EchoX
(Ti D Ber Qu2 N Hjf6)
1
【TiDB 使用环境】生产环境
tidb_version(): Release Version: v7.1.2
Edition: Community
Git Commit Hash: aa6ed99ae63191bc98e883fd4c369ae7482cccb7
Git Branch: heads/refs/tags/v7.1.2
UTC Build Time: 2023-10-21 07:46:04
GoVersion: go1.20.10
Race Enabled: false
TiKV Min Version: 6.2.0-alpha
Check Table Before Drop: false
Store: tikv
执行的操作:
-- 创建备份表
CREATE TABLE `t_i_b_202408` ...
-- 迁移分区数据至备份表
ALTER TABLE t_i
EXCHANGE PARTITION P202408 WITH TABLE t_i_b_202408;
-- 校验数据
select count(*)
from t_i partition (p202408);
-- 删除分区
ALTER TABLE t_i
DROP PARTITION p202408;
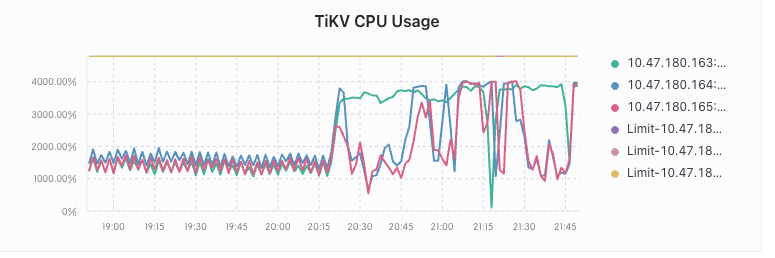
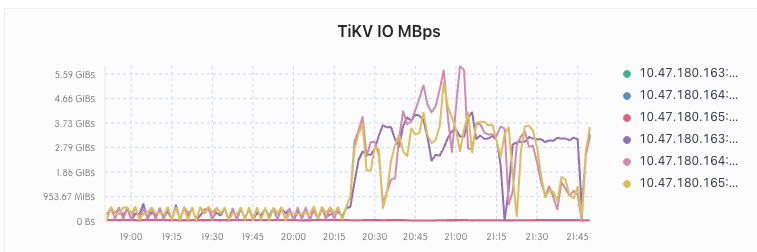
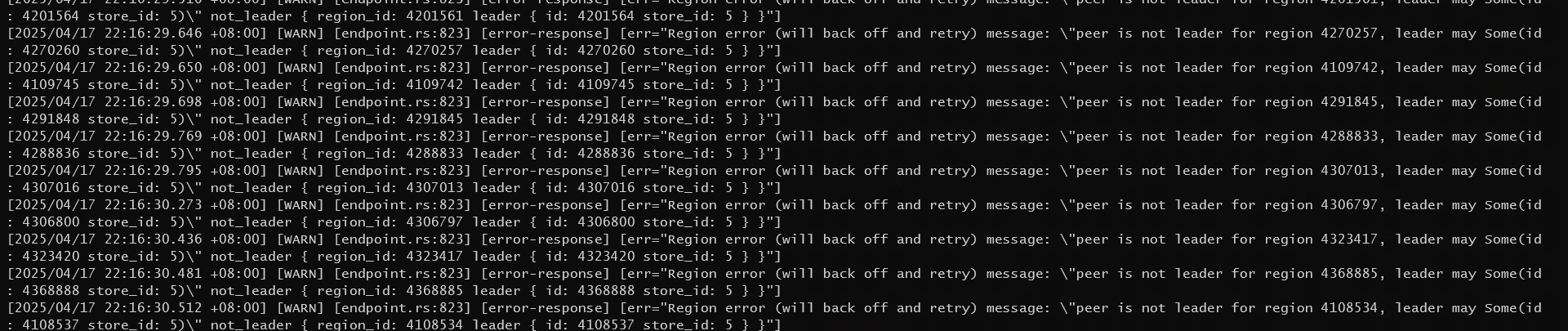
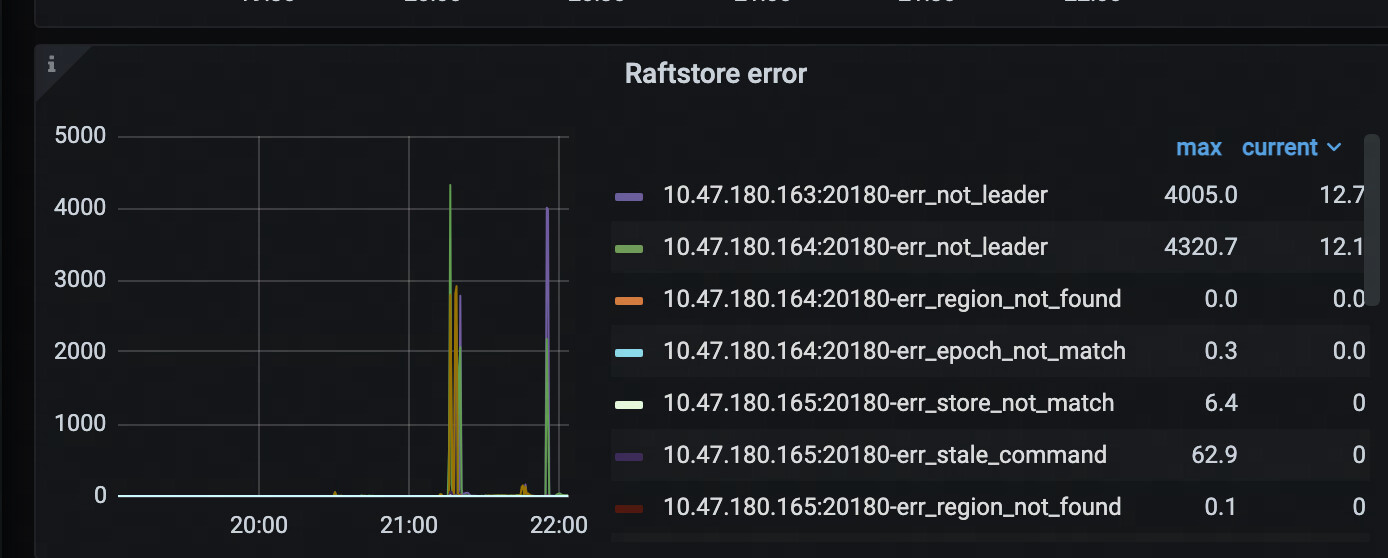
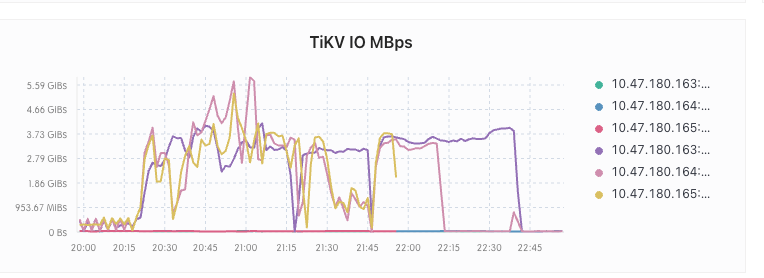
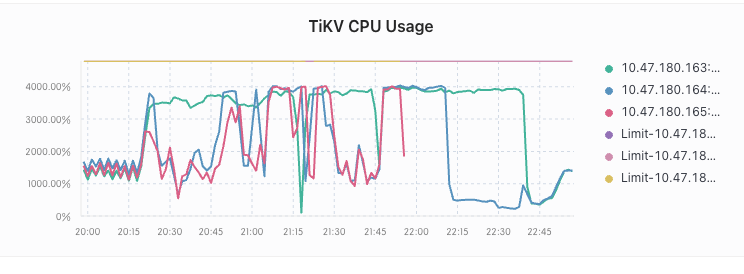
在执行完之后 tikv 的 io 和 cpu 暴涨 ,大量 SQL 超时
中间尝试过重启 tidb 以及 tikv 都无济于事
