【 TiDB 使用环境】生产环境 有一个tikv集群,版本是v8.1.1
当前环境是juicefs+tikv, 其中Juicefs是1.2,tikv是 v8.1.1
这个环境在当前吞吐很低,属于业务低峰期的时候,也出现了大量的事件
下面给下集群架构
# tiup cluster display xxxx
Cluster type: tidb
Cluster name: xxxx
Cluster version: v8.1.1
Deploy user: tikv
SSH type: xxxx
TLS encryption: enabled
CA certificate: xxxx
Client private key: xxxx
Client certificate: xxx
Dashboard URL: https://D:2379/dashboard
Grafana URL: http://A:3000
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
-- ---- ---- ----- ------- ------ -------- ----------
A:3000 grafana A 3000 linux/x86_64 Up - .../grafana-3000
B:2379 pd B 2379/2380 linux/x86_64 Up .../pd-2379 .../pd-2379
C:2379 pd C 2379/2380 linux/x86_64 Up .../pd-2379 .../pd-2379
D:2379 pd D 2379/2380 linux/x86_64 Up|L|UI .../pd-2379 .../pd-2379
A:9090 prometheus A 9090/12020 linux/x86_64 Up .../prometheus-8249/data .../prometheus-8249
A:8089 tidb A 8089/10080 linux/x86_64 Up - ../tidb-8089
