tidb版本6.1.7
今天中午11点多线上一套集群的一个tikv节点磁盘故障宕机了,然后手动通过–force下线该节点,tiup命令执行成功了,通过tiup display查看到的节点信息也是没有该节点信息了,但是告警一直告警。
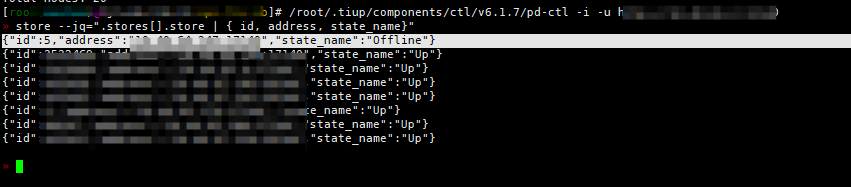
告警信息提示id=5这个节点。(但是看告警时间是11点多的,但是现在都18点了,还一直发告警)
pd信息看到id=5这个节点出于offline状态。(有三个tiflash节点,四个tikv节点)
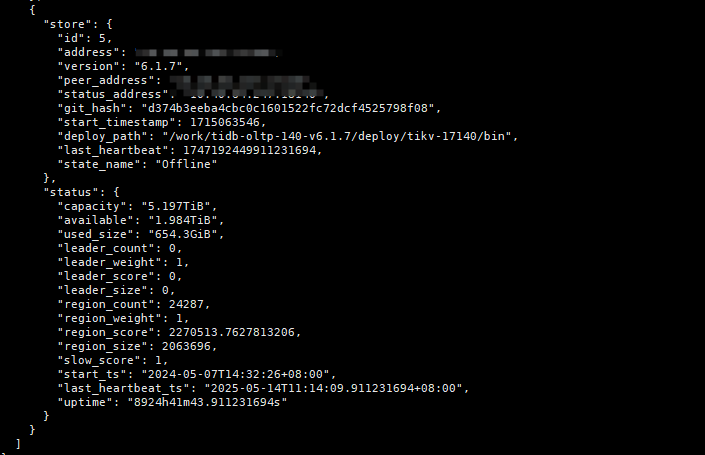
store id=5详细信息
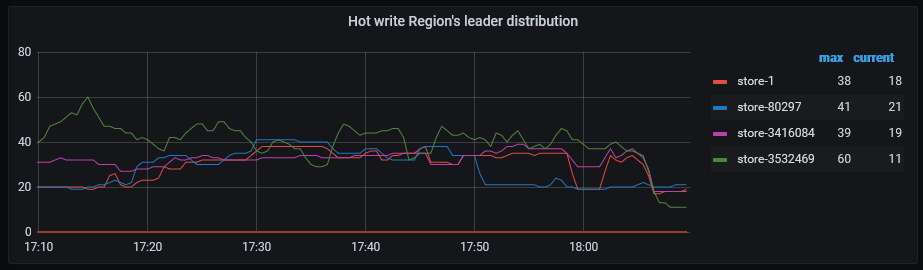
grafana上现存的tikv id
这种情况要怎么处理呢?
强制下线以后已经重启过Prometheus了
进入pd-ctl后id5的store完整信息是怎么样的?
grafana pd监控region count还有没有store 5的信息的了
没有了,帖子里面有贴
pd-ctl中显示store 5region count还有两万多个,这部分region迁移走,pd-ctl信息会自动清理。 目前迁移速度较慢,可以尝试调大参数加快迁移速度: config set replica-schedule-limit config set max-snapshot-count config set max-pending-peer-count config set region-schedule-limit
https://docs.pingcap.com/zh/tidb/stable/pd-scheduling-best-practices/#节点下线速度慢
去 PD 看下 region 调度情况,副本都补完后,这个节点会变成 tomestore