老鹰506
(Ti D Ber Uhzt Tfx J)
1
【TiDB 使用环境】生产环境
【TiDB 版本】7.5.3
【操作系统】
【部署方式】机器部署
【集群数据量】
【集群节点数】
【问题复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
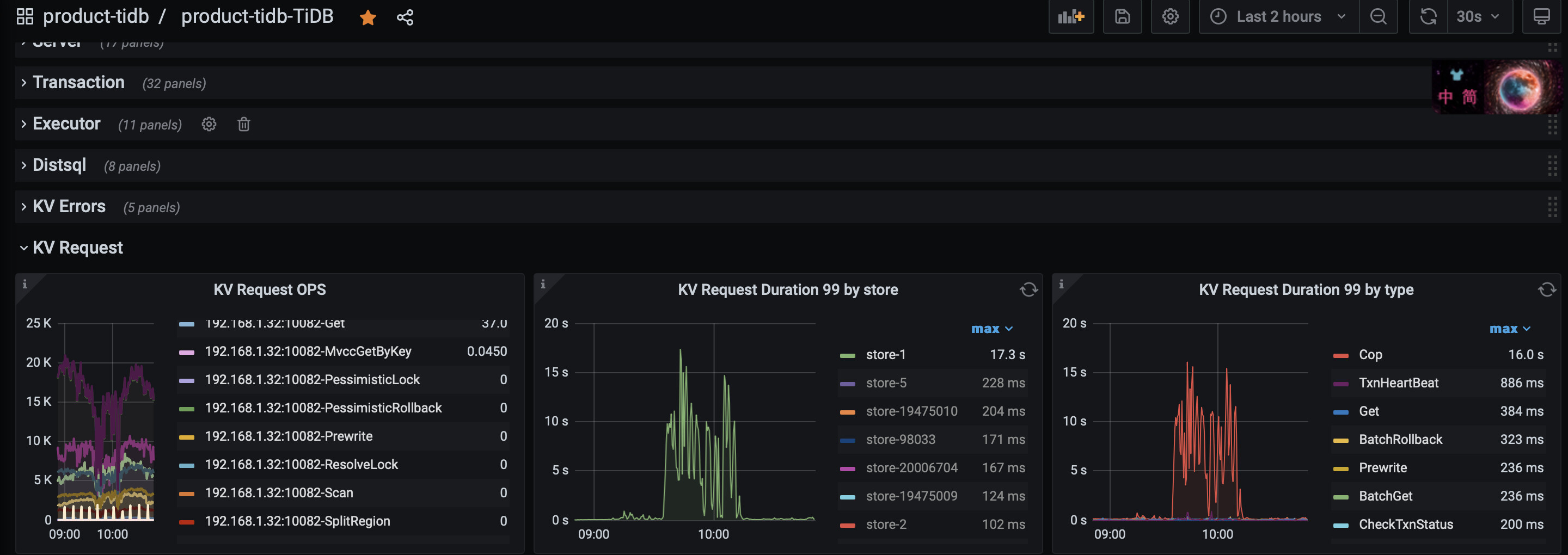
集群的配置信息如下, 然后突然发现集群中某个tikv节点的 ”KV request duration“变得很慢, 通过旁边的 类型对比发现是 ”Cop" 操作导致
这个Cop操作具体是做什么,什么导致它的请求变多呢?
xfworld
(魔幻之翼)
2
Store-1 这个节点和其他节点的时长差很多哦,可以看下是否有读偏斜导致的 cop 缓慢?
看下store1对应机器对应时间段的cpu使用率把,cop就是数据聚合操作,一般是大批量的region扫描导致cpu使用率增高导致他变慢
1 个赞
老鹰506
(Ti D Ber Uhzt Tfx J)
4
看了下那个时间时间段CPU使用率反倒是下降的,而且对应的 Command per second 也出现了下降, 这个应该是果,是store响应慢了,有些sql没有处理的过来报错了
老鹰506
(Ti D Ber Uhzt Tfx J)
5
看了下没有读偏,目前怀疑是不是很做节点下线有关系呢。 在出现这个问题之前, 好几个tikv的io read 出现很高的读带宽
老鹰506
(Ti D Ber Uhzt Tfx J)
7