A:20160 tikv A 20160/20180 linux/x86_64 Up .../tikv-20160 .../tikv-20160
B:20160 tikv B 20160/20180 linux/x86_64 Up .../tikv-20160 .../tikv-20160
C:20160 tikv C 20160/20180 linux/x86_64 Up .../tikv-20160 .../tikv-20160
【日志信息】
提取了pd的日志,过滤如下:
# cat pd_2025_03_22.log |grep "transfer-hot-read-leader" |grep "operator finish" |wc -l
301
详细的日志如下
pd_2025_03_22.log (518.5 KB)
【系统配置参数值】
{
"replication": {
"enable-placement-rules": "true",
"enable-placement-rules-cache": "false",
"isolation-level": "",
"location-labels": "",
"max-replicas": 3,
"strictly-match-label": "false"
},
"schedule": {
"enable-cross-table-merge": "true",
"enable-diagnostic": "true",
"enable-heartbeat-breakdown-metrics": "true",
"enable-joint-consensus": "true",
"enable-tikv-split-region": "true",
"enable-witness": "false",
"high-space-ratio": 0.7,
"hot-region-cache-hits-threshold": 3,
"hot-region-schedule-limit": 4,
"hot-regions-reserved-days": 7,
"hot-regions-write-interval": "10m0s",
"leader-schedule-limit": 4,
"leader-schedule-policy": "count",
"low-space-ratio": 0.8,
"max-merge-region-keys": 200000,
"max-merge-region-size": 20,
"max-movable-hot-peer-size": 512,
"max-pending-peer-count": 64,
"max-snapshot-count": 64,
"max-store-down-time": "30m0s",
"max-store-preparing-time": "48h0m0s",
"merge-schedule-limit": 8,
"patrol-region-interval": "10ms",
