TiDBer_Jack
(Ti D Ber Mk Wfi W Zy)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.9
【复现路径】无
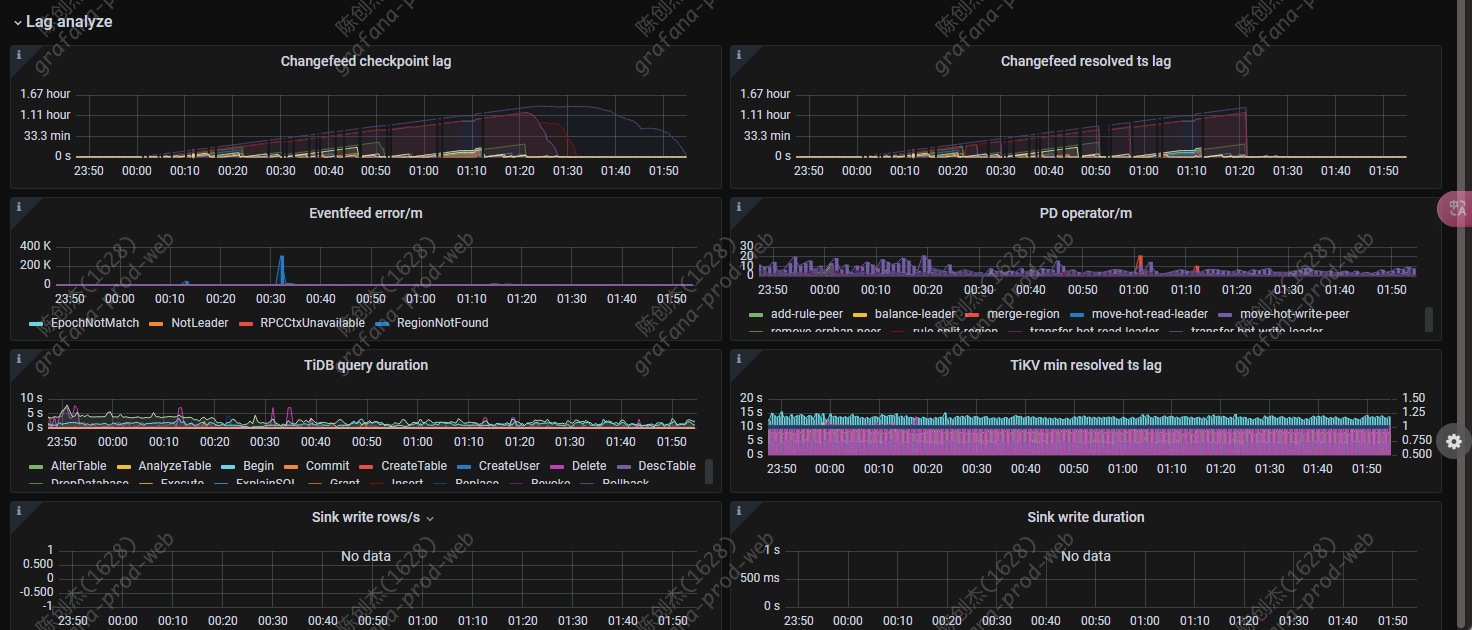
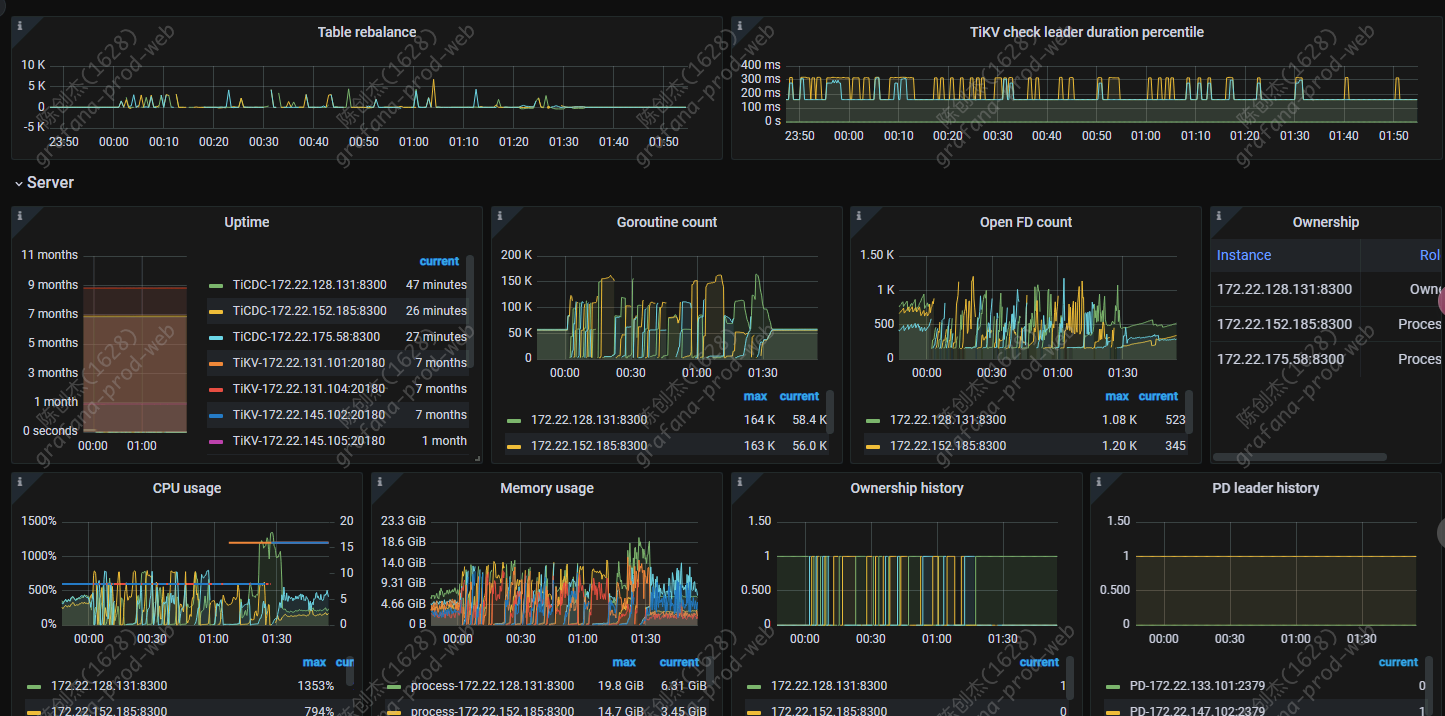
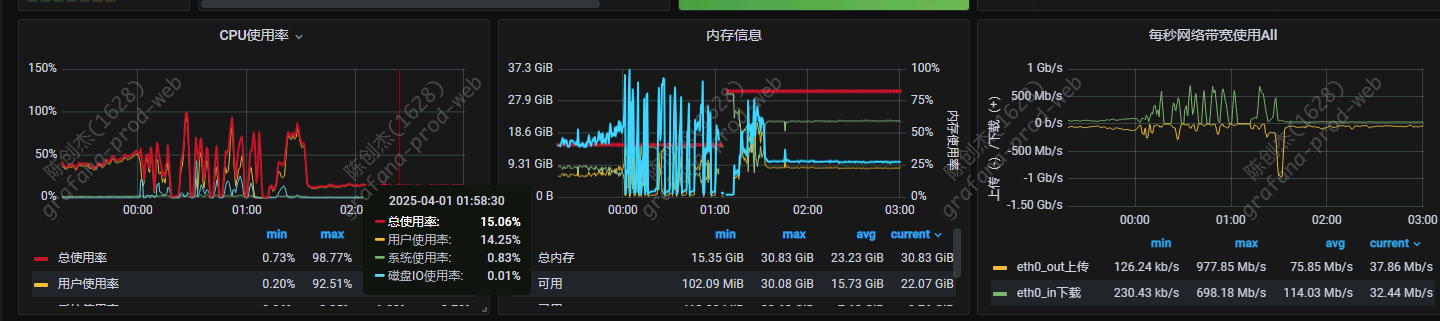
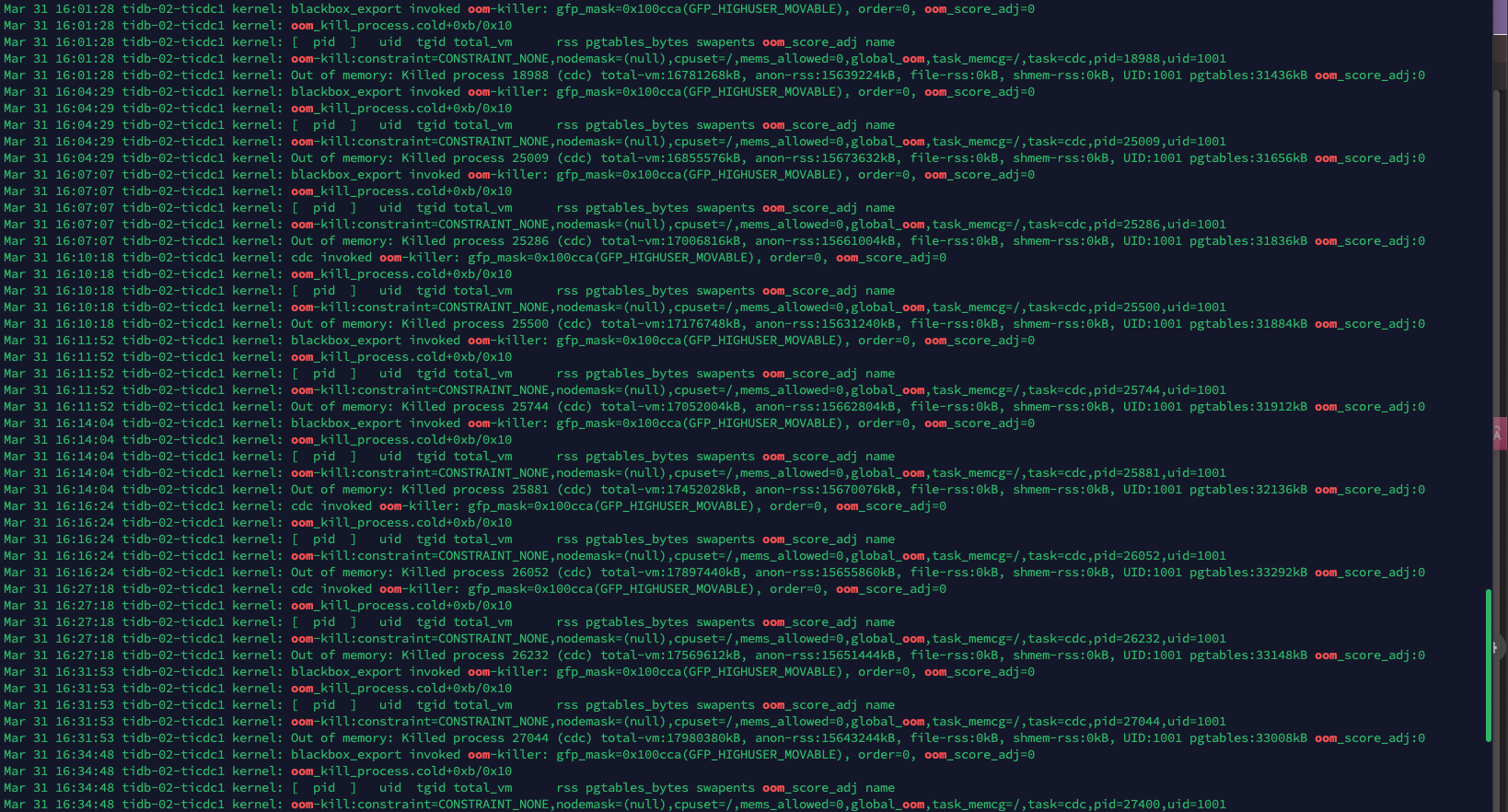
