【TiDB 使用环境】使用裸kv
理论上该错误可以不例理会,PD更新region meta后客户端会自动重试,但是发生故障时,pd侧长时间未更新相关region的version信息.
PD未及时打印region version changed日志,TIKV代码中region分裂后会马上通知pd最新的region信息,pd会打印region version changed
split完成和心跳间隔时间非常长,故障时间经过pd-ctl region的方式验证,实际PD中的region version也远远长期落后于TIKV
【其他附件:截图/日志/监控】
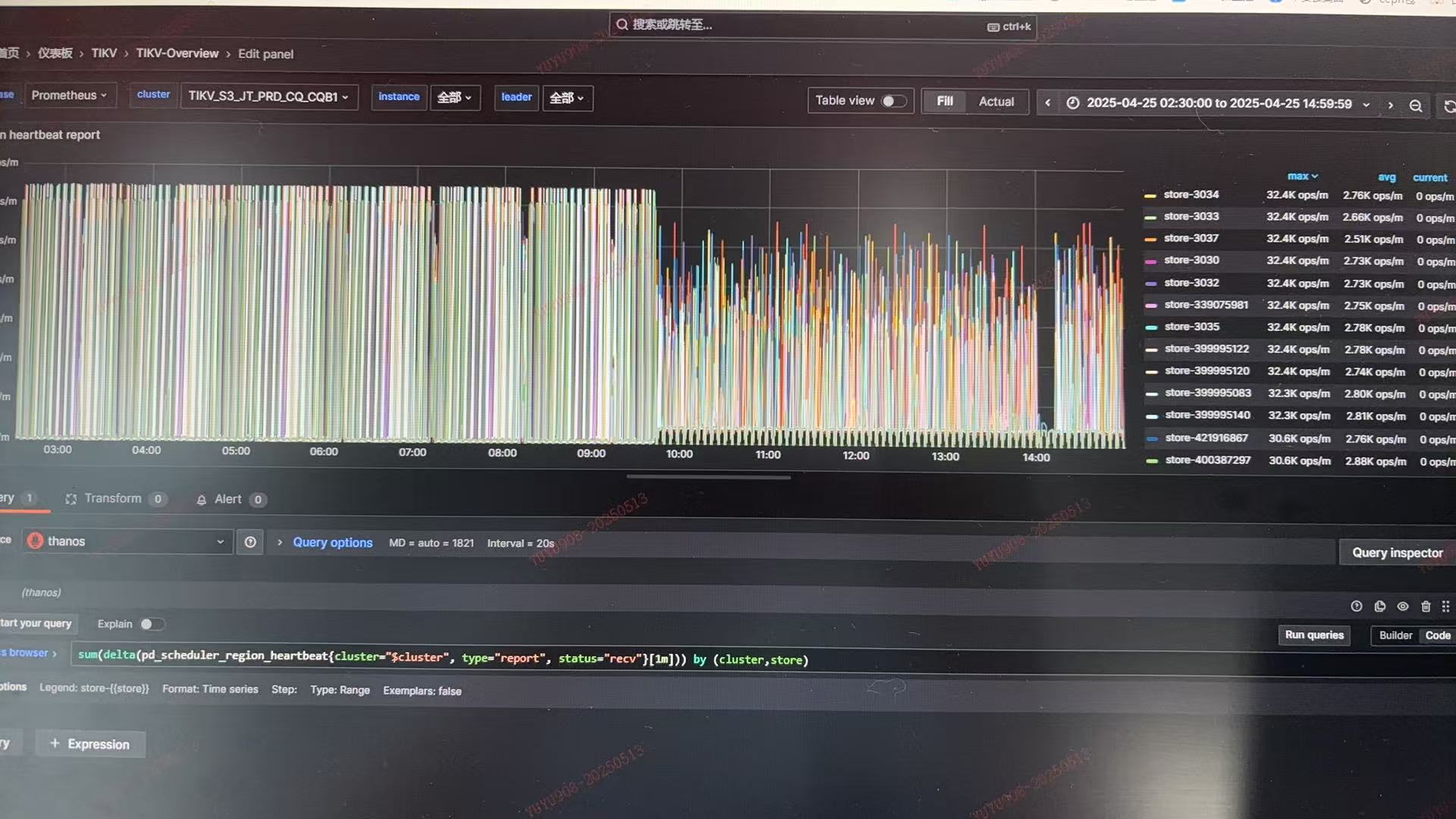
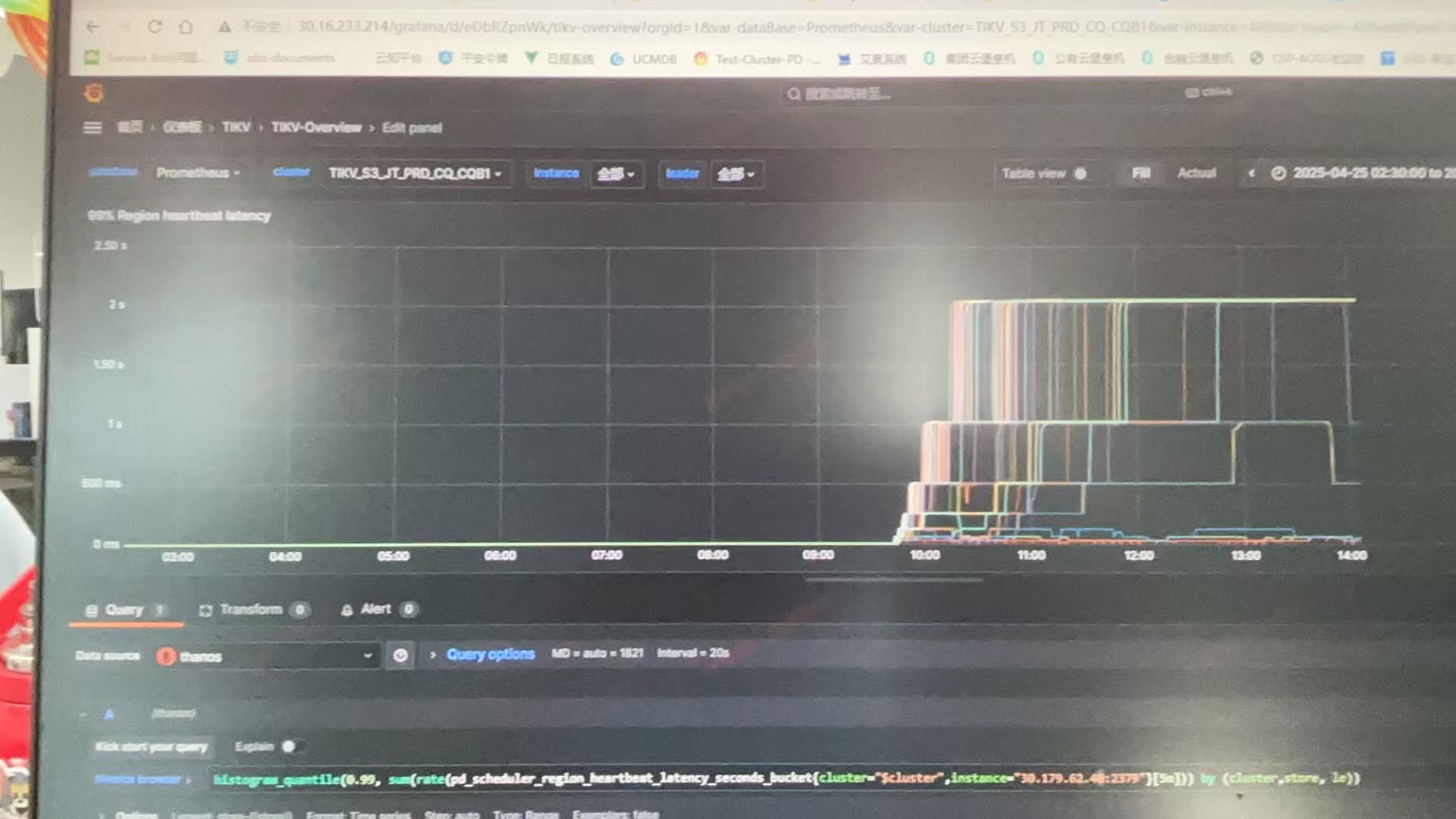
region heart beat p99时延
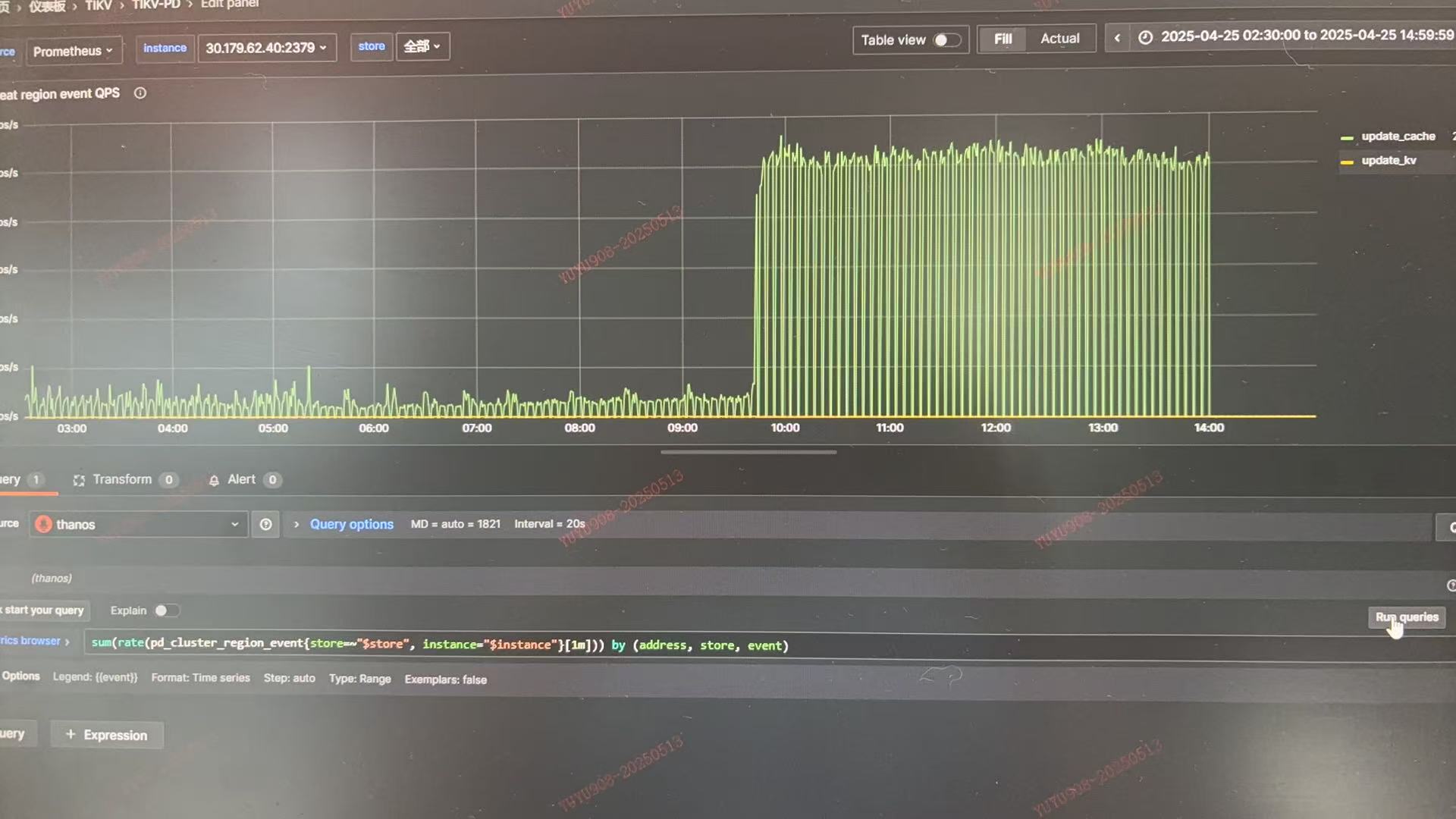