"region-schedule-limit": 2048,
"region-score-formula-version": "v2",
"replica-schedule-limit": 64,
"slow-store-evicting-affected-store-ratio-threshold": 0.3,
"split-merge-interval": "1h0m0s",
"store-limit-version": "v1",
"switch-witness-interval": "1h0m0s",
"tolerant-size-ratio": 0,
"witness-schedule-limit": 4
}
}
【监控】
系统负载监控
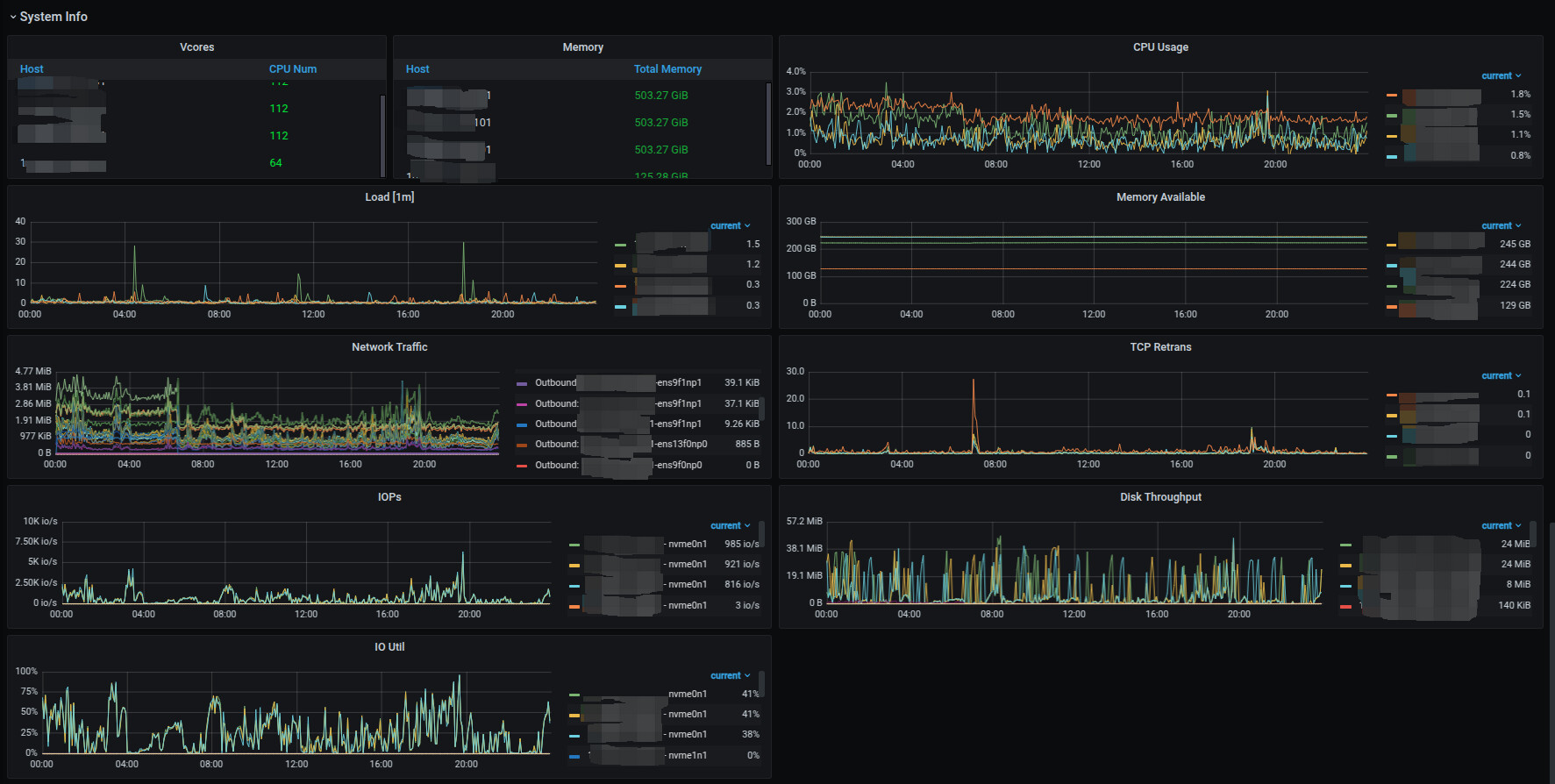
PD有三个不同的节点,上面没有混布tikv server,只有PD服务
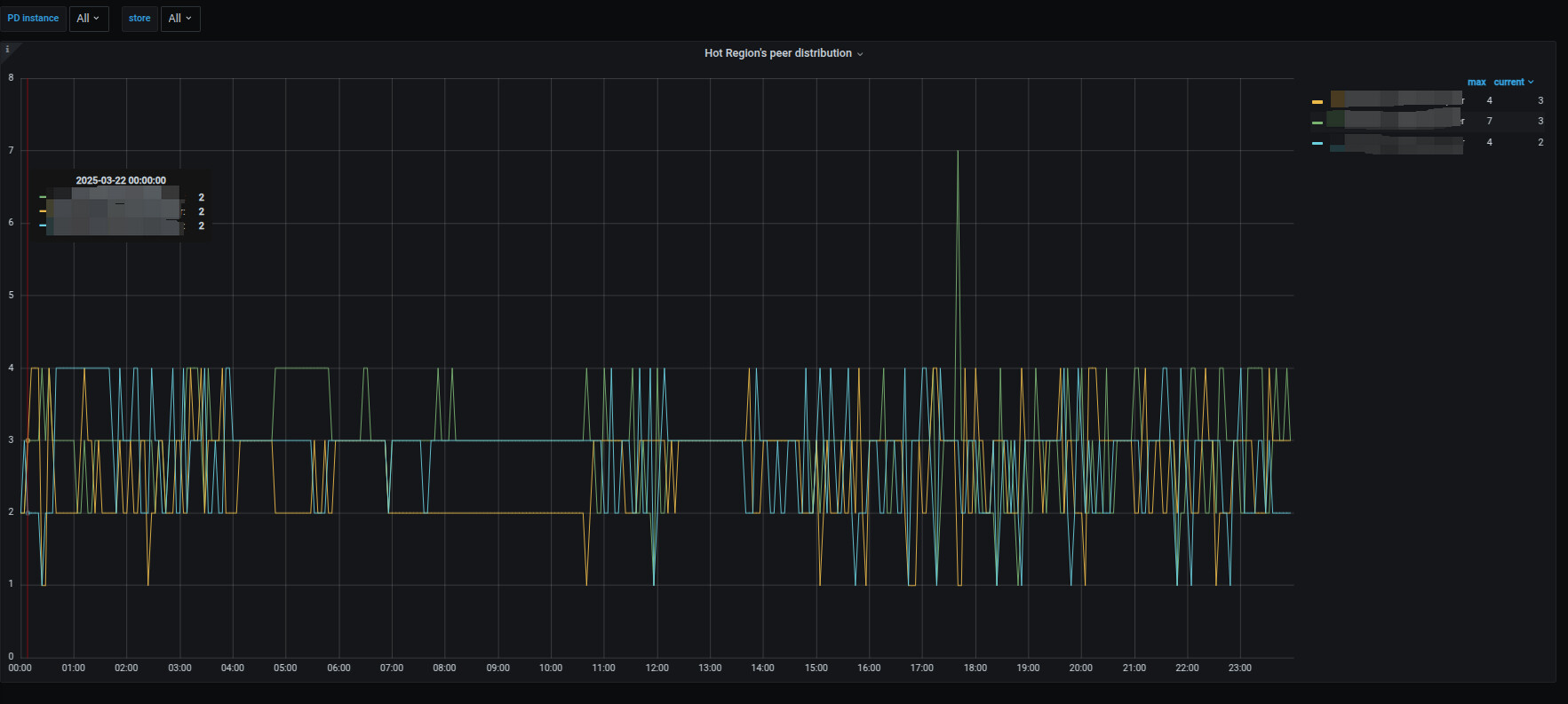
