【TiDB 使用环境】生产环境
【TiDB 版本】v6.5.0
【操作系统】ubuntu
【部署方式】机器部署(k8s集群)
【集群数据量】1
【集群节点数】1
【问题复现路径】每天人流量大入库数据多时比较容易复现,最近两天更频繁。每天数据量到500万级别。无操作,自然出现
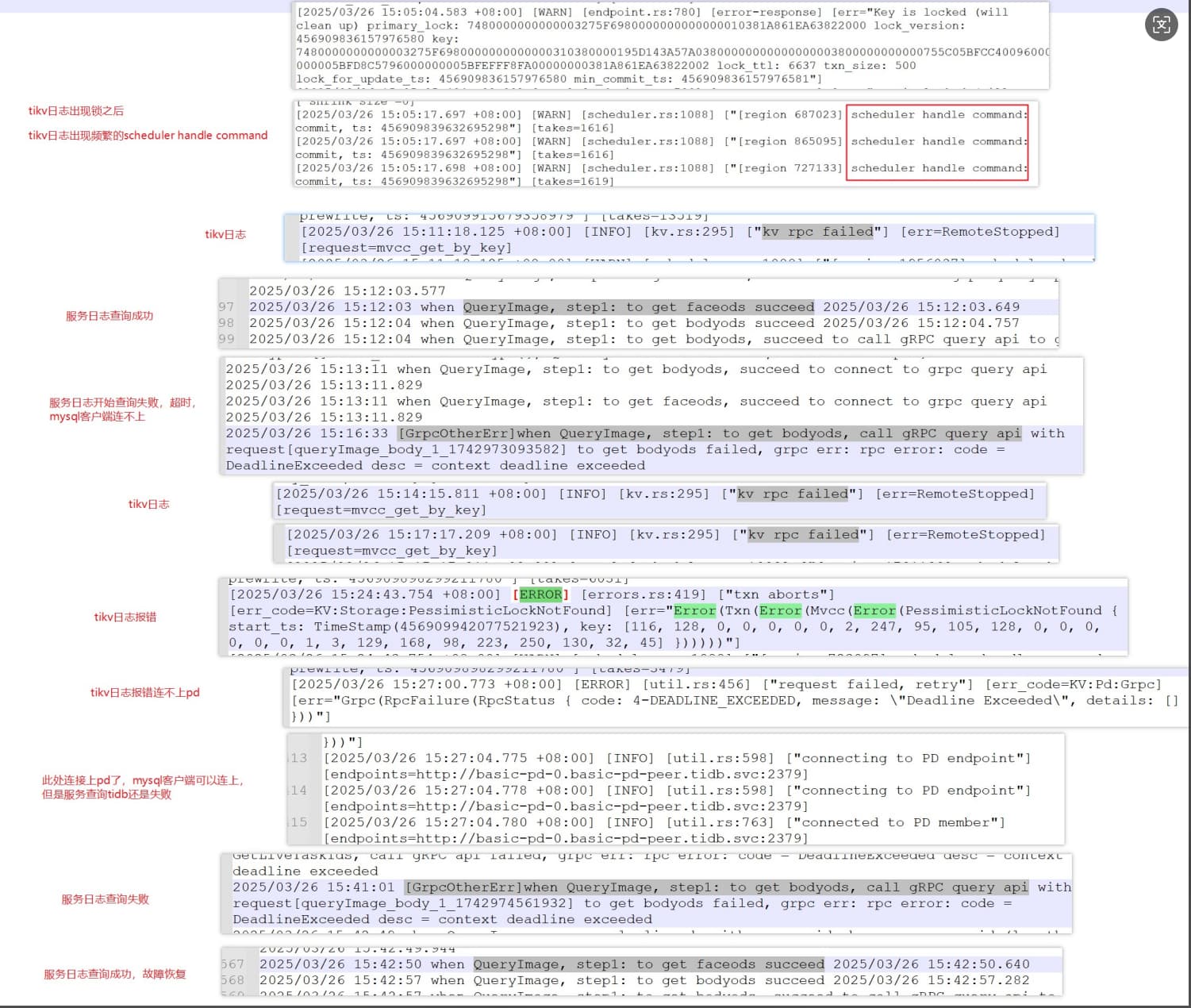
【遇到的问题:问题现象及影响】本次记录15:13分左右服务查询开始超时,到15:42查询成功期间的日志。现象mysql客户端连不上。服务查询报错超时,看tikv日志有大量scheduler handle command,然后15:27tikv日志报错请求pd失败,错误码是4-DEADLINE_EXCEEDED,在15:27:04成功连接上pd,mysql客户端可以连上,服务查询还是超时,直到15:42
【资源配置】
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
日志与指标.zip (8.8 MB)
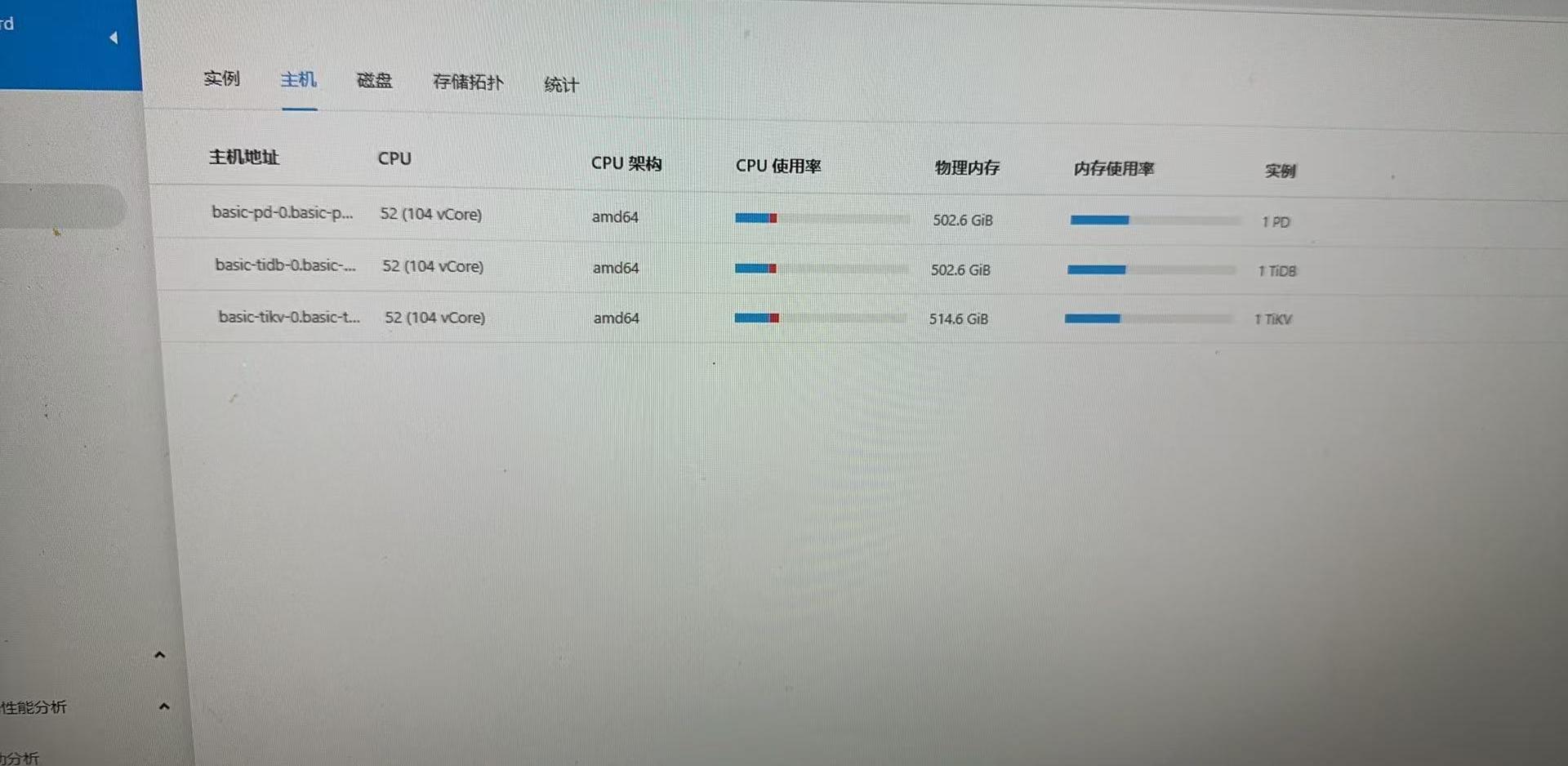
这个是主机的资源,k8s服务用dashboard看不准的,需要看sts的
kubectl get sts xxx -o yaml 看服务的limit以及request
我看好像一个都没有限制资源,这样就无法保证优先级了,最好分配下资源。节点上有其他K8S服务吗