不是store1 是其他store, 和 store1位于同一个主机上,但是应该不是这个问题,这个下线是前天晚上就开始执行的。
我看那个点 server过来的连接数突然增大了些 ,现在排查是不是这个导致的
老鹰506
(Ti D Ber Uhzt Tfx J)
10
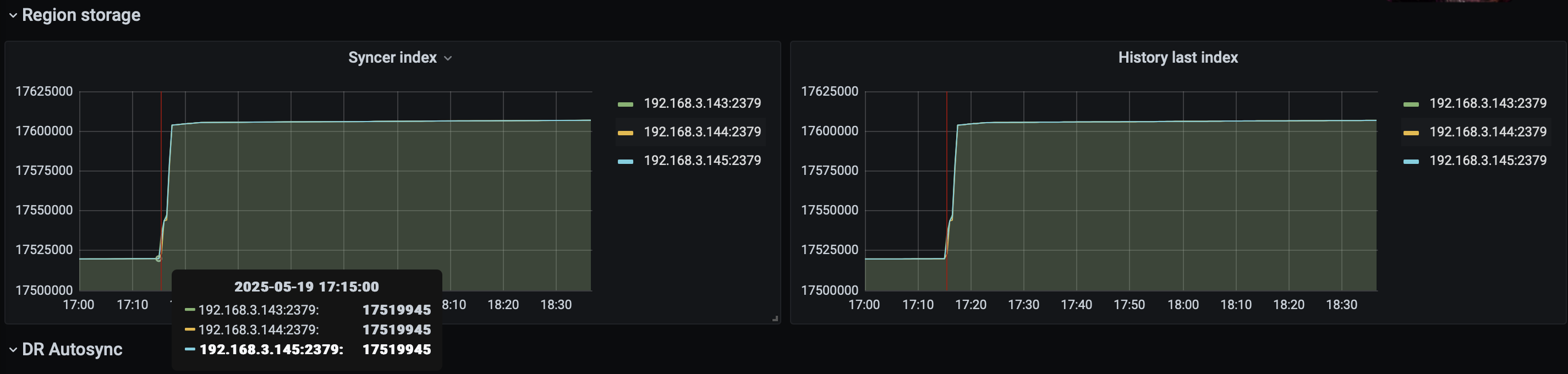
那个时间段是region还在迁移;
昨下午又出现了其他store的kv request 慢的波动的,是其他主机节点的,感觉和主机部署多个节点没有关系
根据楼主贴的监控图信息,是store-1 这个tikv节点出现了访问延迟过高,单点瓶颈问题导致cop 任务(在存储层扫描读取数据的过程)出现了慢的现象。
先确认store-1对应的ip和节点,然后重点分析下它:
1、是否有热点问题
2、是否节点当时过于繁忙导致的抖动问题
3、根据该节点的tikv日志,分析当时有无其他异常信息,结合集群当时的现状深入分析
1 个赞
是不是迁移的数据影响的,pdctl看下下面这些参数,适当修改小一点看下 leader-schedule-limit, region-schedule-limit, replica-schedule-limit
store limit 执行下也看下,store limit all 5 修改
老鹰506
(Ti D Ber Uhzt Tfx J)
13
1、从监控上没有看到热点读写,那个点也不是业务高峰期
2、是否节点当时过于繁忙导致的抖动问题 → 从节点CPU、内存,来看没有
3、第三点看了日志发现有如下错误