region heart beat event update cache 突增
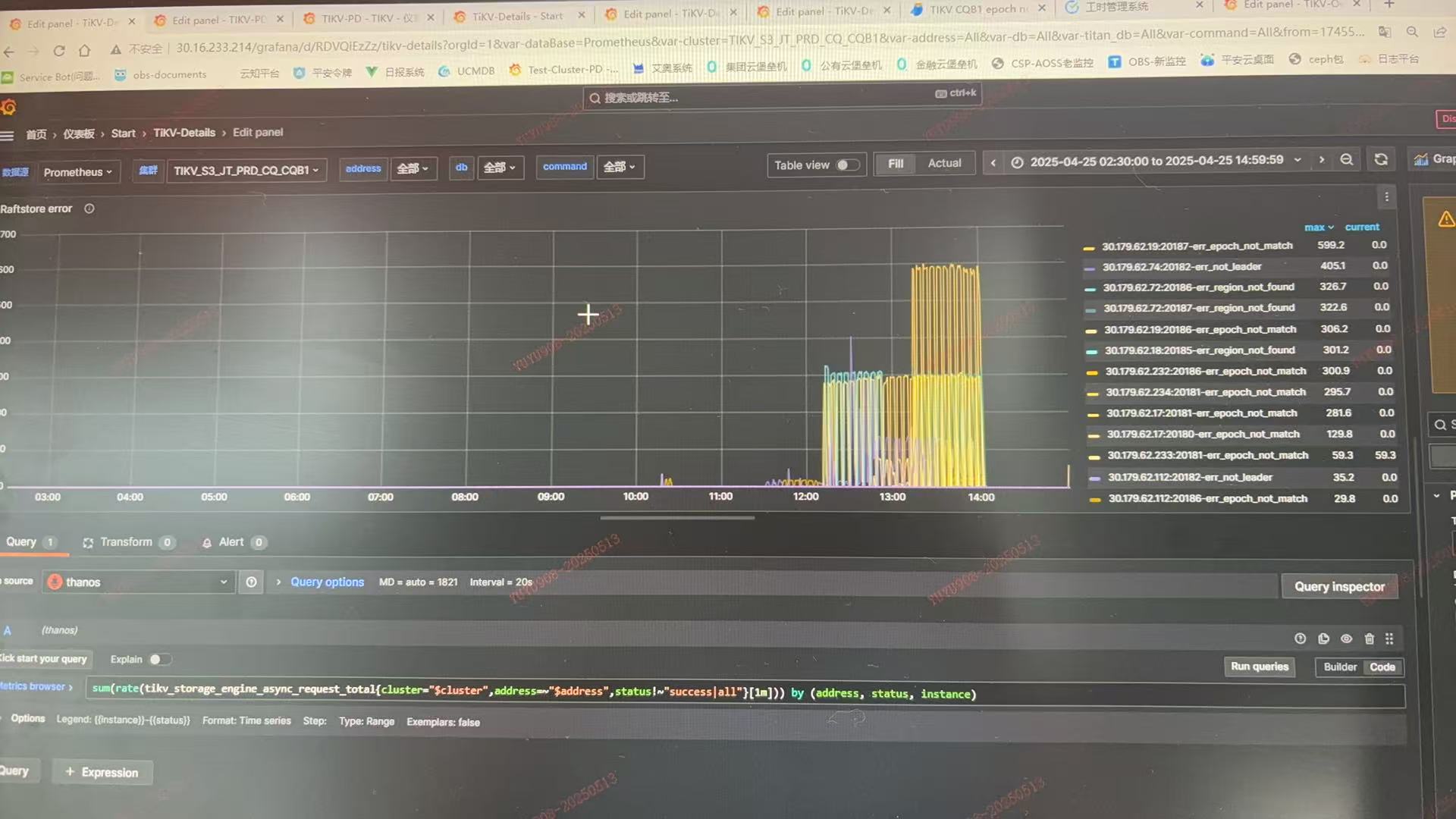
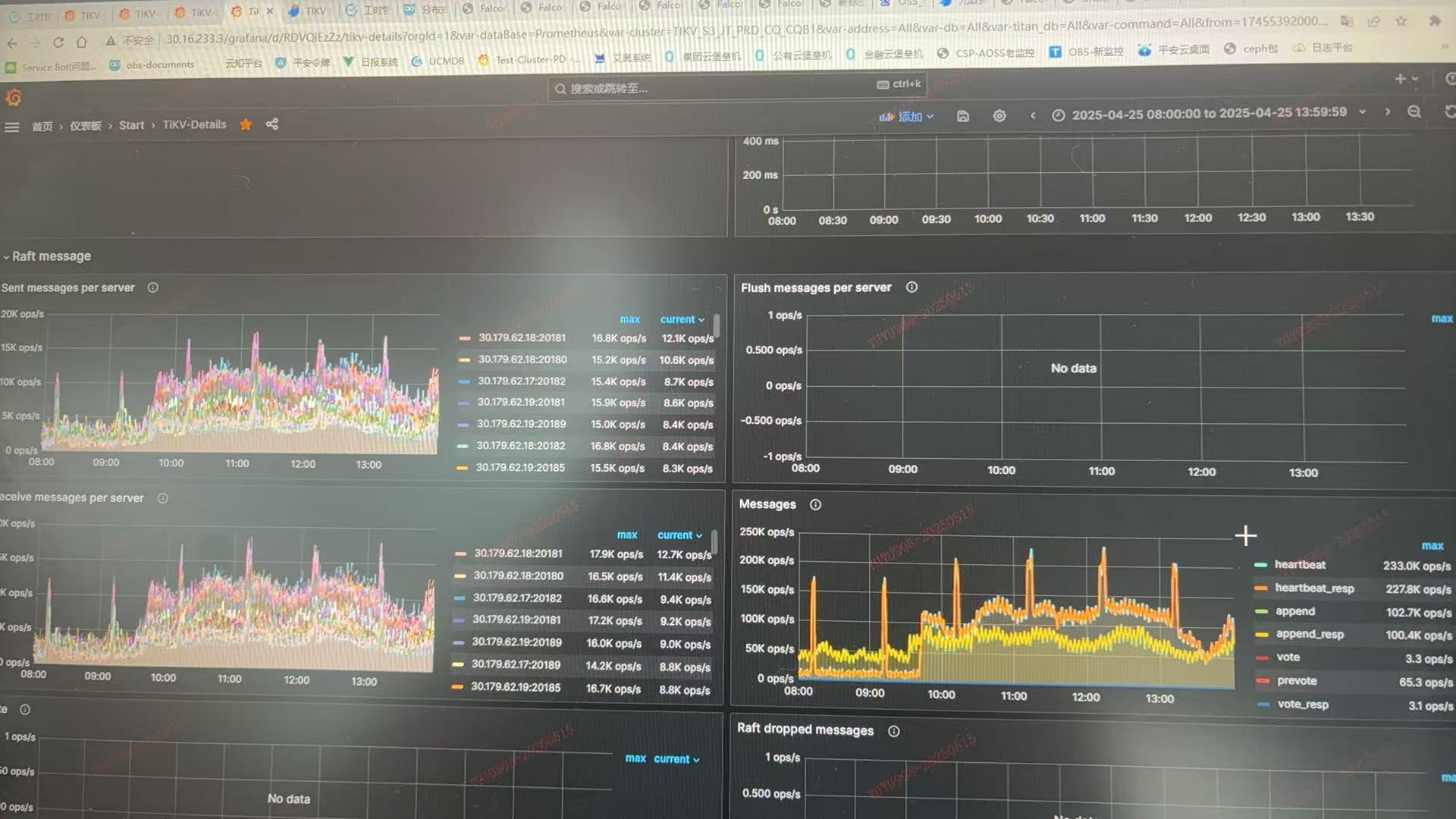
tikv raftstore报错
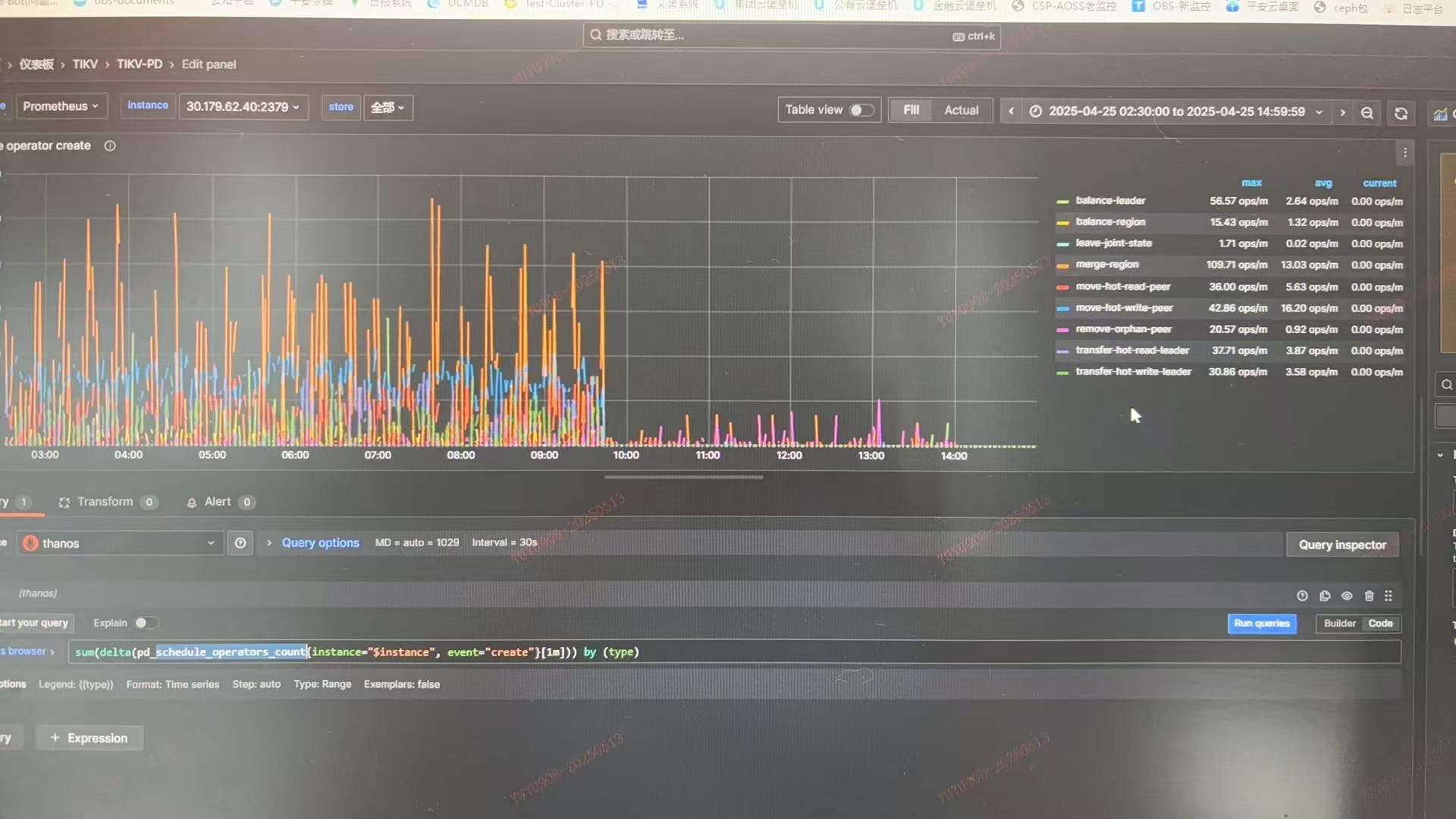
集群开启hibernate region,raftstore 线程为4,但从raftstore cpu来看,压力不大.异常时,PD调度骤降
