【 TiDB 使用环境】生产环境
【 TiDB 版本】8.5.1
【复现路径】最近出现一次,在执行大数据量读写,批量行数1000万左右,会出现问题
【遇到的问题:问题现象及影响】
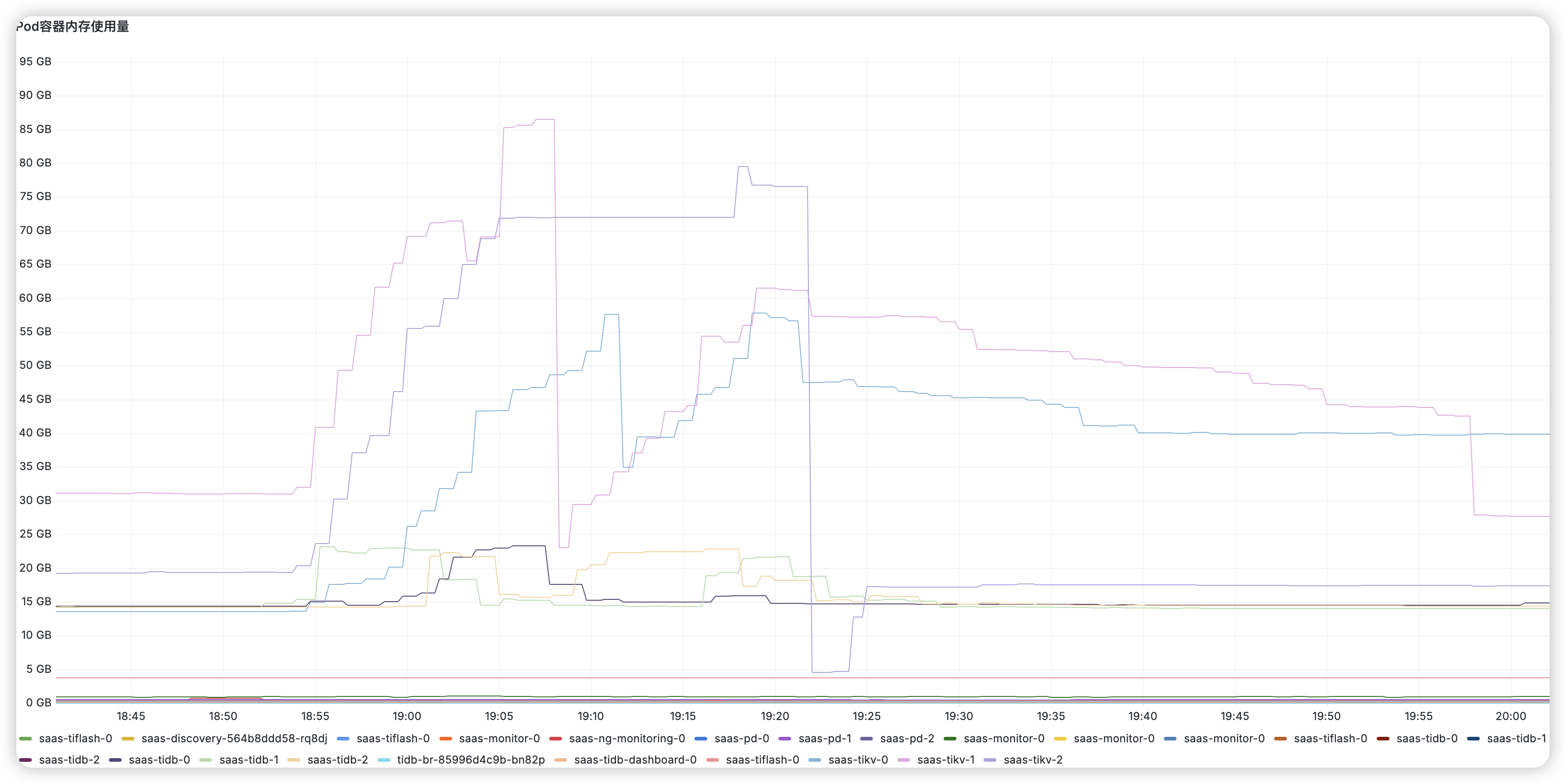
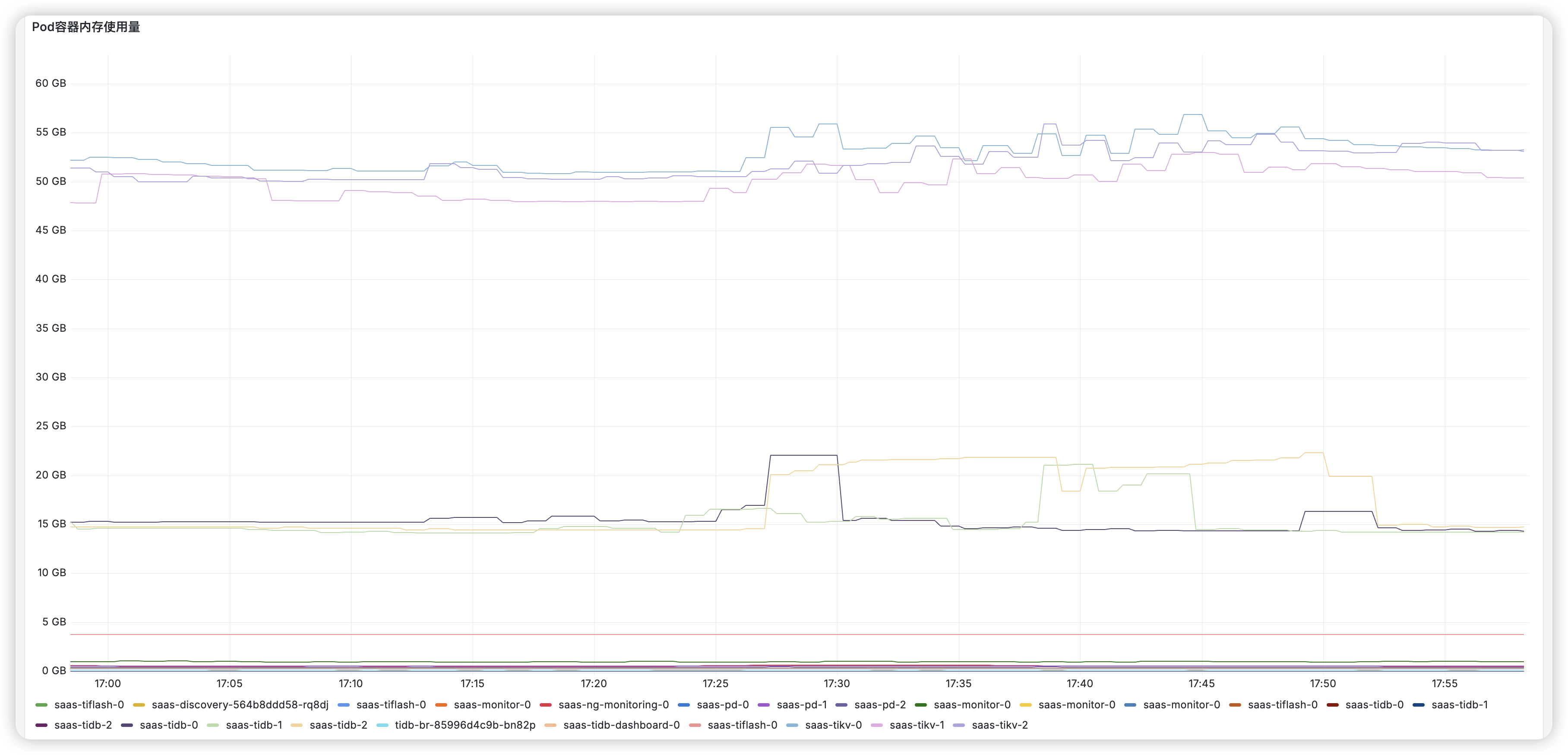
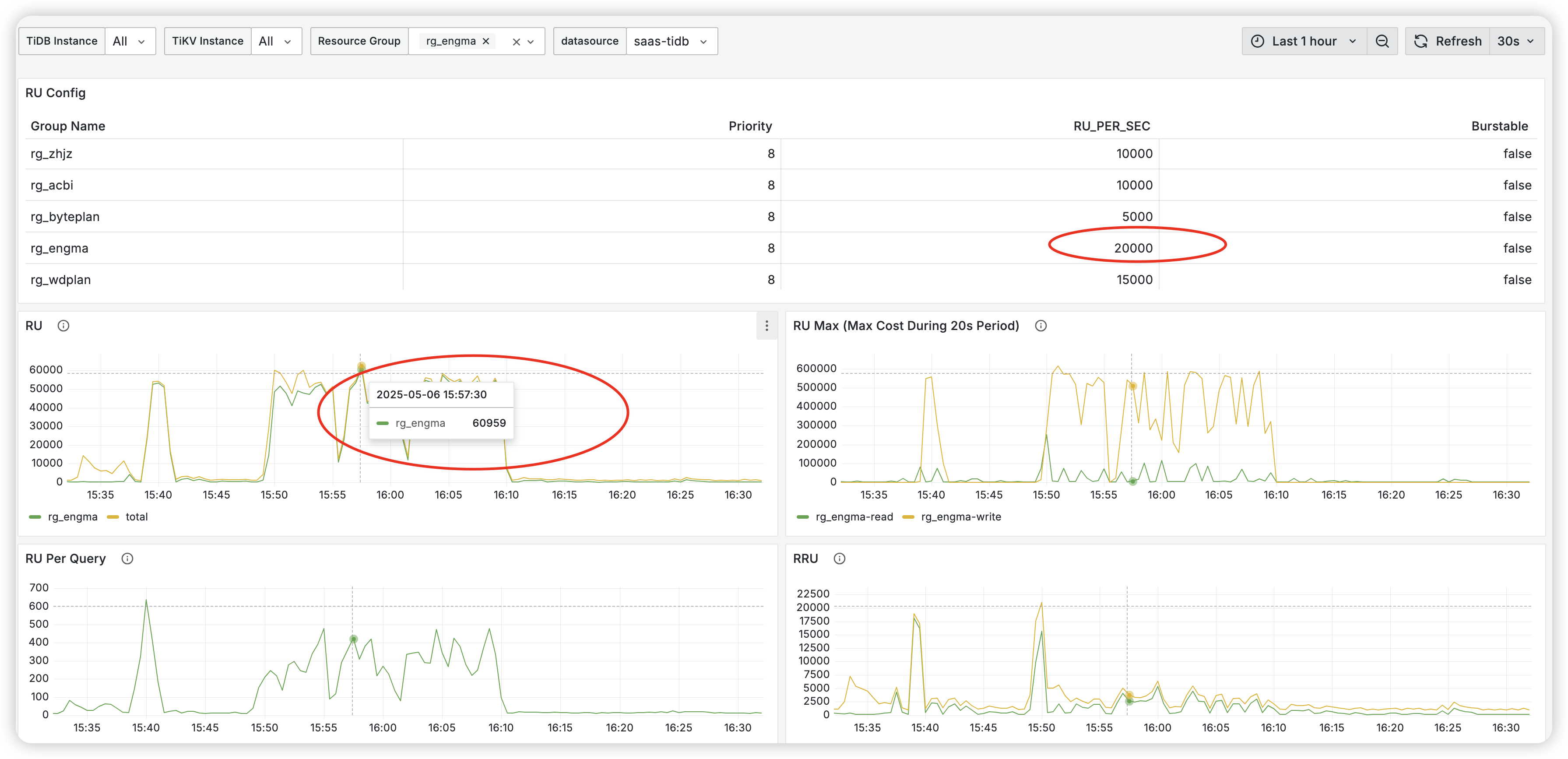