下面是Hot Region’s peer distributio
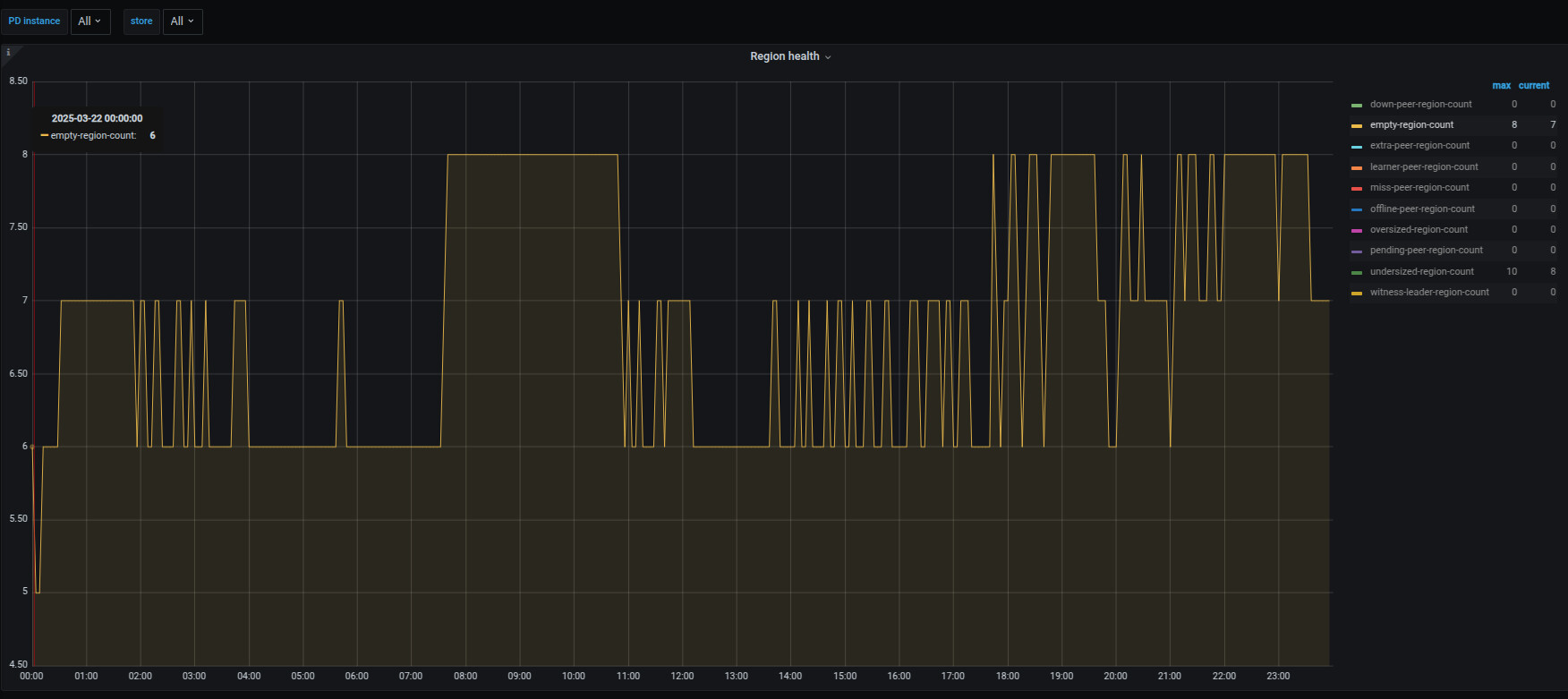
下面是region health
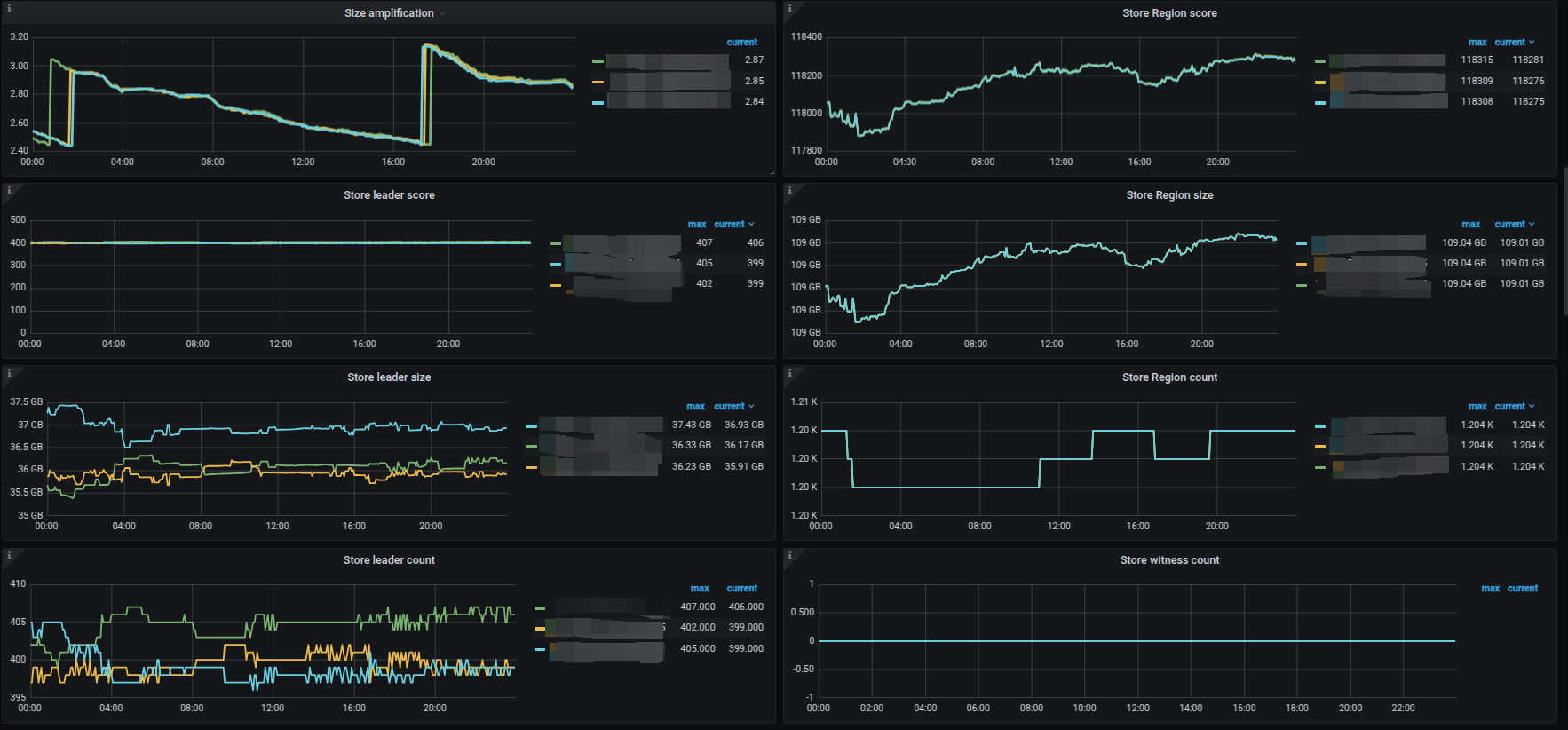
下面给出Balance的监控
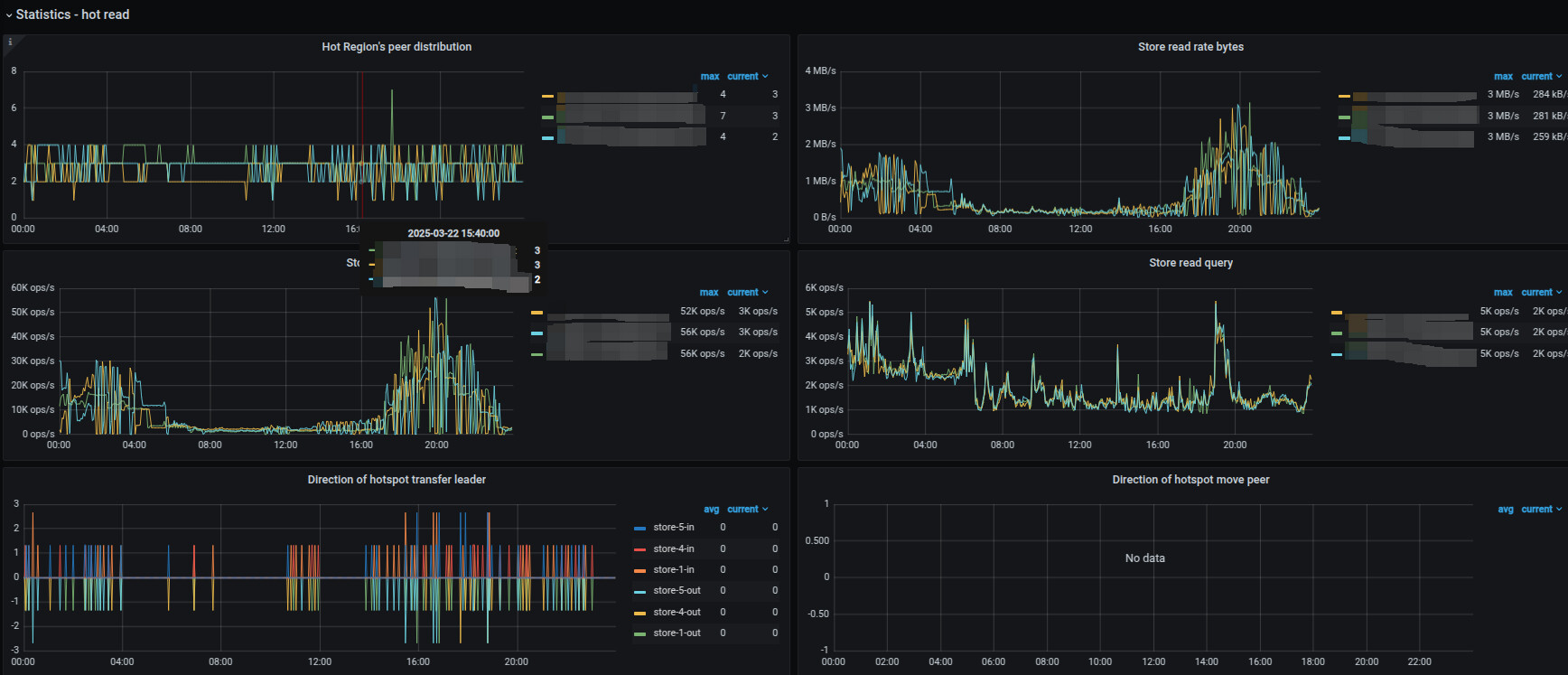
下面是hot read监控
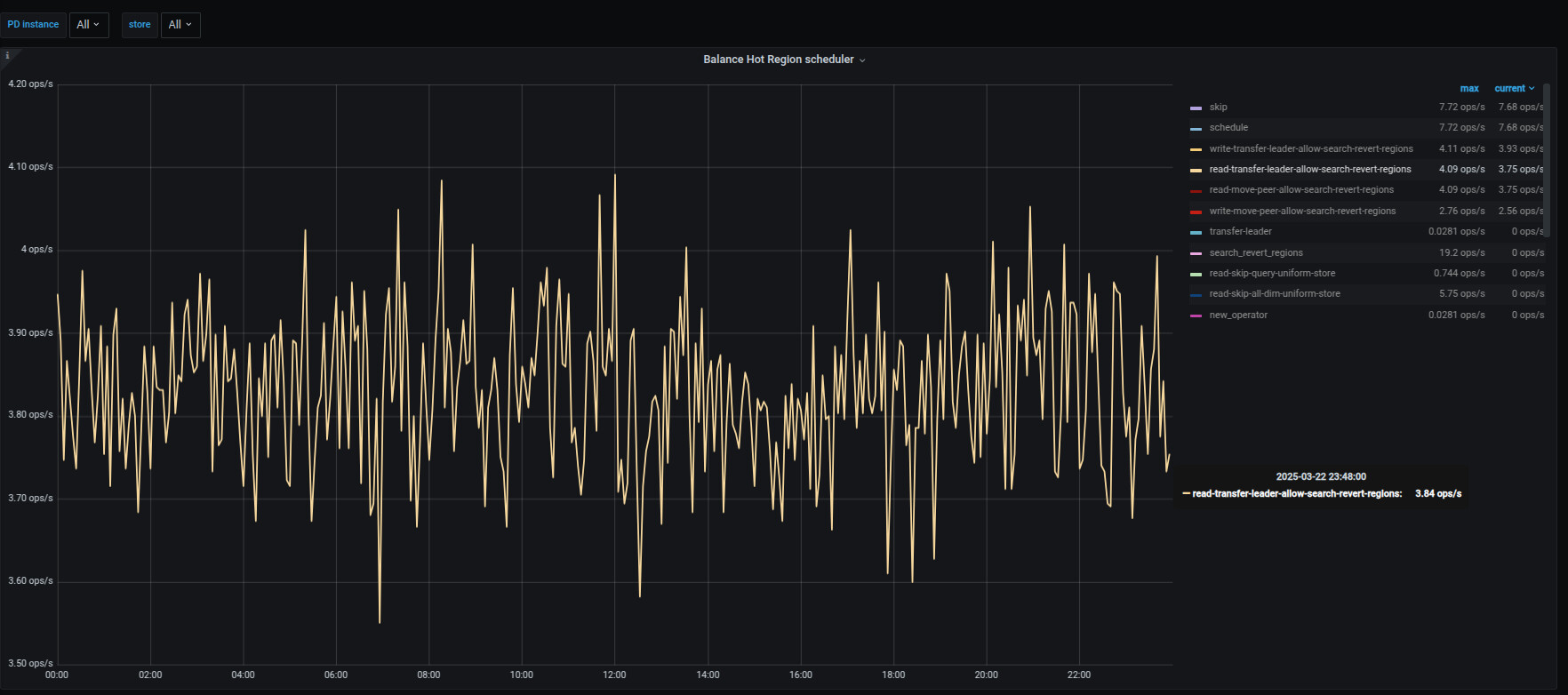
下面是scheduler监控
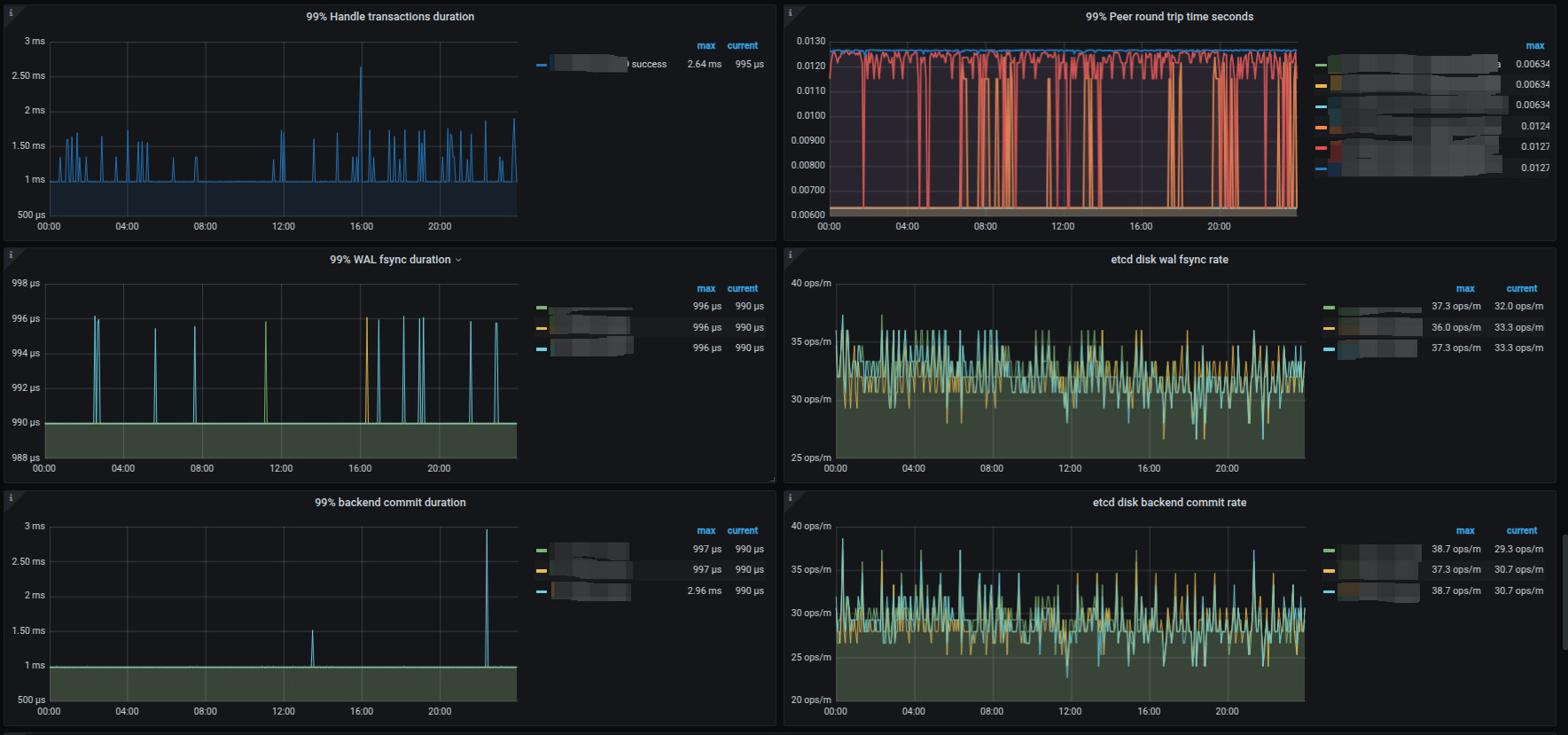
下面是etcd监控
从这里观察PD的分数都是一致的,并没有在当前看出有太大的差异。包括region的数量
想问下从这里的监控中,能否获取到什么原因导致在业务低峰期会大量触发了transfer-hot-read-leader , 这里不确定是不是参数设置不对还是其他的?