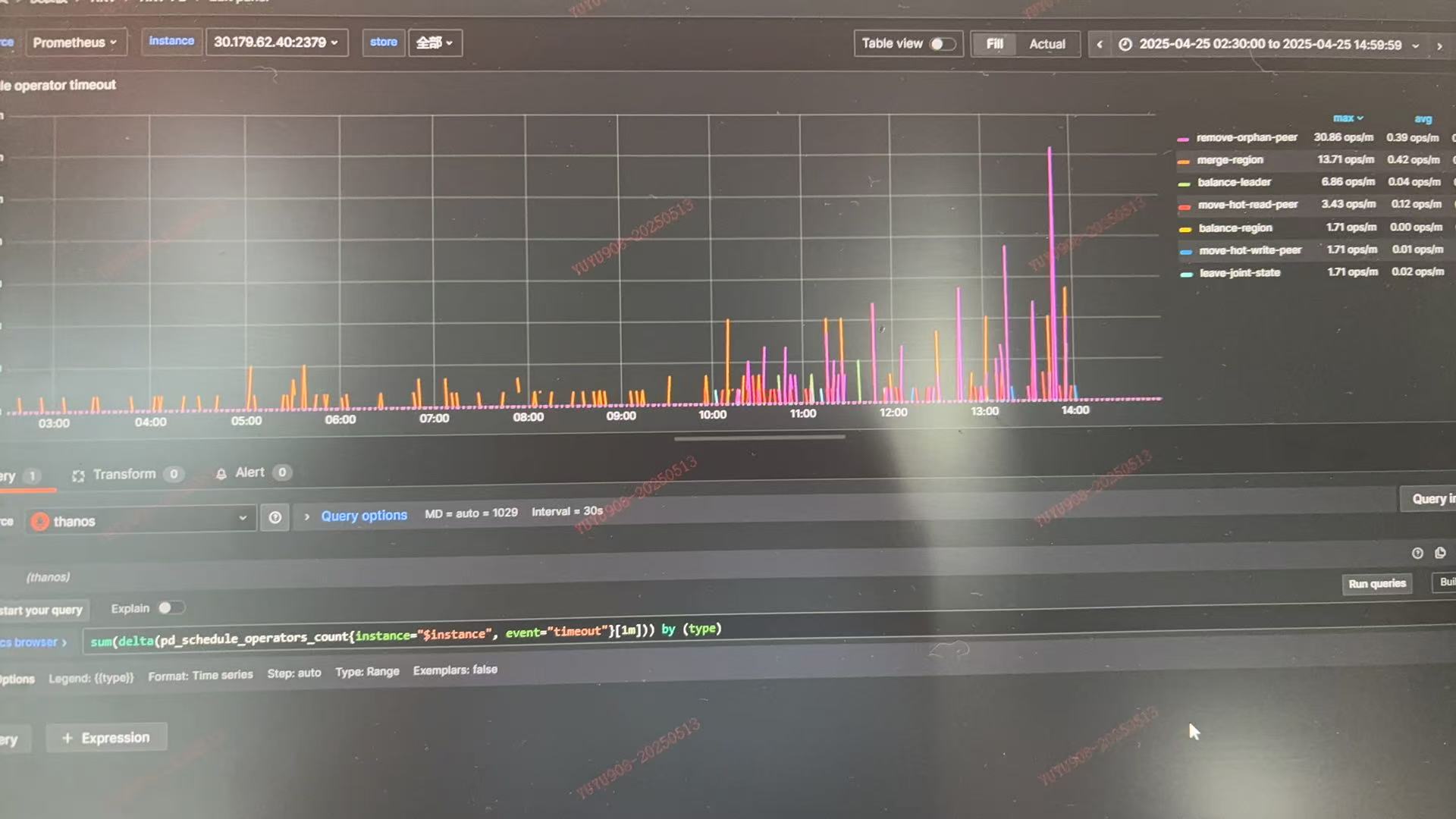
调度超时增多
求各位大神帮忙看看,从现象来分析是因为心跳问题导致的PD侧region meta没有更新,但是无法得出是TIKV繁忙(发送端)的问题还是PD压力太大(接受端)的问题?
(生产中我们使用不太优雅的规避方法:在故障时候通过PD transfer leader,可以快速更新最新的region meta.)
1 个赞