资源组限制为20000,实际监控显示超过60000,导致tikv内存使用超过上限,tikv节点陆续重启,如下图资源组监控:
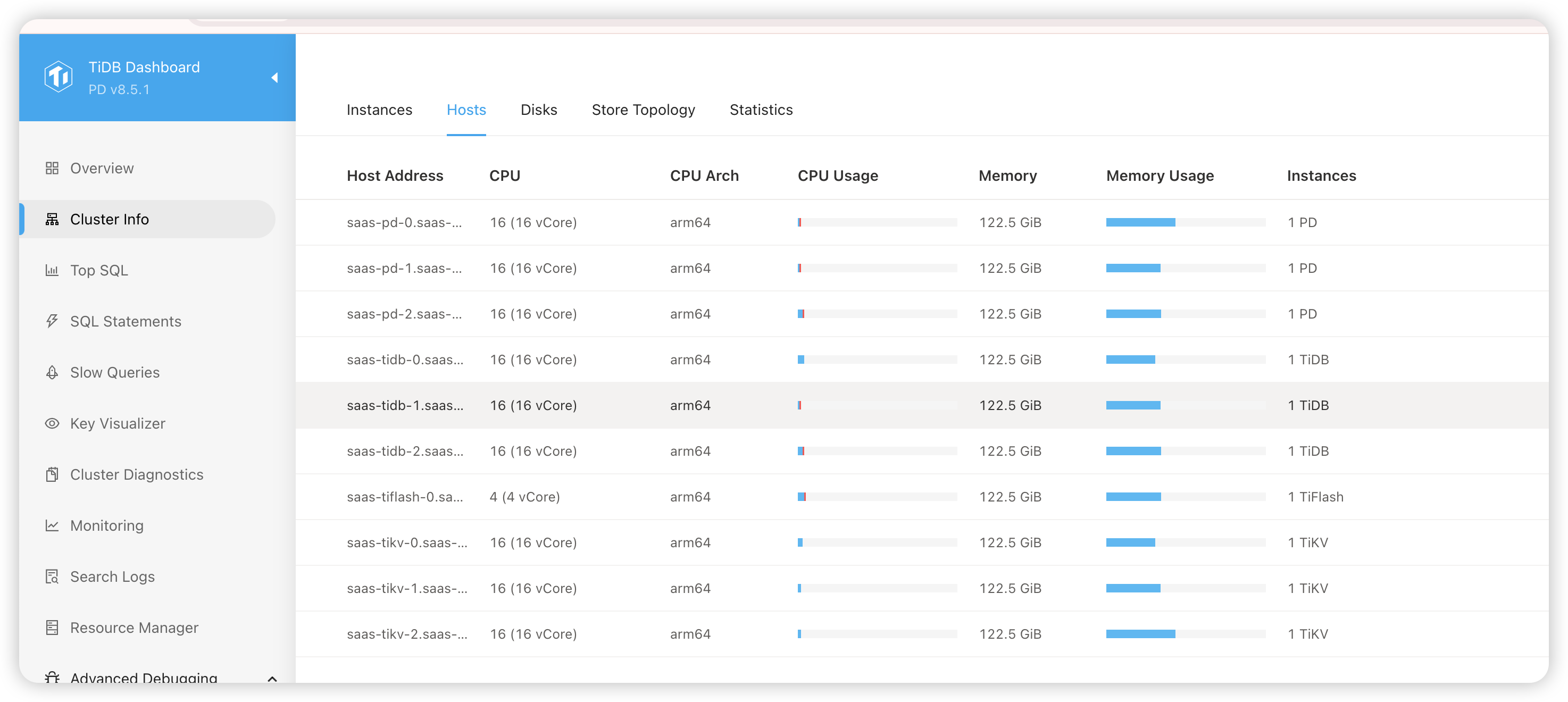
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
【 TiDB 使用环境】生产环境
【 TiDB 版本】8.5.1
【复现路径】最近出现一次,在执行大数据量读写,批量行数1000万左右,会出现问题
【遇到的问题:问题现象及影响】
资源组限制为20000,实际监控显示超过60000,导致tikv内存使用超过上限,tikv节点陆续重启,如下图资源组监控:
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
设置资源组不是立刻生效。需要重建连接。如果之前老的连接还连在上面,直接跑的话是限制不住的。
重新连接下吧,新的连接才会生效。
新建立的连接才会生效
这个集群的资源组设置很久了,不是最近改的,最近一次重启是接近3个月之前,那个时候资源组的设置就是这样了,最近也没改过资源组配置,挺奇怪的,我试试重启tidb节点吧
RU 没有限制住和 OOM 应该关系不大。
tikv 一般有缓存和内存回收的,一般不 OOM,你内存限制做了么?这个集群是 k8s 部署还是怎么部署的?