[ERROR] [distsql.go:1476] ["table reader fetch next chunk failed"] [conn=3516981180] [session_alias=] [error="loadRegion from PD failed, key: \"7480000000000035515F7280000001CA0F977A\", err: rpc error: code = Canceled desc = context canceled"]
但是这个日志问题时间点之前也有,不多,这个时间点连续好几条,不确定和这个有没有关系,目前在排查是不是pd的问题
老鹰506
(Ti D Ber Uhzt Tfx J)
15
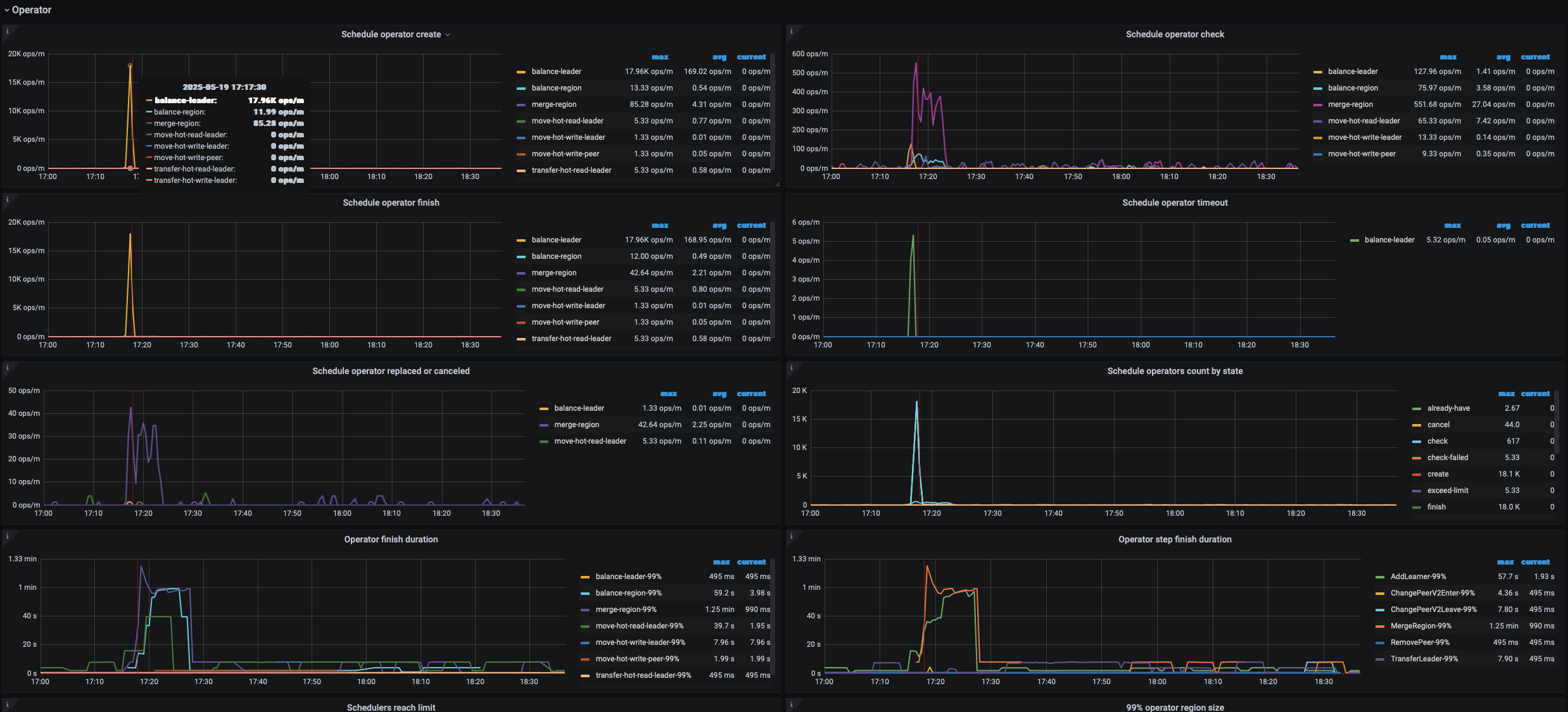
从PD的监控中看到那个点 是在做 ”merge region" 导致发生了Leader的平衡导致的吗?
1 个赞
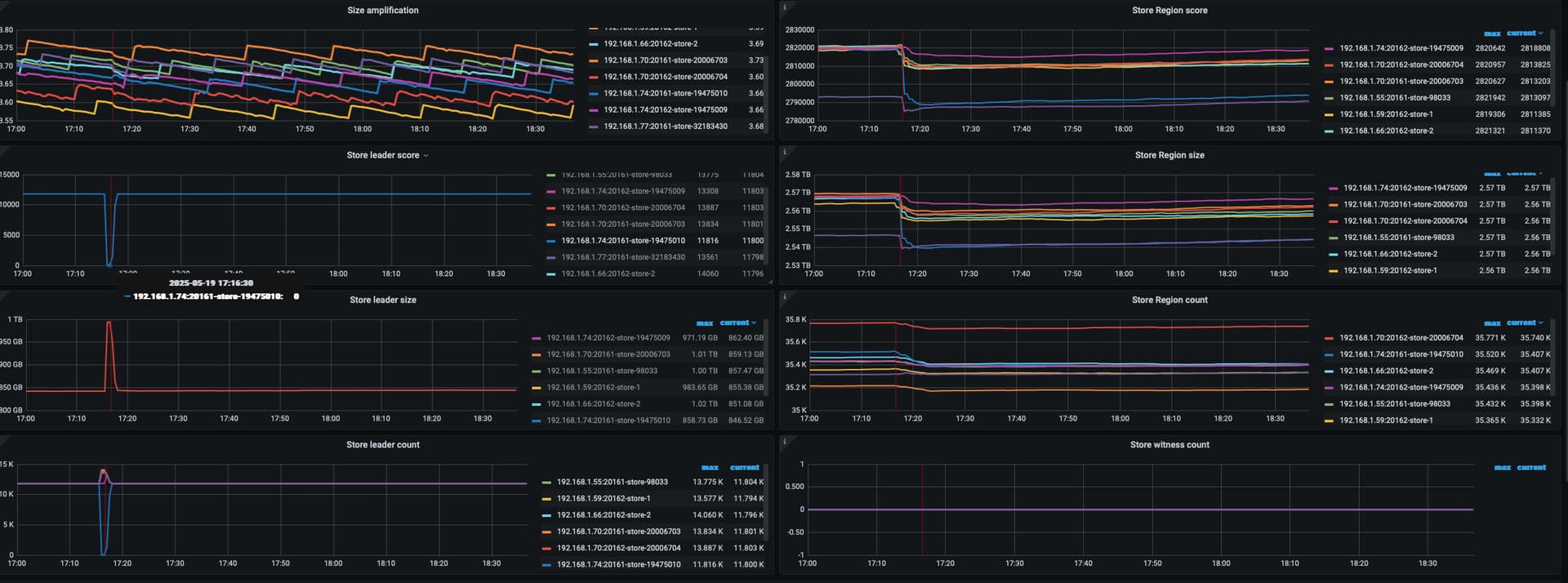
17点16分,是你异常的时间点吗?有个节点leader全掉了
有猫万事足
17
这个一般都是GUI发送的sql,等待时间长主动取消的,也就是直接ctrl+c了。
老鹰506
(Ti D Ber Uhzt Tfx J)
18
是这个时间节点前后, Leader全掉,所以那个Leader score 降到几乎为0了,那这个Leader全掉,2三分钟有好了,一般是什么原因? tikv节点连接pd 网络波动?
看起来 leader 迁移和 slow store 的原因更像是同一个。如果内存资源比较宽裕的话,更多可能是 对应 store IO 的问题。