看看pd的log。看看有什么报错么。看看tikv到pd的网络,pd的cpu使用率这些
舞动梦灵
2025 年5 月 14 日 01:44
3
我想当的也是,切换PD。还是看看PD日志有什么内容。每个节点region数量多少。是不是太多了
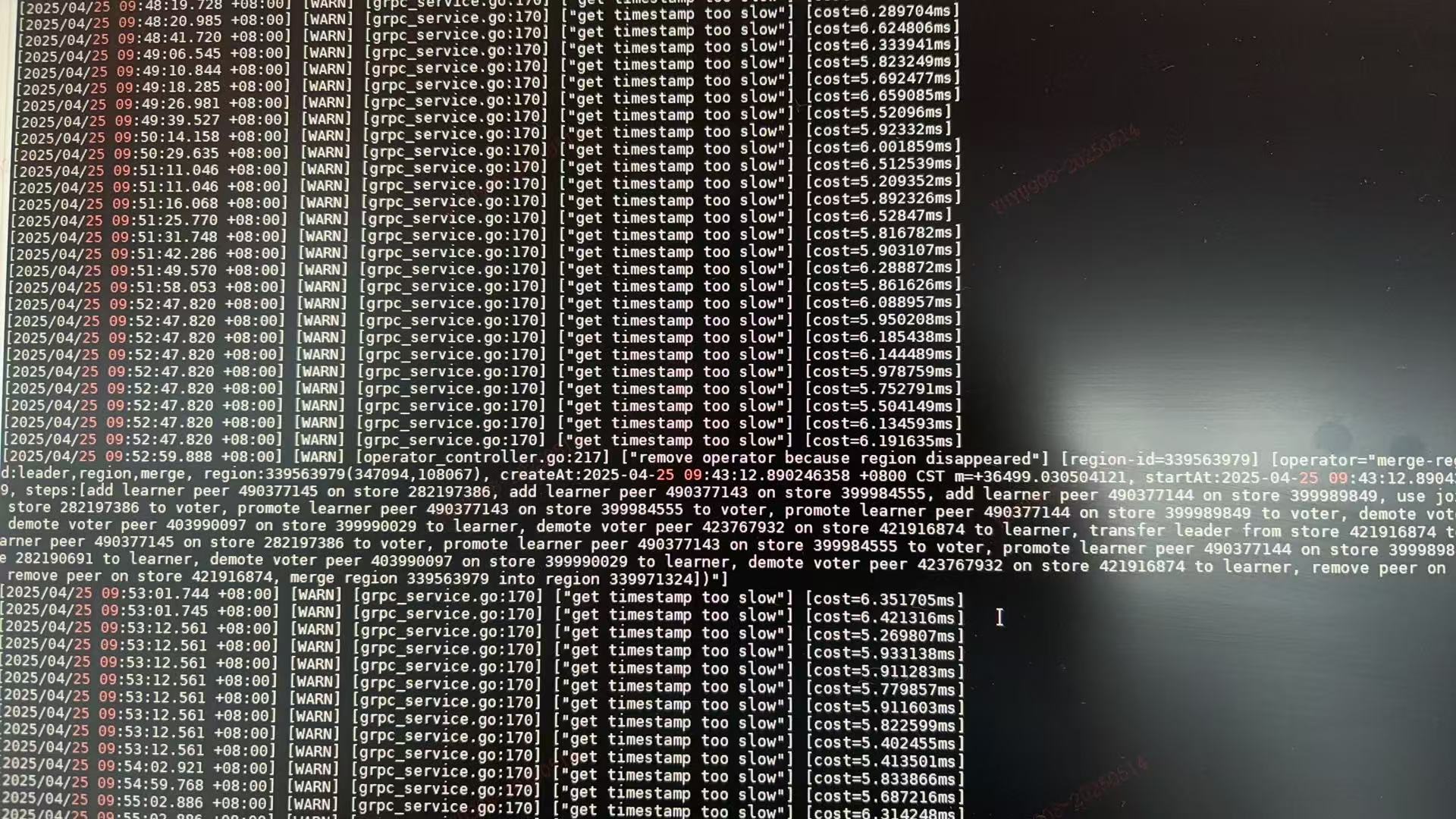
pd侧日志没有明显的ERROR,只有一些WARNING
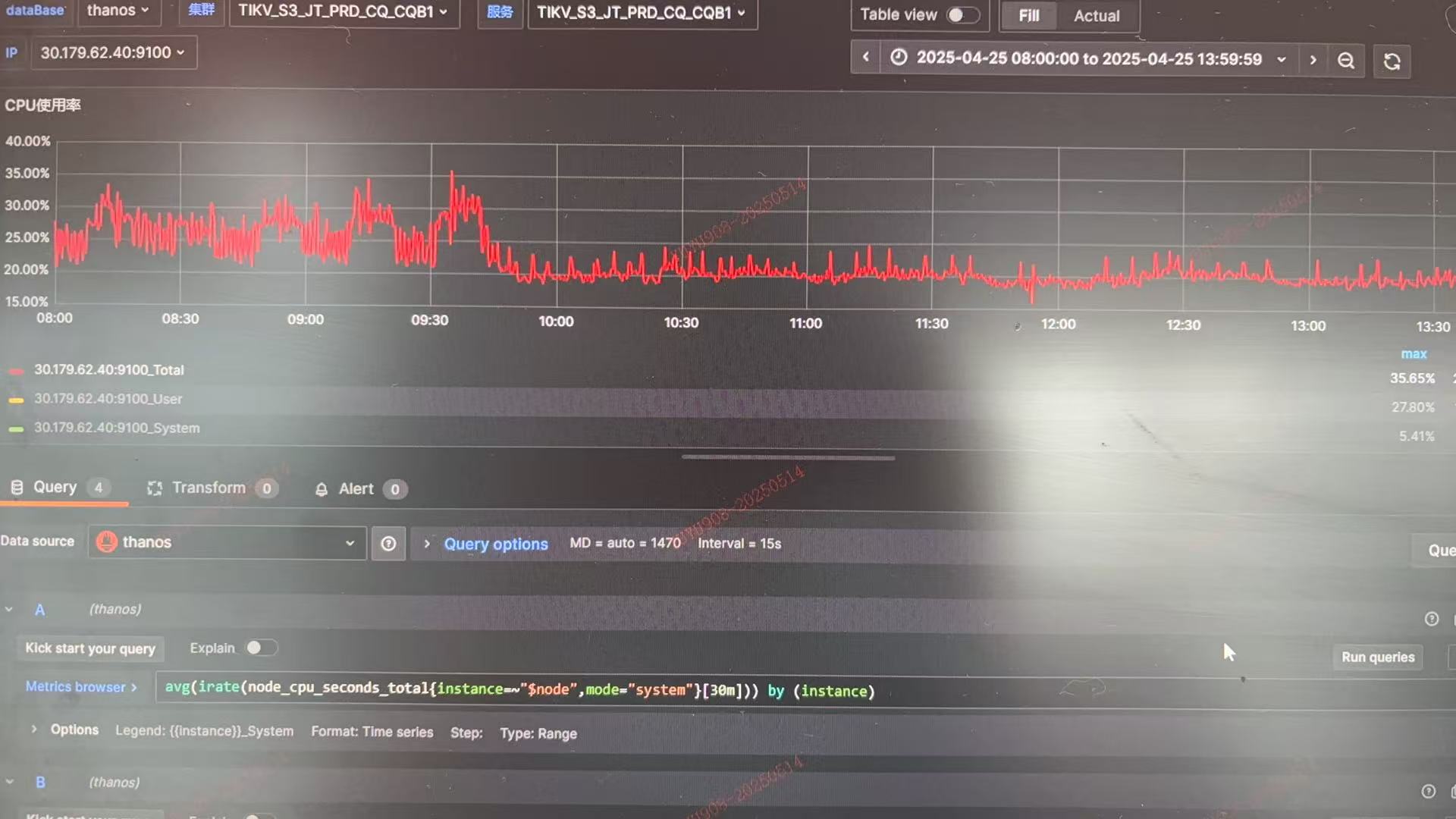
PD CPU占用故障时反而有所降低(PD单独部署,38逻辑核)
1 个赞
那看看网络延迟情况?看看tikv的cpu。这个确实比较难排查
1 个赞
tikv有单个store上region数量的推荐值吗,我们生产是异构盘,部分机器3.2T,部分机器1.6T,region weight相应设置的2:1,最大的store上大概有8W+个region的peer,但是heart beat心跳只有leader才发,实际上可能就3W左右的leader吧.