【遇到的问题:问题现象及影响】4 月 1 号凌晨突然 cdc oom,导致同步延时
【资源配置】 3 台 ticdc 全为 8c16g
【附件:截图/日志/监控】
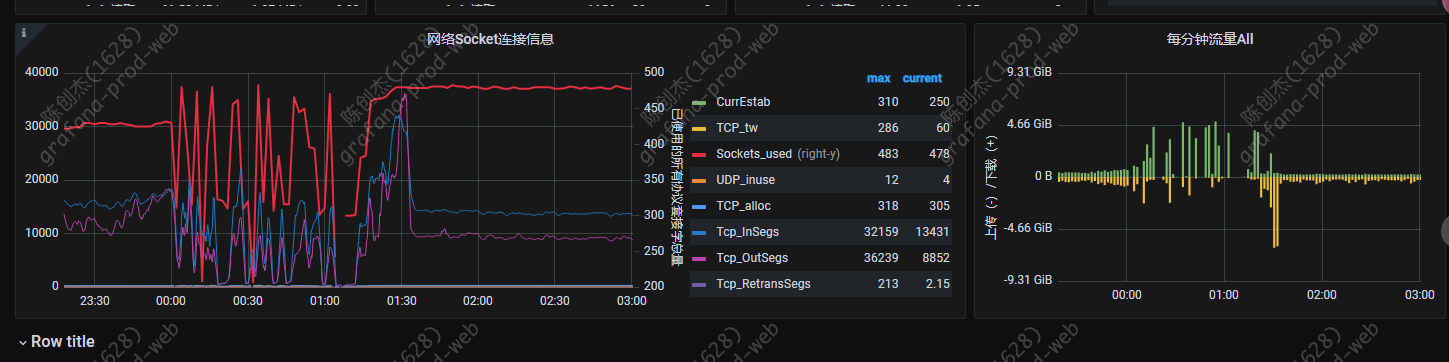
在 0 点 1 分的时候,ticdc 出现 oom,导致数据同步延时,同步的地方有 tidb → tidb,tidb -->kafka,求各位大佬帮我分析下原因,如何排查这个问题
0 点的运维定时操作: 在每个月的 1 号 0 点执行添加按月分区的 sql,sql 已验证过,不会对 cdc 任务有影响