EchoX
(Ti D Ber Qu2 N Hjf6)
2
补充:迁移的那个分区内仅有 110 条数据
在持续 2 个多小时之后,io 和 cpu 降了下来,恢复正常
dba-kit
(张天师)
4
大概率是统计信息的问题,EXCANGE PARTITION 后统计信息需要重新生成的。
dba-kit
(张天师)
5
可以看下 auto_analyze 的时间配置,是不是自动对这个分区表的Global stats 做了analyze
EchoX
(Ti D Ber Qu2 N Hjf6)
8
看过那段时间的执行计划,是没问题的。
还有就是后面将上层应用都停掉后,io 和 cpu 还是很高,所以应该不是执行计划的问题。
dba-kit
(张天师)
11
在进行 analyze 时候,也可能会导致 TiKV IO 和 CPU 高的,所以还是执行一下 show analyze status; 看下当时有没有 analyze
EchoX
(Ti D Ber Qu2 N Hjf6)
12
sorry ,这边再次确认了下,执行计划确实有问题
预估行数与实际差异巨大(如TableRangeScan 预估399万 vs 实际1.65亿)
所以大概率是
=> exchange partition 后导致 SQL 执行计划变更,大量 SQL 走了错误的执行计划,导致 io 和 cpu 暴涨
1 个赞
EchoX
(Ti D Ber Qu2 N Hjf6)
14
整个表的规模确实很大,只是操作的那个分区内的数据很少
总共 8 个分区,平均下来每个分区约 7kw 的数据,总共 5.6 亿左右的数据
1 个赞
我想知道,你用来交换分区的表上的索引都建了吧,只是因为交换分区导致统计信息没有选择走索引,而不是你的分区上没有了索引导致强制走了全表扫,如果是前者,重新收集下统计信息,后者的话得重建索引了吧?
EchoX
(Ti D Ber Qu2 N Hjf6)
16
索引都是有的,能交换分区的前提是表的结构完全一样才行,包括索引名称,结构等