逍遥_猫
2025 年5 月 14 日 02:56
7
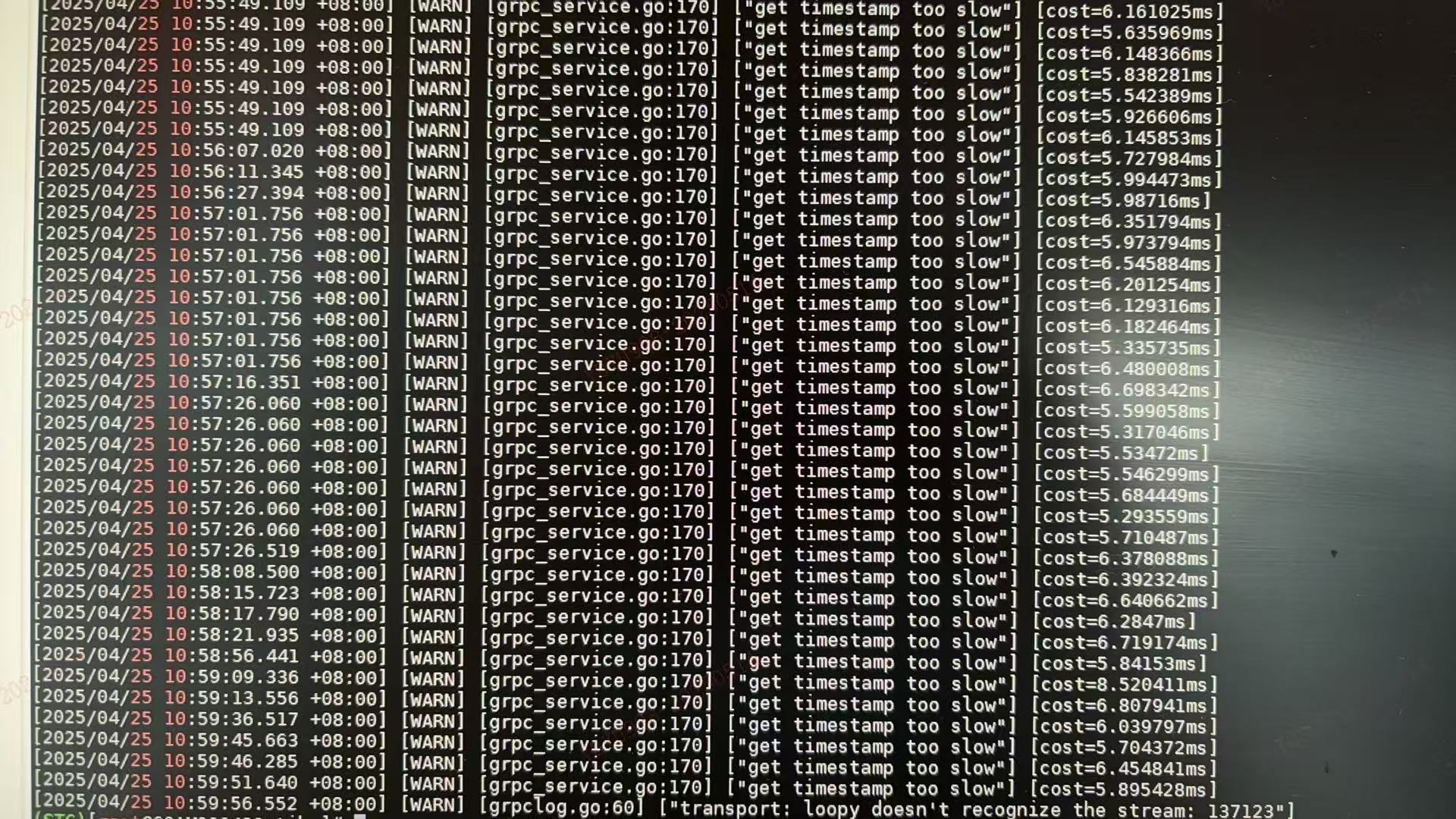
region太多了。。看日志 get timestamp too slow ,是不是太多了引起的?一直这么多么?以前正常么?
舞动梦灵
2025 年5 月 14 日 03:06
8
还好吧,我现在生产。leader是2w左右。peer是6万。没有这个情况
这个too slow倒是一直都在WARNING,从时间来看的话也都是5-15ms不等,故障时间这个没有明显升高.有没有推荐或者指导单个集群的region数和单个store的region数量呢,我们也在考虑通过限制集群规格的方法避免出现一些因为量太大导致的稳定性问题.
有猫万事足
2025 年5 月 14 日 06:23
10
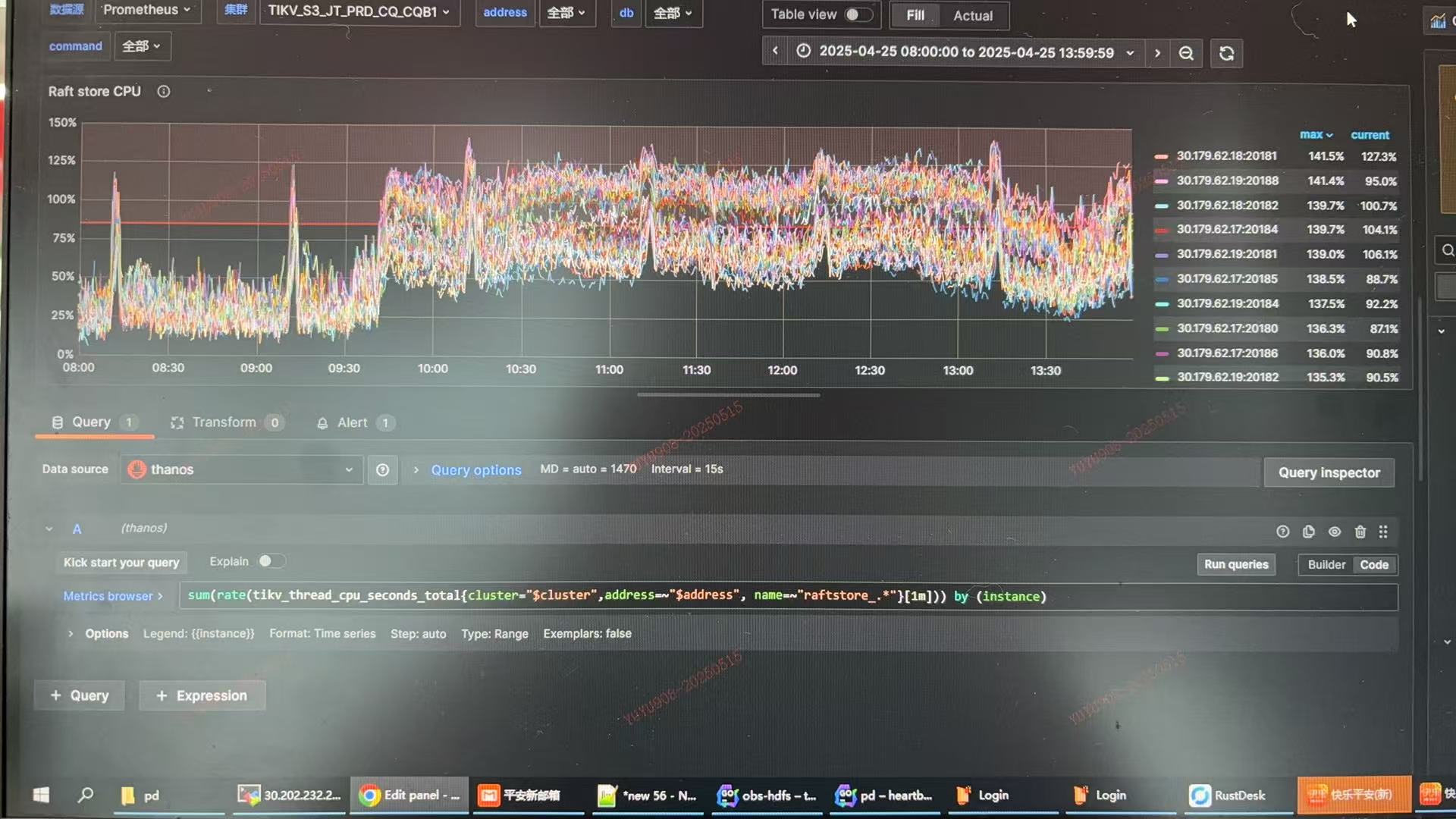
raftstore apply pool/store pool都设置的4,故障时间raft cpu占用
