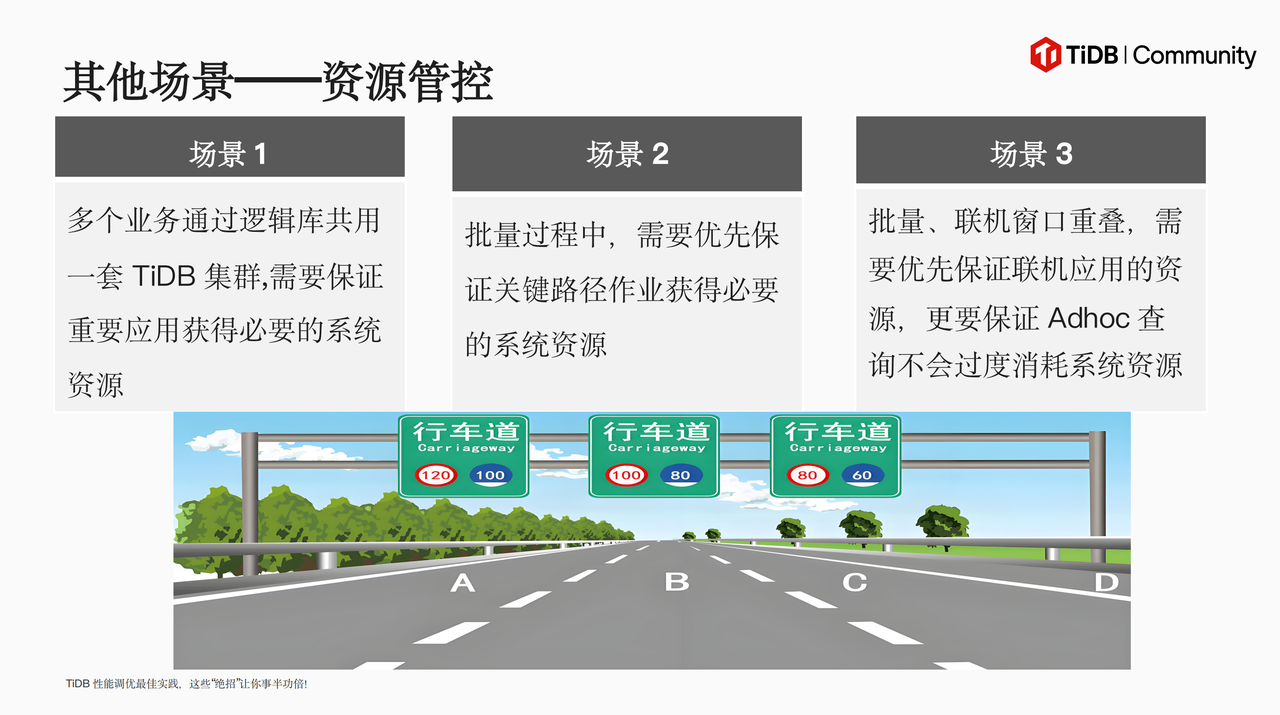
最后,关于数据导出以及如何用好 TiDB 资源管控特性,谢老师也给出了非常具有实操价值的建议,并向大家安利了 TiKV MVCC 内存引擎、TiDB 索引推荐(Index Advisor)功能。









留言有奖!
在评论区分享参与本次活动的收获,抽三位小伙伴送出 TIDB 社区新款工业风咖啡杯!
- 有效留言时间:截止 6 月 5 日