有其他k8s服务,如何设置资源限制比较好?有推荐吗?目前最大一个表数据新增在500-800万左右
生产环境建议至少3实例,只有一个节点的话,保证不了性能,一般也就能用。
请问下有yaml文件的样例吗?
basic-pd
basic-tidb
basic-tikv
是上面三个组件都改成3个吗?
这个你可以先登录下tidb,show config先看看配置的多少,像你这个情况可能就是主机的内存了,不是容器的内存。
pd跟tikv我不知道你们使用的哪种sc,可能直接改成3是不行的,你有可能需要三台服务器才能改成3
如果要改数据库的配置,需要改tidbcluster的CR,然后重启即可
格式可以参考
想问下客户端出现连不上的原因是没有限制资源吗?
因为服务器限制只有一台,然后现在是看tidb的show config看下配置,然后增加sc中cpu和内存的限制可以解决这个问题吗?
tidb-cluster.yaml (4.5 KB)
部署的sc是这样,包含pd,tidb,tikv
config.txt (82.3 KB)
show config结果如上
1、没有限制资源肯定是有问题的,因为没法保证资源使用的优先级。
2、从监控上看瓶颈在tikv上,你可以先分析下你的慢查询。
3、还有tikv用的这个nfs,是否做过性能测试?
1,2点我会分析一下的
3.请教下有什么推荐的工具来做性能测试,需要看哪些指标?