从CPU的角度来看也不算忙
raft io时延
raft mesages
已经开启过hibernate,region base tick暂时没有调整
有猫万事足
2025 年5 月 15 日 14:19
12
https://docs.pingcap.com/zh/tidb/stable/massive-regions-best-practices/#方法七提高-raft-通信的的最大连接数
grpc-raft-conn-num这个调整过嘛?
TiDBer_K1p4DIbW:
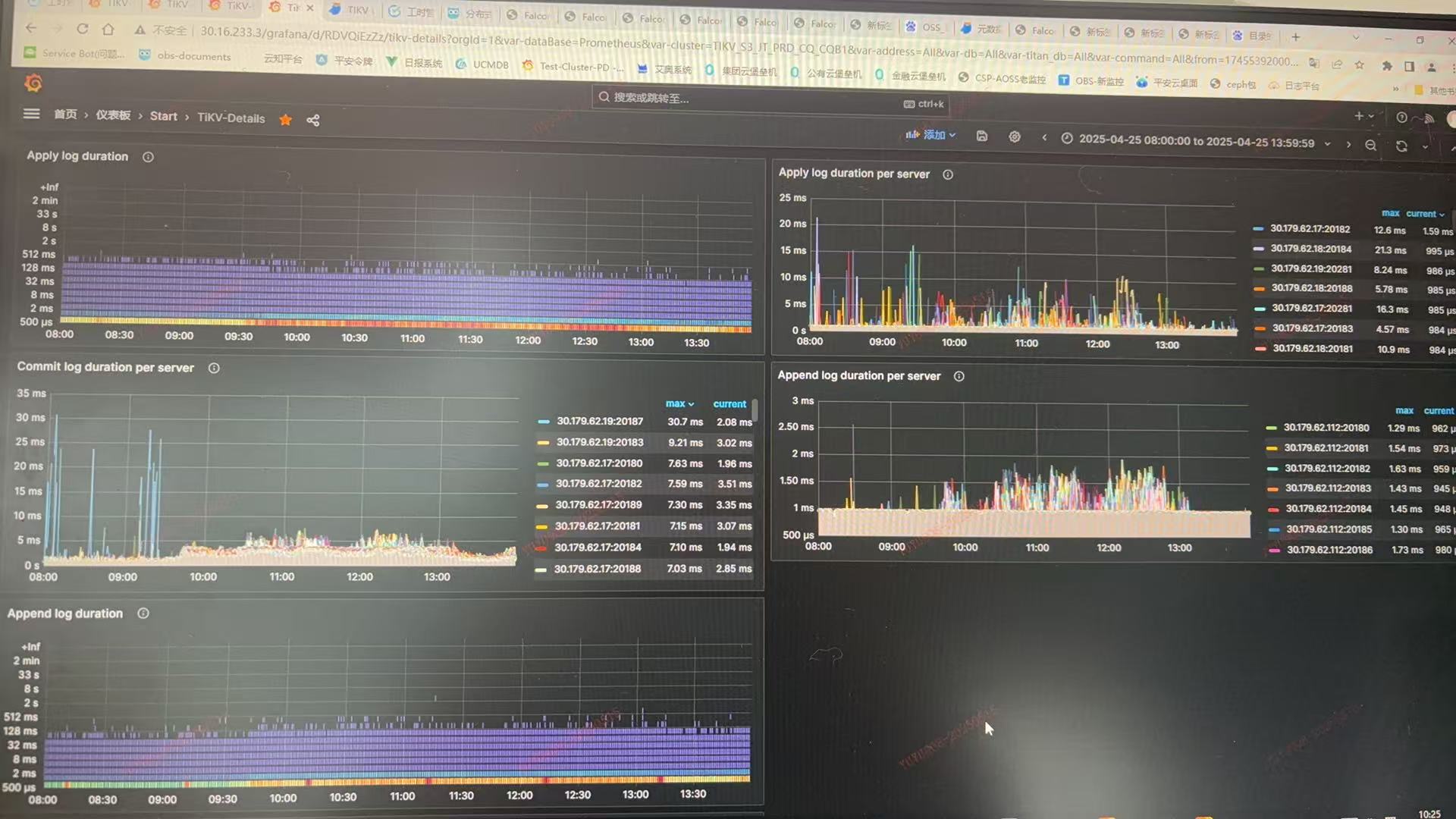
这个图看着确实不高,但是下面几个起码故障时间段内 ops/s上涨的确实厉害。
TiDBer_K1p4DIbW:
可能是通信上卡了。起码pd cpu和raft-store cpu看着都不像有问题。
调整过了,grpc-raft-conn-num当前为4
1 个赞