【TiDB 使用环境】测试环境
【TiDB 版本】v8.1.2
【操作系统】ubuntu 20.04 LTS
【部署方式】机器部署
【集群数据量】12G
【集群节点数】本地服务器部署1monitor+3tiflash/tikv/pd/tidb, 单节点8c32G内存,数据盘data1和data2分别50G,tiflash 2副本
【问题复现路径】
资源控制功能已开启。
1、创建资源组rg_service_user,绑定用户service_user到该资源组,该用户已具有相应数据库的读写权限;
2、配置资源组query_limit规则,进行sql并发压测,都没有在mysql.tidb_runaway_queries表里查到处理记录,所有sql都在正常执行。如果加上WATCH=SIMILAR DURATION=‘1m’,也是一样,没有效果。
ALTER RESOURCE GROUP rg_service_user RU_PER_SEC=10000 BURSTABLE QUERY_LIMIT=(EXEC_ELAPSED=‘2s’, ACTION=KILL);
或配置发现及添加到监控列表:
ALTER RESOURCE GROUP rg_service_user RU_PER_SEC=10000 BURSTABLE QUERY_LIMIT=(EXEC_ELAPSED=‘2s’, ACTION=KILL, WATCH=SIMILAR DURATION=‘1m’);
3、取消QUERY_LIMIT的WATCH=SIMILAR DURATION=‘1m’,继续添加QUERY WATCH,效果是直接把识别到的sql kill掉了,也就是只有手动配置QUERY WATCH,才能达到立即kill的效果(sql执行报错Quarantined and interrupted because of being in runaway watch list),但是我想只看QUERY_LIMIT能不能控制sql 超时触发条件再被kill:
QUERY WATCH ADD RESOURCE GROUP rg_service_user ACTION KILL SQL TEXT SIMILAR TO “select rel.id, …省略…”;
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面

【其他附件:截图/日志/监控】
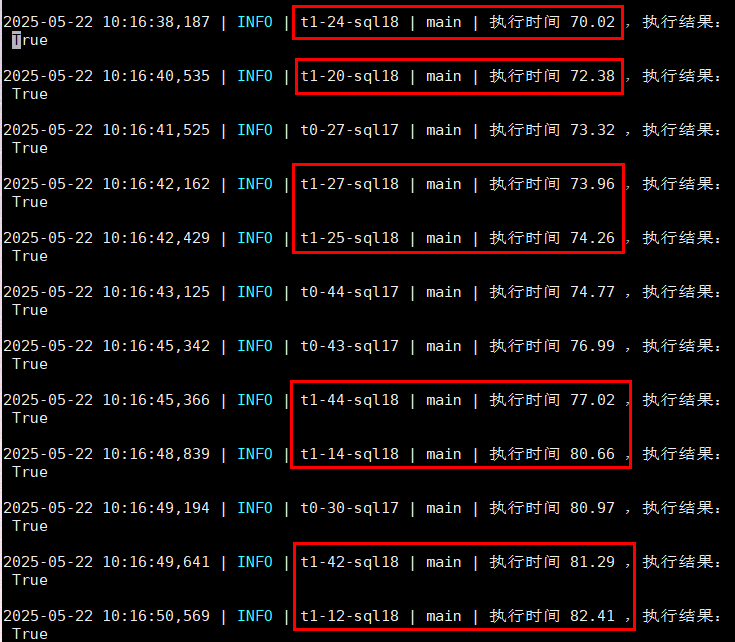
图中sql18是配置了QUERY_LIMIT的sql,集群无压力的情况下,正常执行一次1.7s,在压测上来时,执行时间超过QUERY_LIMIT配置的60s,却还在执行;
查看监控隔离表,也没记录:
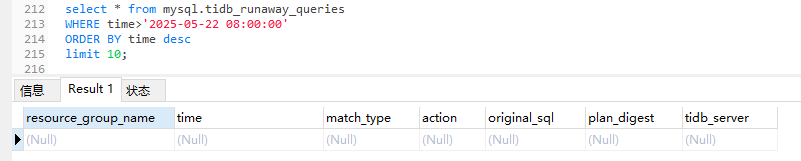
资源组信息里,有QUERY_LIMIT配置:

