【TiDB 使用环境】Poc
【TiDB 版本】 v8.5.1
关于关联子查询的优化建议点,请帮看下是否都正确。
-
关联子查询通常会通过in,exists语句方式实现,在通用场景下更多的建议使用exists,因为exists相比in有更多的解关联处理场景(由apply优化成semi join)。
-
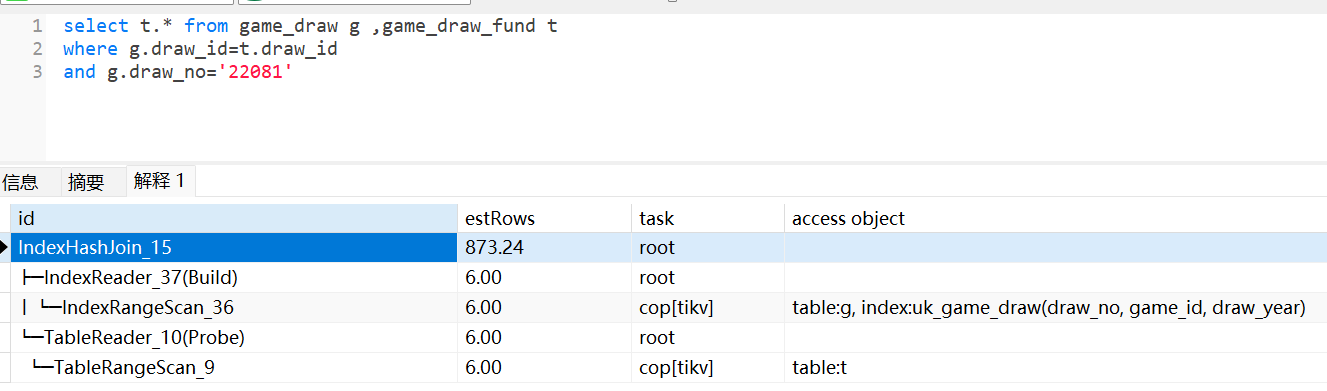
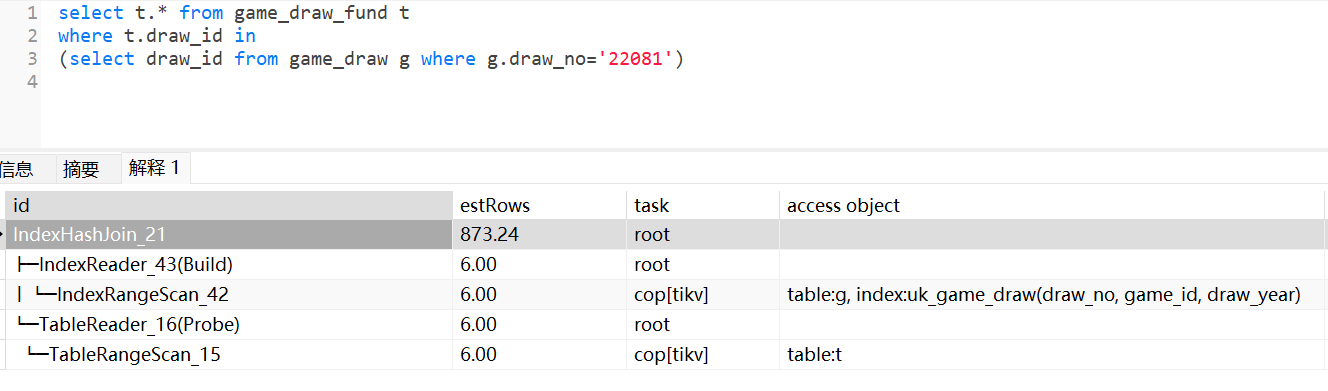
对于最常见的子查询场景:select * from t1 where exists (select 1 from t2 where t1.id=t2.id)
- 如果t1是小表,t2是大表,那么最佳优化方式是:t2.id必须存在索引,让Semi Join走indexJoin(只会选择t1表做驱动表),获得更好的效率(如果t2.id没有索引,则只能走HashJoin,选择t2这个大表构建哈希表,效率很低)。
- 如果t1是大表,t2是小表,关联匹配结果是大结果集,那么无需任何优化,Semi Join会选择Hash Join方式且只会选择t2做哈希表,获得最高半连接效率。
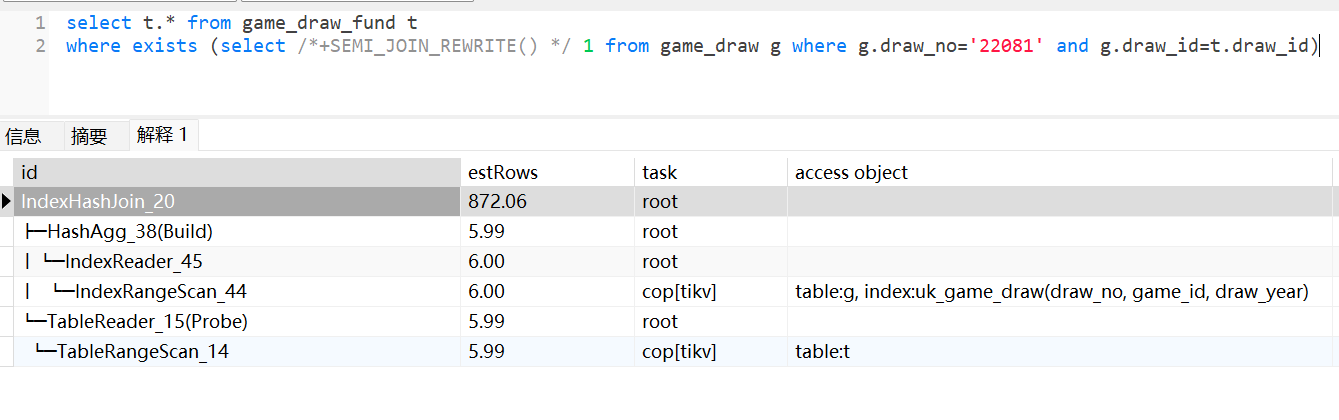
- 如果t1是大表,t2是小表,关联匹配结果是小结果集,那么最佳优化方式是:t1.id必须存在索引,且需要使用SEMI_JOIN_REWRITE这个hint关键字,让子查询优化成inner Join方式,对于inner Join优化器会自动选择indexjoin且选择t2表做驱动表,获得最高半连接效率。
-
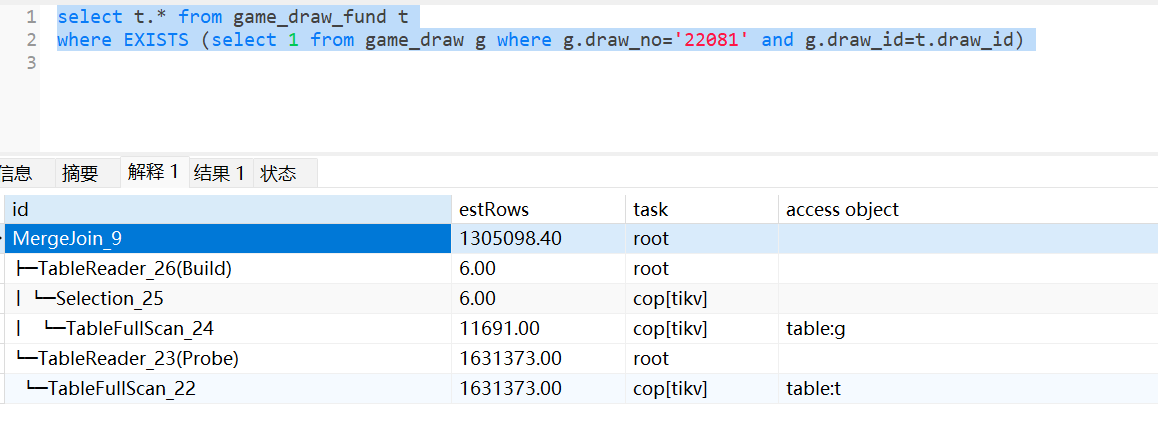
对于exists语句,不能随意使用SEMI_JOIN_REWRITE这个hint关键字,因为它总是会对子查询(t2表)做分组去重然后优化成inner join,如果t2表具有非常大的数据量,那么会非常耗时,效率可能更低。
-
对于多表关联且存在子查询的场景,如:a inner join b outer join c where exists (select 1 from d where a.id=d.id),优化器无法对semi join做join reorder,只会最后执行semi join,因此如果想提前过滤子查询数据,那么适当评估添加SEMI_JOIN_REWRITE这个hint关键字,让子查询优化成inner join,这样可让优化器对优化后的子查询(优化成inner join)使用join reorder算法进行优化。
-
semi join效率理论上会高于inner join,只是由于在tidb中存在一些实现上的局限性,导致多数场景不如被优化成inner join更好一些(semi join局限性:比如上面说的多表关联join reorder,hash join只能选择内表做哈希表,indexjoin只能选择外表做驱动表)。
另外,对于select * from t1 where exists (select /*+SEMI_JOIN_REWRITE() */ 1 from t2 where t1.id=t2.id),如果t2.id是主键,那么将其重写为inner join时没别要对t2做去重处理了吧?但是优化器还是会做去重(in子查询语句则不会对主键再做去重处理)。产品是否需要对其进行优化?
例子:
mysql> desc nation; --n_nationkey是主键
+-------------+--------------+------+------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+------+---------+-------+
