【TiDB 使用环境】生产环境
【TiDB 版本】
【操作系统】rocky 9
【部署方式】云上部署
【遇到的问题:问题现象及影响】
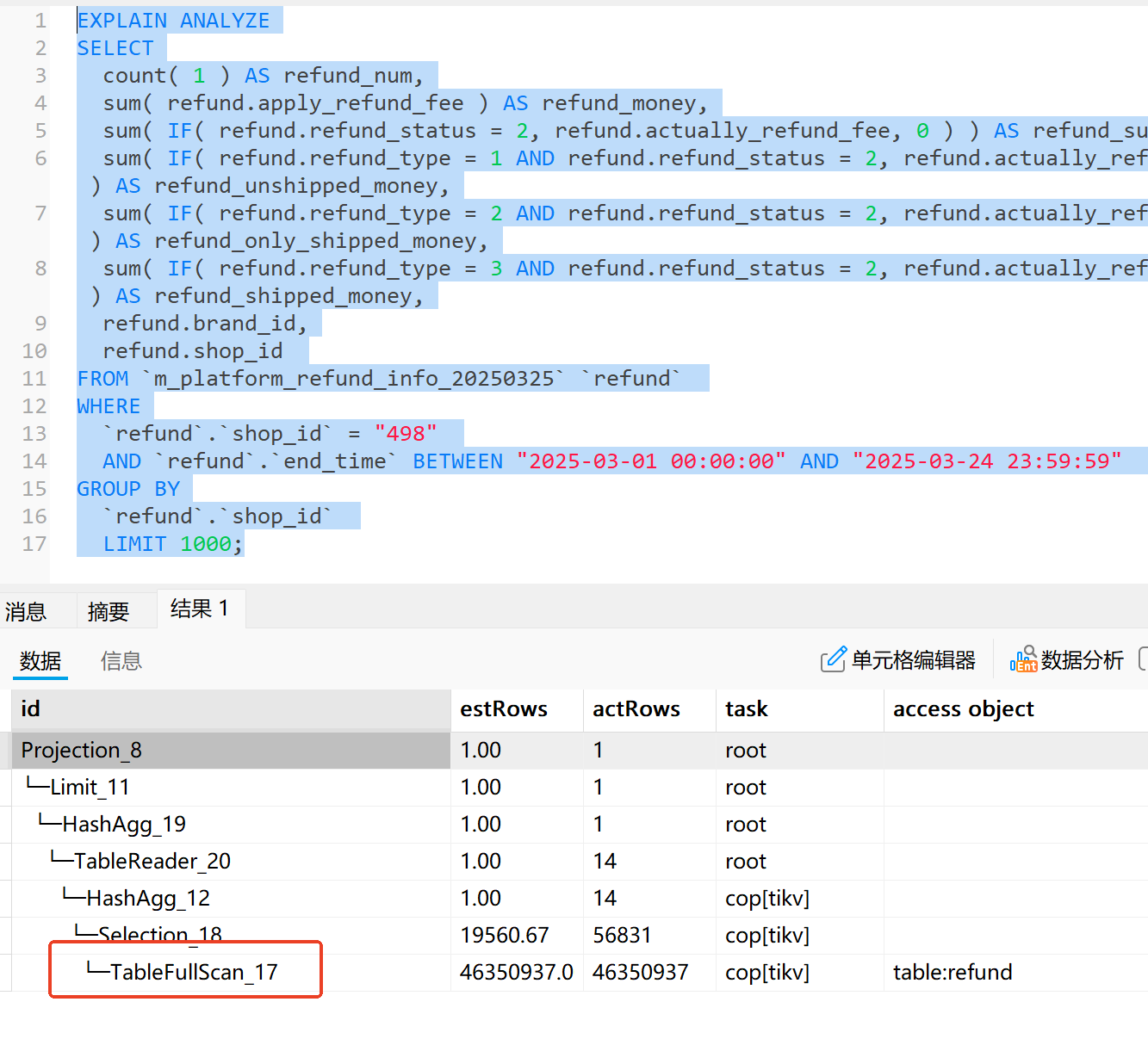
图片中的查询shop_id,end_time字段都有索引 为什么在最后一步中用的是TableFullScan?