在k8s部署的,之前ru的限制应该是生效的,同样的业务确实可以限制ru上限,资源使用也比较平缓
show config where name like '%block-cache.%' and type="tikv";
登录上去 查下这个内容。
tikv 设置的 limit 是 72GB?那看起来配置预期的。我估计你 OOM 问题还是 tikv 有内存相关溢出。。。。
看过监控么?tikv 内存是缓慢上升的 还是当时突然上升的。最好是能抓下火焰图。
发现一个问题,tikv的内存释放应该需要一段时间,不能很快释放,如果有大sql连续的执行,就会导致内存一直涨,最后oom。
我们测试了一个批量sql,同样的数据,单次执行大概会使用20%左右的内存,如果连续运行这个批量,5-6次以后,就会导致tikv内存溢出,
这个blockcache是一块使用LRU算法的缓存。所以你改小了内存也不会立刻掉下来,等到一定时间没有访问/没有使用的内存才是值得释放的。立刻释放的话,很可能把还要用的内存释放掉了,一访问到了,还要加载回来,同样是内存没降。
调整blockcache以后,内存确实是缓缓下降的,一般set config调一次,可以20-30分钟后在观察是否有效果。
其实还是blockcache设置的大了,狠狠往下压,能控制住的。
另外这个批量sql如果是写入,writebuffer也占内存,你本来读请求用的blockcache可能是看上去是够的,加上writebuffer就不够了。
总之,先大刀阔斧的把blockcache往下压,我的经验是tikv能控制住的。
你现在觉得tikv内存控制难,以后,tidb和tiflash内存都比tikv的难压。 ![]()
我之前也问过类似问题,一位叫@asmile的老哥,告诉我的:
RU是速率的限制,即每秒回填速度,这里设置的是每秒可用最大为2万,你这个sql执行,是统计的当时一段时间的RU总数;即你执行完这条sql,超过2万,是正常的;最好看下平均RU;其次,RU限制应该是限制不了内存的。专栏 - 新特性解析丨TiDB 资源管控的设计思路与场景解析 | TiDB 社区…_ga_D02DELFW09czE3NTAzODU0MzEkbzE3JGcxJHQxNzUwMzg2NTAzJGo0MiRsMCRoMA…
另外这个也值得看看,特定版本的glibc,在内存管理上是有问题的。
非常感谢指导!
目前这个场景,降block cache确实很有用,block cache从32G降到20G,降了12G,省出来12G近17%的空余内存,tikv内存峰值一下子平缓了不少,效果很明显
看官方说明,确实不支持内存控制,不过同样的sql计算场景,我们的集群上之前有一段时间确实有效果,没有出现过tikv OOM,rg监控上也能看出来有限流的效果,应该是8.5.1之后限流效果没了,然后tikv开始不断的出现oom
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。