| N_NATIONKEY | bigint(20) | NO | PRI | NULL | |
| N_NAME | char(25) | NO | | NULL | |
| N_REGIONKEY | bigint(20) | NO | | NULL | |
| N_COMMENT | varchar(152) | YES | | NULL | |
+-------------+--------------+------+------+---------+-------+
4 rows in set (0.00 sec)
mysql> explain select * from customer a where exists(select /*+ semi_join_rewrite() */ 1 from nation b where a.c_custkey=b.n_nationkey);
+--------------------------------+---------+-----------+---------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+--------------------------------+---------+-----------+---------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| IndexHashJoin_19 | 25.00 | root | | inner join, inner:TableReader_14, outer key:tpch10.nation.n_nationkey, inner key:tpch10.customer.c_custkey, equal cond:eq(tpch10.nation.n_nationkey, tpch10.customer.c_custkey) |
| ├─StreamAgg_43(Build) | 25.00 | root | | group by:tpch10.nation.n_nationkey, funcs:firstrow(tpch10.nation.n_nationkey)->tpch10.nation.n_nationkey |
| │ └─TableReader_44 | 25.00 | root | | data:StreamAgg_36 |
| │ └─StreamAgg_36 | 25.00 | cop[tikv] | | group by:tpch10.nation.n_nationkey, |
| │ └─TableFullScan_28 | 25.00 | cop[tikv] | table:b | keep order:true |
| └─TableReader_14(Probe) | 25.00 | root | | data:TableRangeScan_13 |
| └─TableRangeScan_13 | 25.00 | cop[tikv] | table:a | range: decided by [tpch10.nation.n_nationkey], keep order:false |
+--------------------------------+---------+-----------+---------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
7 rows in set (0.00 sec)
关于关联子查询,上面的理解是否正确,请大佬指正。