【TiDB 使用环境】生产环境
【TiDB 版本】8.5.1
【操作系统】AWS
【部署方式】AWS云上部署
【集群数据量】4T
【集群节点数】9
【问题复现路径】从v7.1.1 升级到 v8.5.1
【遇到的问题:问题现象及影响】
背景:
升级系统后,出现了 insert into 语句的prewrite和commit 耗时在20s以上,有些甚至要几分钟才能完成的现象。持续了大约1天时间后有出现2台tikv先后重启,之后tikv的硬盘写入升高prewrite和commit开始恢复到ms级别。
问题:
生产环境有张表 w_item_rakuten_sku 大约1.5亿记录。
涉及region数量如下:

执行:select count(*) from api.w_item_rakuten_sku where id>1152921504630682995;
报错:ERROR 9001 (HY000): PD server timeout:
Explain结果:

处理:执行analyze table api.w_item_rakuten_sku; 上述sql可以正常执行。
但是其他session,再次执行查询仍然报错:
执行:select * from w_item_rakuten_sku force index (PRIMARY) limit 1
报错:ERROR 9001 (HY000): PD server timeout
Explain结果如下:
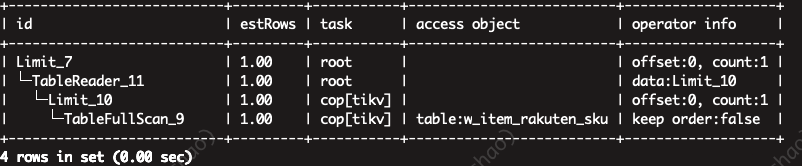
处理:再次执行 analyze table之后,查询正常返回。
每次都analyze也不是个办法,想请问下有什么调查方向没?是否什么参数配置导致的?
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
从tidb服务器ping pd服务器:大约0.25ms
pd服务器cpu99%idle,硬盘空闲;
【复制黏贴 ERROR 报错的日志】
pd.log 和 tikv.log: 此时间点没有内容;
tidb.log
[2025/04/29 15:10:55.488 +09:00] [WARN] [backoff.go:179] [“pdRPC backoffer.maxSleep 10000ms is exceeded, errors:\nPD returned regions have gaps, rang
e num: 2, limit: 128 at 2025-04-29T15:10:49.551409367+09:00\nPD returned regions have gaps, range num: 2, limit: 128 at 2025-04-29T15:10:51.285390702
+09:00\nPD returned regions have gaps, range num: 2, limit: 128 at 2025-04-29T15:10:53.492388735+09:00\ntotal-backoff-times: 7, backoff-detail: pdRPC
:7, maxBackoffTimeExceeded: true, maxExcludedTimeExceeded: false\nlongest sleep type: pdRPC, time: 10899ms”] [conn=641932222] [session_alias=]
[2025/04/29 15:10:55.489 +09:00] [INFO] [conn.go:1184] [“command dispatched failed”] [conn=641932222] [session_alias=] [connInfo=“id:641932222, addr:127.0.0.1:61334 status:10, collation:utf8_general_ci, user:root”] [command=Query] [status=“inTxn:0, autocommit:1”] [sql=“select * from w_item_rakuten_sku force index (PRIMARY) limit 1”] [txn_mode=PESSIMISTIC] [timestamp=457679056292806657] [err=“[tikv:9001]PD server timeout: \ngithub.com/pingcap/errors.AddStack\n\t/root/go/pkg/mod/github.com/pingcap/errors@v0.11.5-0.20240318064555-6bd07397691f/errors.go:178\ngithub.com/pingcap/errors.(*Error).GenWithStackByArgs\n\t/root/go/pkg/mod/github.com/pingcap/errors@v0.11.5-0.20240318064555-6bd07397691f/normalize.go:175\ngithub.com/pingcap/tidb/pkg/store/driver/error.ToTiDBErr\n\t/workspace/source/tidb/pkg/store/driver/error/error.go:119\ngithub.com/pingcap/tidb/pkg/store/copr.(*RegionCache).SplitKeyRangesByLocations\n\t/workspace/source/tidb/pkg/store/copr/region_cache.go:190\ngithub.com/pingcap/tidb/pkg/store/copr.(*RegionCache).SplitKeyRangesByBuckets\n\t/workspace/source/tidb/pkg/store/copr/region_cache.go:232\ngithub.com/pingcap/tidb/pkg/store/copr.buildCopTasks\n\t/workspace/source/tidb/pkg/store/copr/coprocessor.go:353\ngithub.com/pingcap/tidb/pkg/store/copr.