【TiDB 使用环境】生产环境
【TiDB 版本】8.5.0
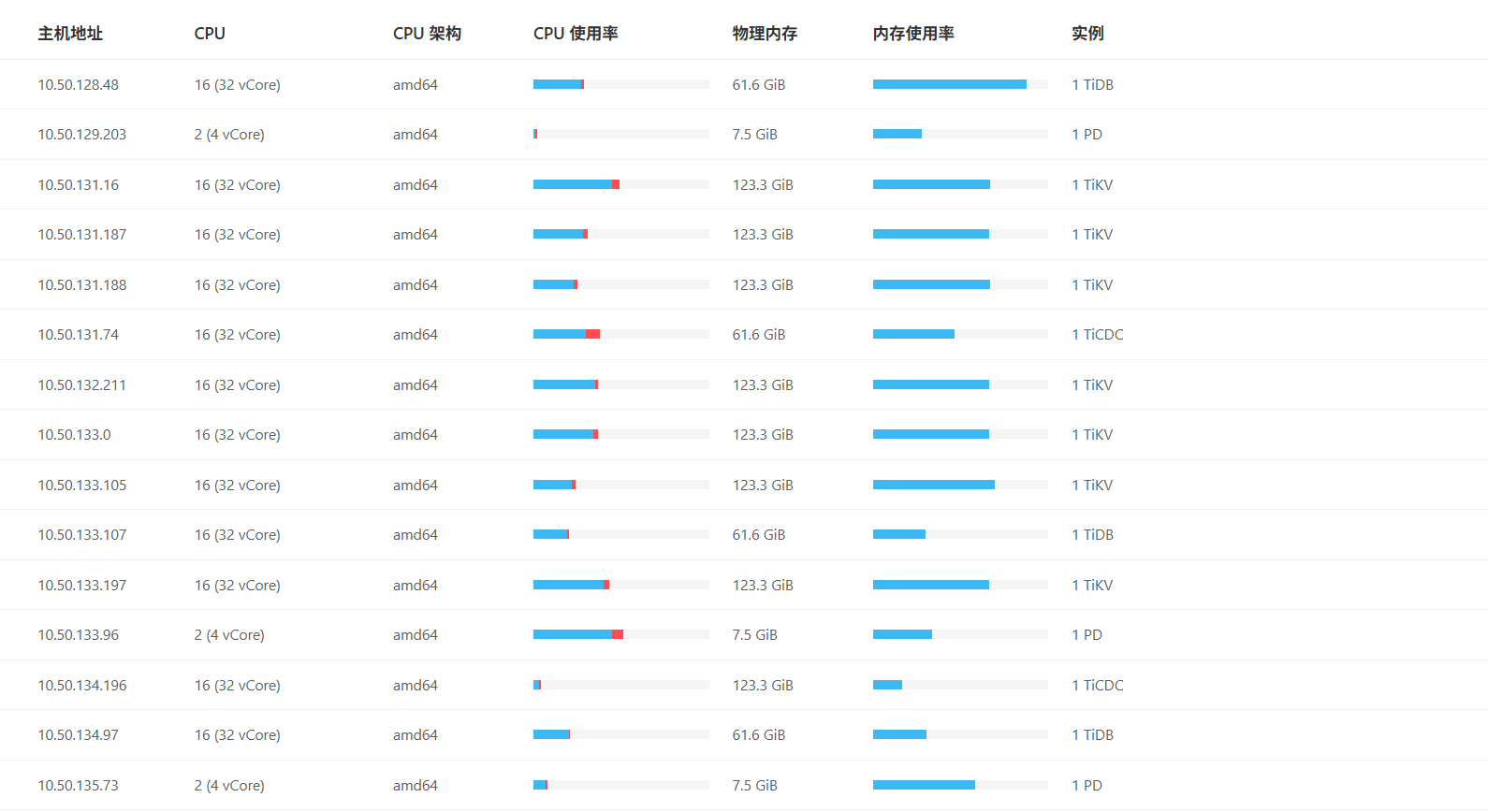
【操作系统】centos 32c64G
【部署方式】云上部署
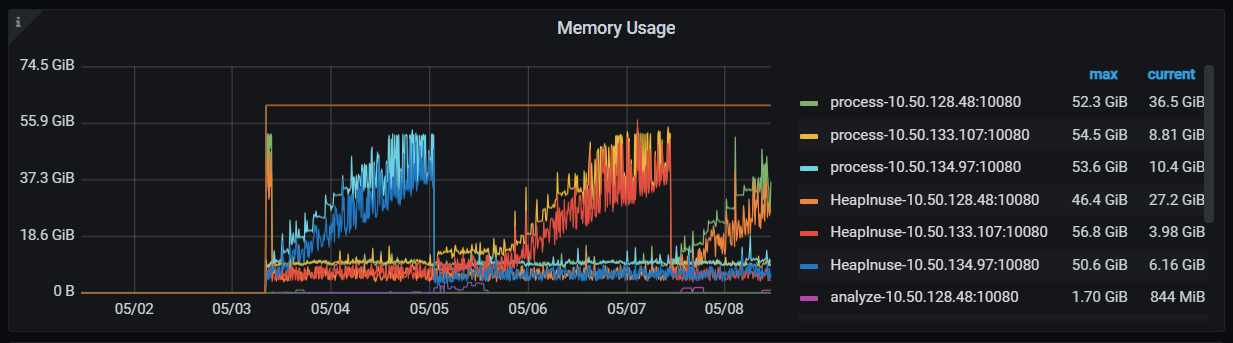
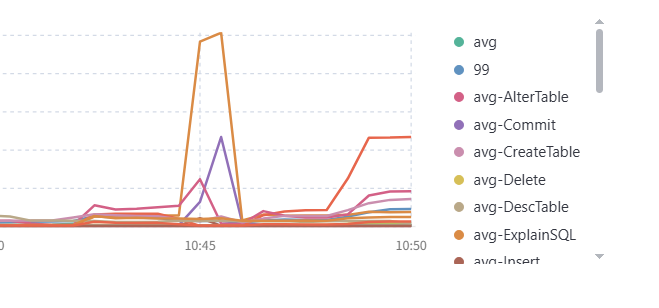
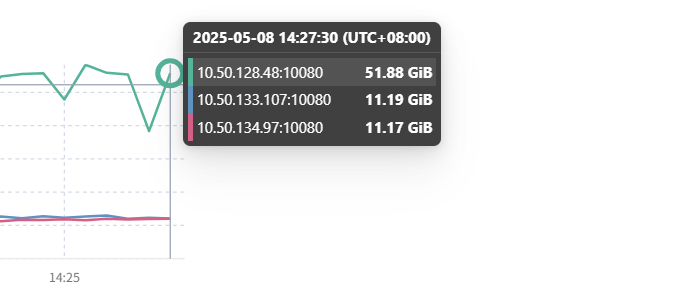
间歇性oom
请问下大家 这个heaplnuse 有什么参数作为限制吗 ,目前系统大页这些参数均设置
【TiDB 使用环境】生产环境
【TiDB 版本】8.5.0
【操作系统】centos 32c64G
【部署方式】云上部署
间歇性oom
请问下大家 这个heaplnuse 有什么参数作为限制吗 ,目前系统大页这些参数均设置
这种先从sql入手,看看有没有慢查询需要处理
dashboard的慢查询里拿一下具体的慢sql,看看能不能优化
你这图没有截全,是多长时间就 OOM 了
更新了大佬 帮忙看看
跑两天oom了么。tidb是单独的机器还是混部的,建议你参考 https://docs.pingcap.com/zh/tidb/stable/troubleshoot-tidb-oom/#tidb-oom-故障排查 和 https://docs.pingcap.com/zh/tidb/stable/configure-memory-usage/
heaplnuse属于底层golang堆内存消耗,优化限制应该还是在tidb层处理
单机部署的 没有混布
升级为 v8.5.1
v8.5.0 这个版本不支持 centos 7 不太确定是不是这个原因导致的,你升级一下看看。
show config where name like ‘%storage.block-cache.capacity%’
这个参数设置的多少啊,设置合理不应该会oom的
tikv没问题噢 这是tidb节点oom
看着怎么像是内存有泄漏了
同感 哥们有办法吗
看看应用侧的内存使用量也是这样增长的吗
业务端的服务 内存也是持续上升的 是不是被业务端牵制了
如果应用侧连接一直没释放可能会导致,可以排查下应用侧。
但应用侧早上重启过 内存也是没释放
会不会和每天的br备份任务有关系?