表结构:
CREATE TABLE `m_platform_refund_info` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`unique_key` varchar(100) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '唯一键',
`refund_id` varchar(100) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '平台退款编号',
`refund_type` tinyint NOT NULL DEFAULT '0' COMMENT '退款类型 1、发货前仅退款;2、发货后仅退款;3、退货退款',
`refund_status` tinyint NOT NULL DEFAULT '0' COMMENT '退款状态。1.未退款,2.已退款,3.已取消',
`apply_refund_fee` decimal(20,8) NOT NULL DEFAULT '0' COMMENT '申请退款金额(元)',
`actually_refund_fee` decimal(20,8) NOT NULL DEFAULT '0' COMMENT '实退金额(元)',
`refund_timeout` datetime DEFAULT NULL COMMENT '退款超时时间',
`tid` varchar(100) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '平台订单号',
`oid` varchar(100) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '平台子订单号',
`oid_status` tinyint NOT NULL DEFAULT '0' COMMENT '对应的子订单的状态,1.待发货,2.部份分货,3.已发货,4.已完结,5.已关闭',
`sku_sn` varchar(100) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT 'sku编码',
`barcode` varchar(100) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '条码',
`sku_id` varchar(100) COLLATE utf8mb4_general_ci DEFAULT '' COMMENT '订单商品表里的sku_id,京东必填',
`order_sn` varchar(100) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT 'OMS里的order_sn',
`user_id` bigint unsigned NOT NULL DEFAULT '0' COMMENT 'OMS用户id',
`user_name` varchar(1024) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '买家名称',
`buyer_open_uid` varchar(100) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT 'open_uid',
`refund_reason` varchar(100) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '退款原因,一级',
`refund_reason2` varchar(100) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '退款原因,二级',
`return_status` tinyint NOT NULL DEFAULT '0' COMMENT '退货状态,1.无需退货 2.待退货 3.已退货 ',
`return_num` int unsigned NOT NULL DEFAULT '0' COMMENT '退货数量',
`ticket_sn` varchar(100) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '退货入库单号',
`order_created` datetime DEFAULT NULL COMMENT '订单的创建时间',
`order_pay_time` datetime DEFAULT NULL COMMENT '订单的支付时间',
`created` datetime DEFAULT NULL COMMENT '申请退款时间(平台时间)',
`modified` datetime DEFAULT NULL COMMENT '平台更新时间(平台)',
`end_time` datetime DEFAULT NULL COMMENT '退款完成时间',
`source` tinyint NOT NULL DEFAULT '1' COMMENT '退款来源 1.平台 2.手工',
`shop_id` int unsigned NOT NULL DEFAULT '0' COMMENT 'sso的店铺id',
`brand_id` int unsigned NOT NULL DEFAULT '0' COMMENT '品牌编码',
`data_from` tinyint DEFAULT '0' COMMENT '数据来源,96.OMS,98.SAAS OMS,,1天猫,2.京东,13.抖音,5.唯品会,',
`volume` varchar(100) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '数据源标识',
`add_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录添加时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '记录更新时间',
PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */,
KEY `tid` (`tid`),
KEY `oid` (`oid`),
KEY `sku_id` (`sku_id`),
KEY `sku_sn` (`sku_sn`),
KEY `end_time` (`end_time`),
KEY `created` (`created`),
KEY `refund_status` (`refund_status`),
KEY `shop_id` (`shop_id`),
UNIQUE KEY `unique_key` (`unique_key`),
KEY `idx_update_time` (`update_time`),
KEY `refund_id` (`refund_id`),
KEY `idx_order_pay_time` (`order_pay_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci AUTO_INCREMENT=238943224 COMMENT='aaa'
