【TiDB 使用环境】生产环境
【TiDB 版本】5.1.4
【操作系统】CentOS7
【部署方式】
【集群数据量】
【集群节点数】
【问题复现路径】做过哪些操作出现的问题
1)在主库上建表, 用到/*!90000 SHARD_ROW_ID_BITS=4 */ /*T![clustered_index] NONCLUSTERED */。
2)发现drainer同步中断,drainer status中 Max_Commit_Ts: 457180731289894973

3)drainer日志中出错及,commit_ts:457180731289894981
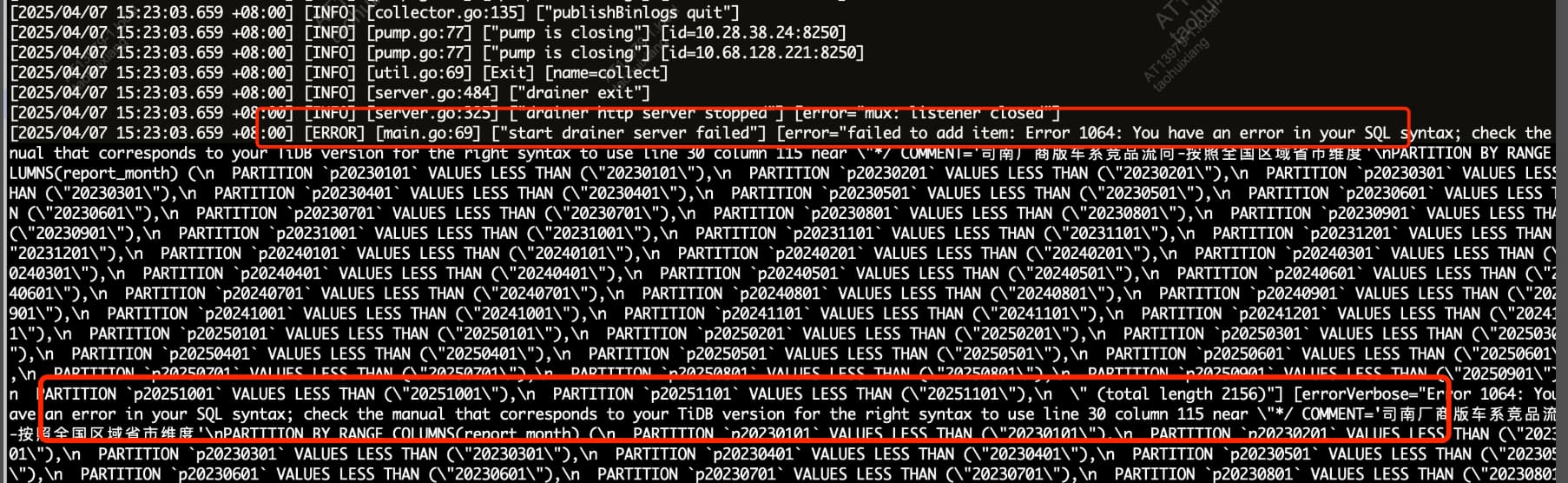

【遇到的问题:问题现象及影响】
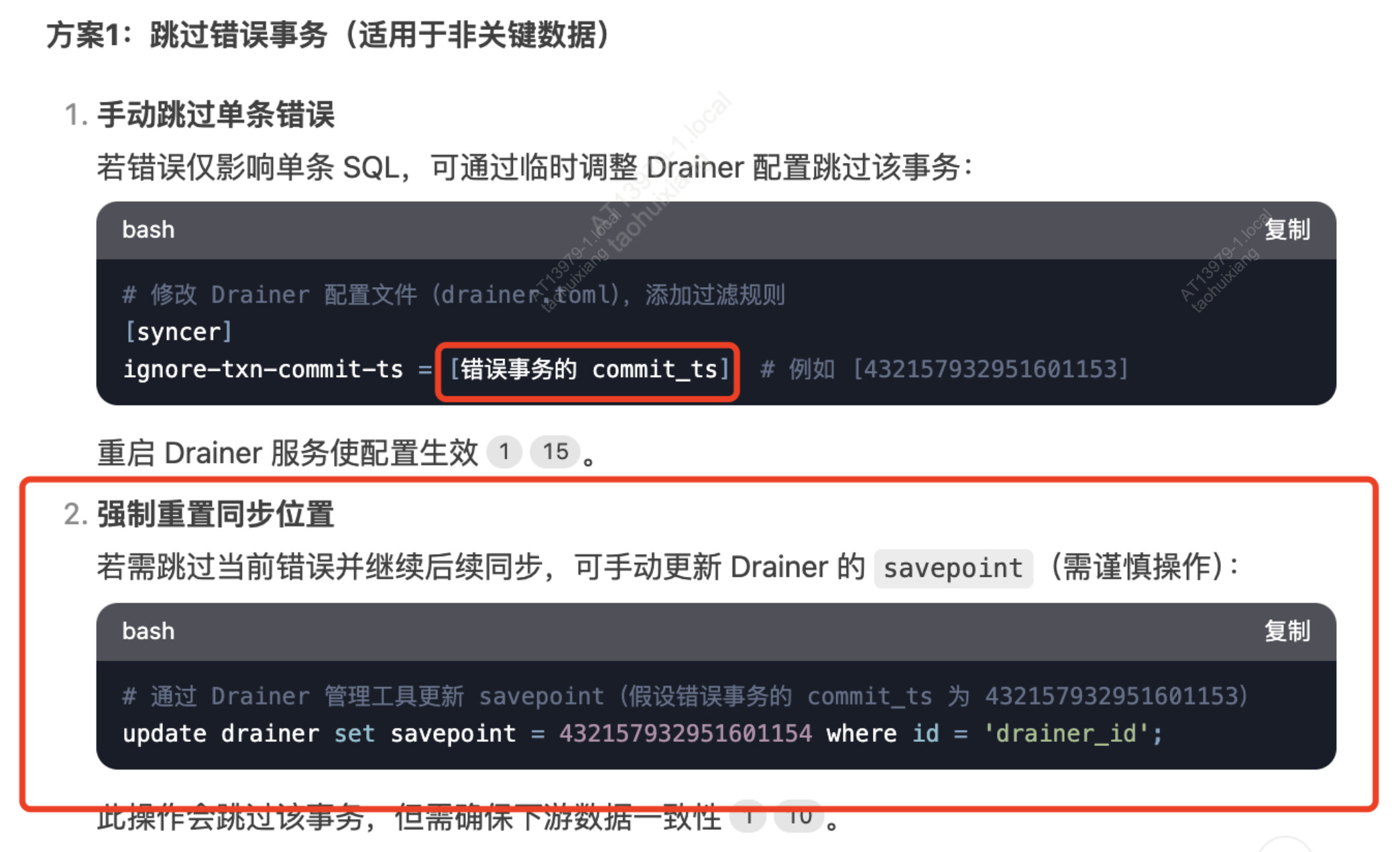
1)如何跳过问题点,恢复同步?
2) 使用哪个tso来跳过?drainer status中的Max_Commit_Ts,还是日志中的commit_ts ?
【资源配置】
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】