【 TiDB 使用环境】生产环境
【 TiDB 版本】 V 6.1.5
【遇到的问题:问题现象及影响】
Tidb内置altermanager 突然持续告警,报警信息:tidb、pd角色重启
但是登录查看进程信息发现并没有重启。
持续报警:
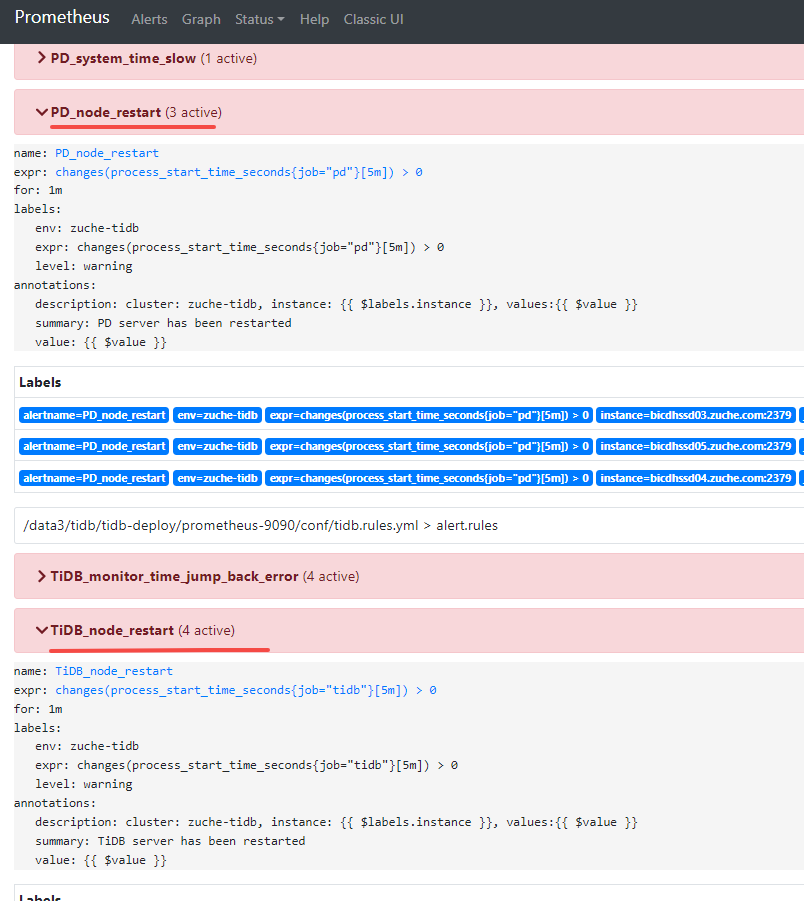
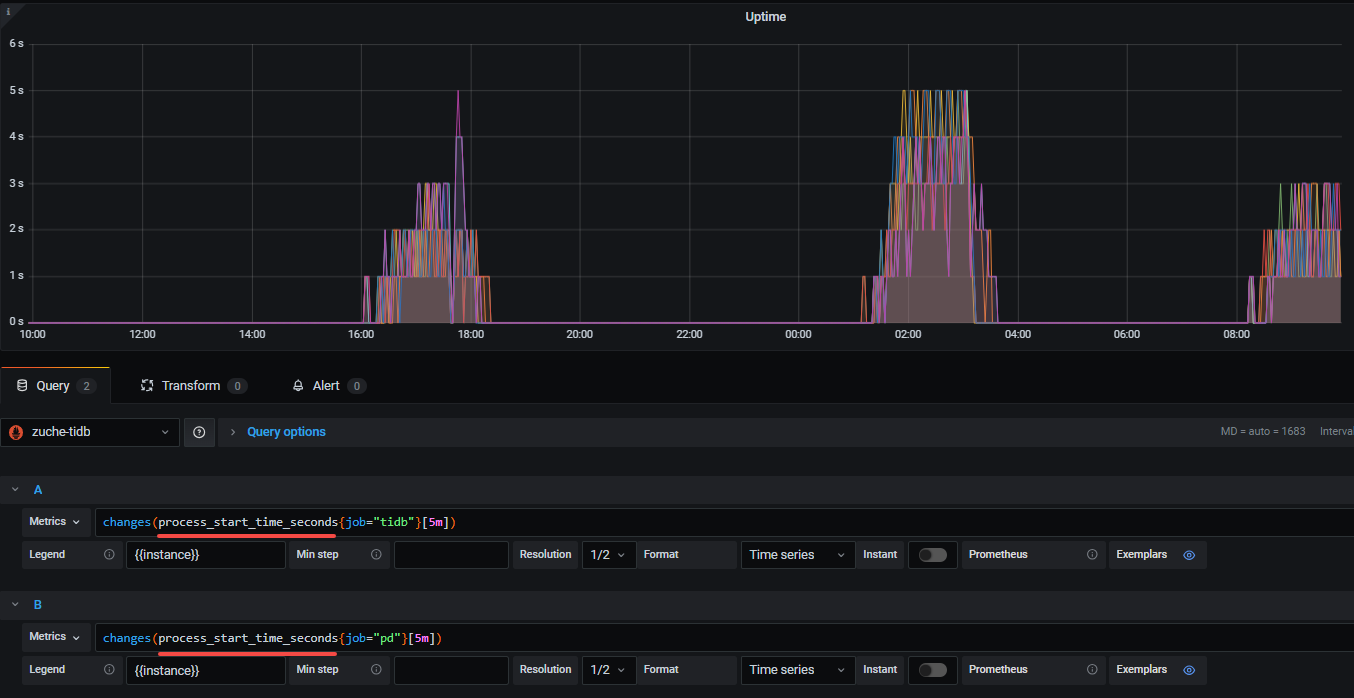
角色进程并没有重启:

process_start_time_seconds 监控指标获取的进程启动时间一直在变动,所以导致改监控持续误报
【 TiDB 使用环境】生产环境
【 TiDB 版本】 V 6.1.5
【遇到的问题:问题现象及影响】
Tidb内置altermanager 突然持续告警,报警信息:tidb、pd角色重启
但是登录查看进程信息发现并没有重启。
持续报警:
角色进程并没有重启:
这个指标应该是和top命令里面看到的是一样的才对。
也不太可能有第二个来源,你的os是什么?
看下pd,tikv对应的日志问题,看下什么原因引起的重启。
linux
实际进程没有重启,tidb服务也正常,除了持续在报警,没有其他问题
liunx可还行,就算是个windows,win7和win11能一样么。
服务器上ps -ef|grep tidb 看下结果,能看到启动时间。
![]() CentOS Linux release 7.9.2009
CentOS Linux release 7.9.2009
![]()
那就和tidb没关系了,报警时prometheus的组件alert的,看下监控系统是否ok,看下网络是否正常,正常的话可以把该告警项禁用。
正常来说这个指标是进程启动的时间戳,没有重启是不会变化的,也就不会告警,不要看这个 changes 表达式了,把 changes 函数去掉看下
多记录几次表达式的值,看看是不是确实变了
把表达式时间戳转换成实际时间看看,难道变成了当前时间?
这两个图就已经对不上了。03这台机器的pd启动时间一边显示是4.18,另一边显示是1.08。
如果os上显示没问题,那么问题出在采集上的可能性还是挺大的。
另外我发现,你使用了域名来访问每台机器,那么网络中某一时刻的域名对应的ip被污染了,也会采集到错误的机器数据。这也是一种可能性。
去掉看过,那个指标是持续上涨的一条线,也就是每次获取的时间戳确实在变化
确实变了,随着时间推移,是条持续上涨的线
怀疑是把当前时间戳,作为启动时间作为监控指标的值了
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。