恢复操作: 升级 ticdc 为 16c32g
监控的断点是 cdc 服务 oom 了,三台一直循环 oom
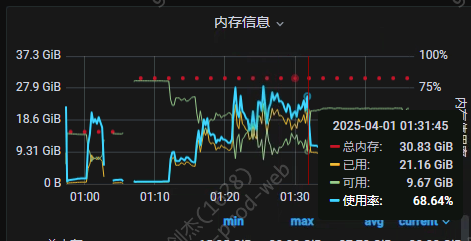
其中一台 cdc 的 cpu 内存,流量监控
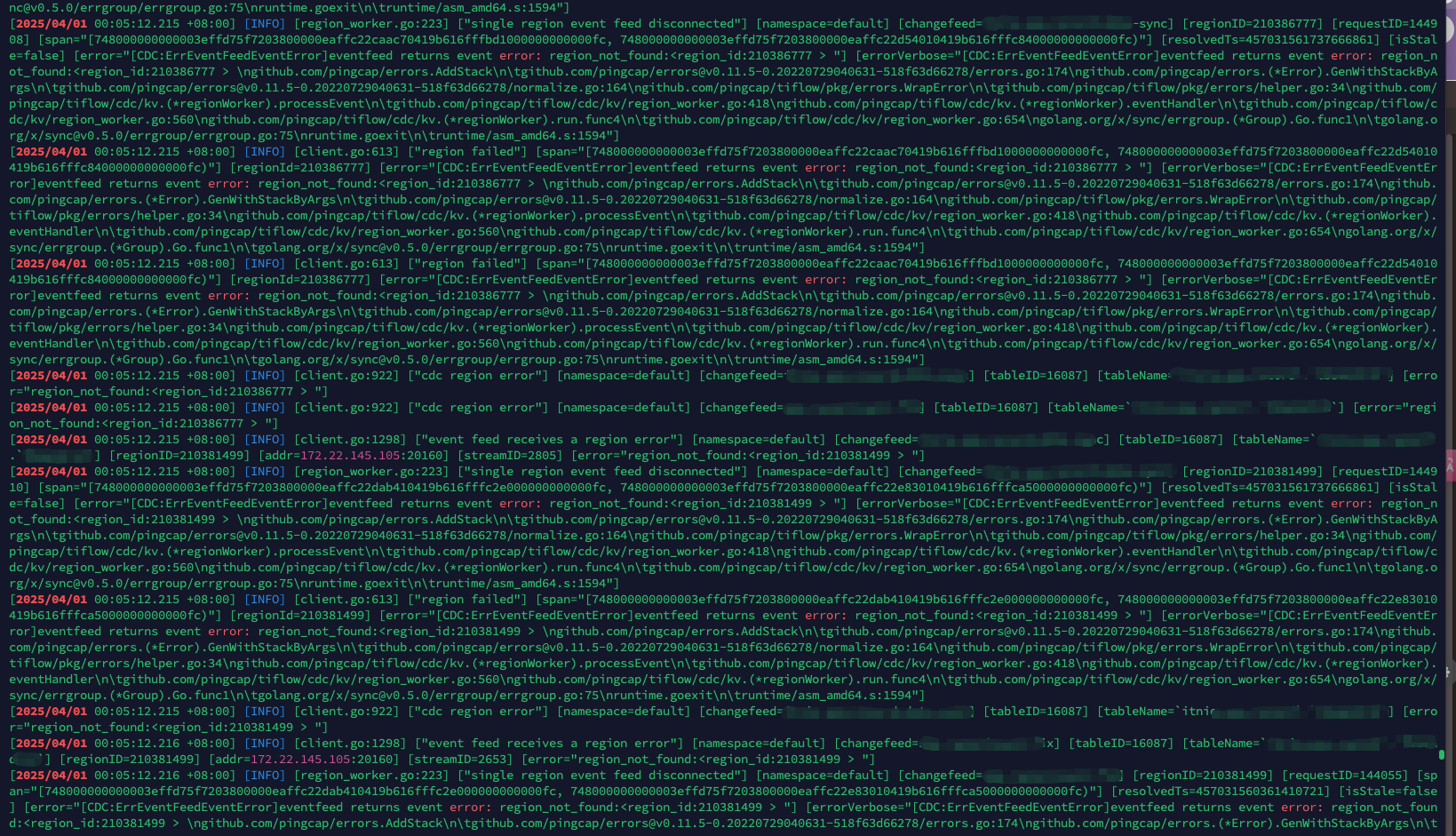
cdc 的错误日志
你的升级方式是怎么样的,是一台一台先扩容再缩容吗?
TiDBer_Jack
(Ti D Ber Mk Wfi W Zy)
3
不是,因为 cdc 一直 oom 持续重启了,我直接关机,升级配置
升级完是慢慢恢复了,没升级的时候就一直 oom,导致延迟越来越大,数据没法同步到下游,我想要知道是什么原因导致的,查不出来,无从下手 
TiDBer_Jack
(Ti D Ber Mk Wfi W Zy)
5
不会,升级完过十分钟左右,延迟慢慢减少,半小时左右恢复,就是什么情况下会出现 oom,这个我们得确认,主要我看日志,监控,都看不出是什么问题导致的
TiDBer_wk
(Ti D Ber Os7emy Bg)
7
dba远航
(Ti D Ber M Lo7 Bqhk)
8
感觉是升级造成资源紧张,出现OOM,然后一直不能完成,所以持续OOM
啦啦啦啦啦
10
16G确实太小了,官方建议的生产环境配置是64G,我们这边ticdc 平时内存也得用10G左右,高峰能到20G以上
TiDBer_Jack
(Ti D Ber Mk Wfi W Zy)
11
好吧,对于突增的内存确实没找到存在的问题,我们的每个任务默认使用内存都是 1G,有一个是 4G,估计就是几个任务的量突然增多,导致打满的
TiDBer_Jack
(Ti D Ber Mk Wfi W Zy)
13
没有开启的
排查结果就是没发生特别大的事务,都是正常的操作