非常感谢~
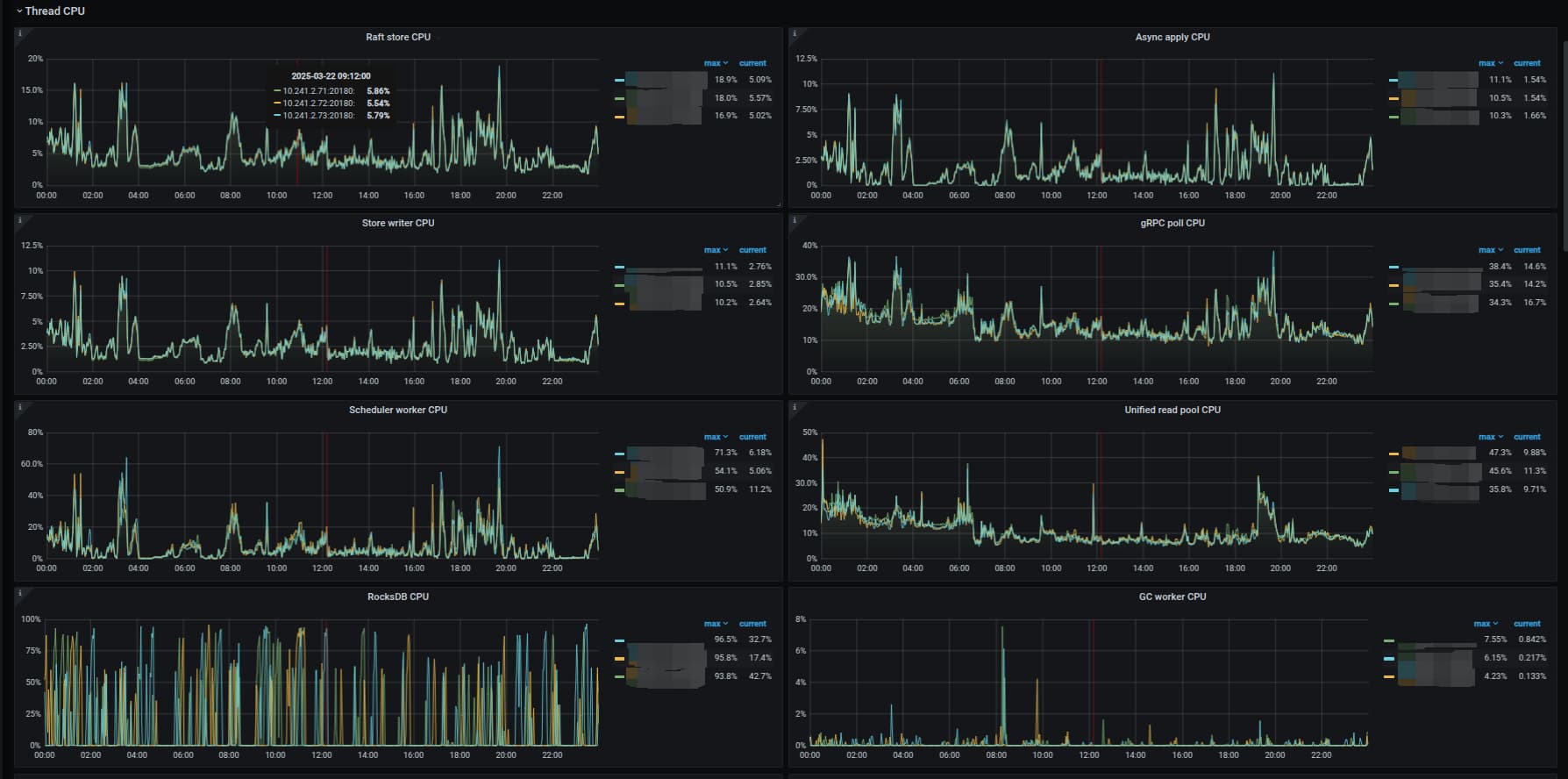
// 0326补充
补充trhead cpu监控图像
//0327信息补充
补充pd scheduler config信息
region-max-keys 1.44 Mil
region-split-keys 960.00 K
max-merge-region-keys 200.00 K
region-schedule-limit 2.05 K
region-max-size 144.00
region-split-size 96.00
replica-schedule-limit 64.00
max-snapshot-count 64.00
max-pending-peer-count 64.00
max-merge-region-size 20.00
merge-schedule-limit 8.00
leader-schedule-limit 4.00
hot-region-schedule-limit 4.00
max-replicas 3.00
hot-region-cache-hits-threshold 3.00
enable-replace-offline-replica 1.00
enable-remove-extra-replica 1.00
enable-remove-down-replica 1.00
enable-makeup-replica 1.00
low-space-ratio 0.80
high-space-ratio 0.70
tolerant-size-ratio 0