(*CopClient).BuildCopIterator.func3\n\t/workspace/source/tidb/pkg/store/copr/coprocessor.go:159\ngithub.com/pingcap/tidb/pkg/kv.(*KeyRanges).ForEachPartitionWithErr\n\t/workspace/source/tidb/pkg/kv/kv.go:476\ngithub.com/pingcap/tidb/pkg/store/copr.(*CopClient).BuildCopIterator\n\t/workspace/source/tidb/pkg/store/copr/coprocessor.go:173\ngithub.com/pingcap/tidb/pkg/store/copr.(*CopClient).Send\n\t/workspace/source/tidb/pkg/store/copr/coprocessor.go:100\ngithub.com/pingcap/tidb/pkg/distsql.Select\n\t/workspace/source/tidb/pkg/distsql/distsql.go:91\ngithub.com/pingcap/tidb/pkg/distsql.SelectWithRuntimeStats\n\t/workspace/source/tidb/pkg/distsql/distsql.go:146\ngithub.com/pingcap/tidb/pkg/executor.selectResultHook.SelectResult\n\t/workspace/source/tidb/pkg/executor/table_reader.go:70\ngithub.com/pingcap/tidb/pkg/executor.(*TableReaderExecutor).buildResp\n\t/workspace/source/tidb/pkg/executor/table_reader.go:421\ngithub.com/pingcap/tidb/pkg/executor.(*TableReaderExecutor).Open\n\t/workspace/source/tidb/pkg/executor/table_reader.go:298\ngithub.com/pingcap/tidb/pkg/executor/internal/exec.Open\n\t/workspace/source/tidb/pkg/executor/internal/exec/executor.go:433\ngithub.com/pingcap/tidb/pkg/executor/internal/exec.(*BaseExecutorV2).Open\n\t/workspace/source/tidb/pkg/executor/internal/exec/executor.go:303\ngithub.com/pingcap/tidb/pkg/executor.(*LimitExec).Open\n\t/workspace/source/tidb/pkg/executor/select.go:496\ngithub.com/pingcap/tidb/pkg/executor/internal/exec.Open\n\t/workspace/source/tidb/pkg/executor/internal/exec/executor.go:433\ngithub.com/pingcap/tidb/pkg/executor.(*ExecStmt).openExecutor\n\t/workspace/source/tidb/pkg/executor/adapter.go:1259\ngithub.com/pingcap/tidb/pkg/executor.(*ExecStmt).Exec\n\t/workspace/source/tidb/pkg/executor/adapter.go:592\ngithub.com/pingcap/tidb/pkg/session.runStmt\n\t/workspace/source/tidb/pkg/session/session.go:2288\ngithub.com/pingcap/tidb/pkg/session.(*session).ExecuteStmt\n\t/workspace/source/tidb/pkg/session/session.go:2150\ngithub.com/pingcap/tidb/pkg/server.(*TiDBContext).ExecuteStmt\n\t/workspace/source/tidb/pkg/server/driver_tidb.go:291\ngithub.com/pingcap/tidb/pkg/server.(*clientConn).handleStmt\n\t/workspace/source/tidb/pkg/server/conn.go:2026\ngithub.com/pingcap/tidb/pkg/server.(*clientConn).handleQuery\n\t/workspace/source/tidb/pkg/server/conn.go:1779\ngithub.com/pingcap/tidb/pkg/server.(*clientConn).dispatch\n\t/workspace/source/tidb/pkg/server/conn.go:1378\ngithub.com/pingcap/tidb/pkg/server.(*clientConn).Run\n\t/workspace/source/tidb/pkg/server/conn.go:1147\ngithub.com/pingcap/tidb/pkg/server.(*Server).onConn\n\t/workspace/source/tidb/pkg/server/server.go:741\nruntime.goexit\n\t/usr/local/go/src/runtime/asm_amd64.s:1700”]
【其他附件:截图/日志/监控】
