【 TiDB 使用环境】生产环境
【 TiDB 版本】7.5.3
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】*
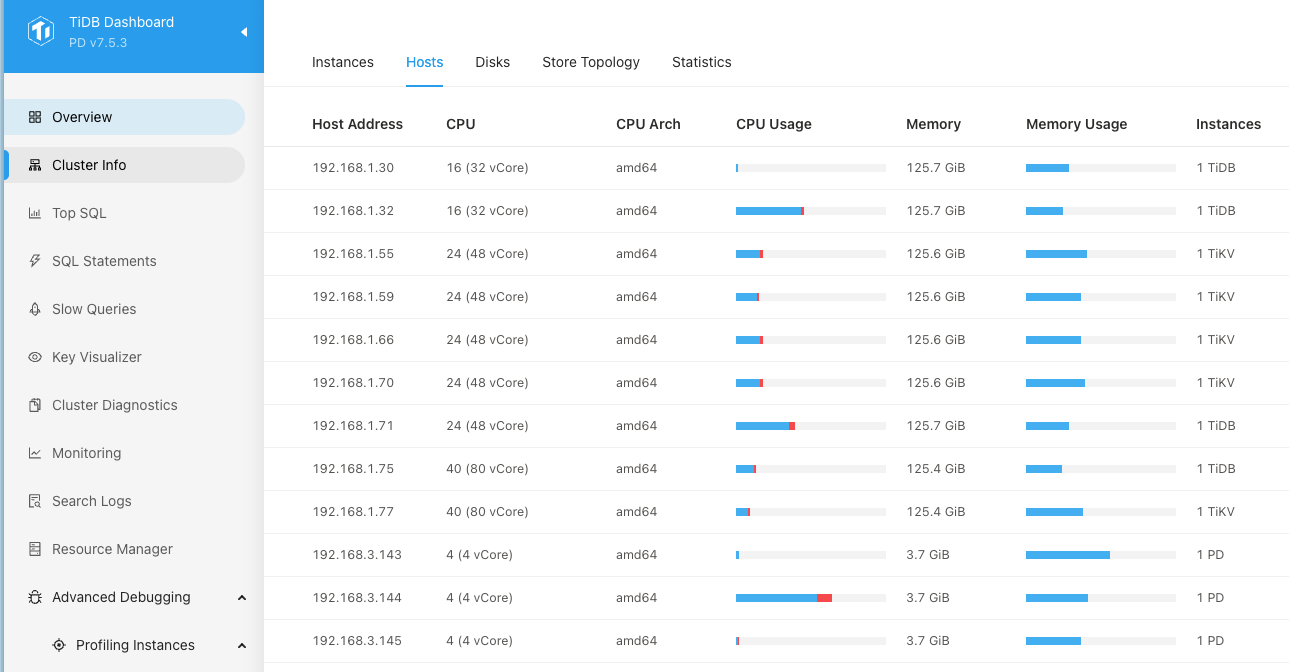
另外因为目前的集群数据量超级大,5个tikv节点,每个节点的store存储已经1TB数据
目前的需求是迁移原TIDB集群中的某些库到另外一个TIDB集群中去,参考的是官方文档 从 TiDB 集群迁移数据至另一 TiDB 集群 https://docs.pingcap.com/zh/tidb/stable/migrate-from-tidb-to-tidb/
过程中在使用tiup br backup db --db xxx的时候,超级慢,通过日志发现 卡在某个 region (range-sn=29)上,有如下日志
... ...
[2025/05/24 10:03:14.647 +08:00] [INFO] [client.go:889] ["Backup Ranges Started"] [ranges="{total=424,ranges=\"[\\\"[74800000000001CA2F5F720000000000000000, 74800000000001CA2F5F72FFFFFFFFFFFFFFFF00)\\\",\\\"(skip 422)\\\",\\\"[74800000000001CB175F69800000000000000200, 74800000000001CB175F698000000000000002FB)\\\"]\",totalFiles=0,totalKVs=0,totalBytes=0,totalSize=0}"]
... ...
... ...
[2025/05/24 10:14:43.438 +08:00] [INFO] [client.go:1131] ["start fine grained backup"] [range-sn=29] [incomplete=1]
[2025/05/24 10:14:43.441 +08:00] [INFO] [client.go:1067] ["find leader"] [range-sn=29] [Leader="{\"id\":32209738,\"store_id\":20006703}"] [key=74800000000001CAFF3D5F720000000000FF0000000000000000FA]
[2025/05/24 10:14:43.441 +08:00] [INFO] [client.go:1438] ["try backup"] [range-sn=29] ["retry time"=0]
[2025/05/24 10:15:14.705 +08:00] [INFO] [checkpoint.go:610] ["start to flush the checkpoint lock"] [lock-at=1748052914632] [expire-at=1748053214632]
[2025/05/24 10:19:14.696 +08:00] [INFO] [checkpoint.go:610] ["start to flush the checkpoint lock"] [lock-at=1748053154632] [expire-at=1748053454632]
[2025/05/24 10:23:14.703 +08:00] [INFO] [checkpoint.go:610] ["start to flush the checkpoint lock"] [lock-at=1748053394633] [expire-at=1748053694633]
[2025/05/24 10:26:08.701 +08:00] [WARN] [retry.go:136] ["occur storage error"] [scenario=handleFineGrainedBackup] [error="Io(Custom { kind: Other, error: \"failed to put object rusoto error Error during dispatch: error trying to connect: dns error: failed to lookup address information: Name or service not known\" })"]
[2025/05/24 10:26:08.702 +08:00] [INFO] [client.go:1210] ["handle fine grained"] [backoffMs=3000]
[2025/05/24 10:26:11.703 +08:00] [INFO] [client.go:1131] ["start fine grained backup"] [range-sn=29] [incomplete=1]
... ...
[2025/05/24 11:23:39.567 +08:00] [INFO] [client.go:1067] ["find leader"] [range-sn=29] [Leader="{\"id\":32209738,\"store_id\":20006703}"] [key=74800000000001CAFF3D5F720000000000FF0000000000000000FA]
range-sn 从10:03开始的,目前已经1个小时还卡在这个上面,看错误信息提示 dns error.
1、这个卡顿的根源是什么? 是集群整体数据存储过大?还是因为单节点存储过大?
2、这里的dns error 是什么 , 我是备份到腾讯云的COS ,过程中检测 腾讯云COS 地址一直是OK的,应该和腾旭云COS域名没有直接关系(我的tiup管理 不管是部署在机房还是腾讯云都有这个问题, 机房和腾讯云是专线打通的)