【TiDB 使用环境】生产环境
【TiDB 版本】
【操作系统】
【部署方式】云上部署(什么云)/机器部署(什么机器配置、什么硬盘)
【集群数据量】
【集群节点数】
【问题复现路径】我有一个表6亿,在createtime字段中有索引,如果使用select * from xx where createtime>=‘2025-03-17 00:00:00’ and create time<=‘2025-03-17 09:00:00’;能命中索引,但是为什么select * from xx where createtime>='2025-03-17 00:00:00’就不能命中索引只能走全表扫描呢?
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
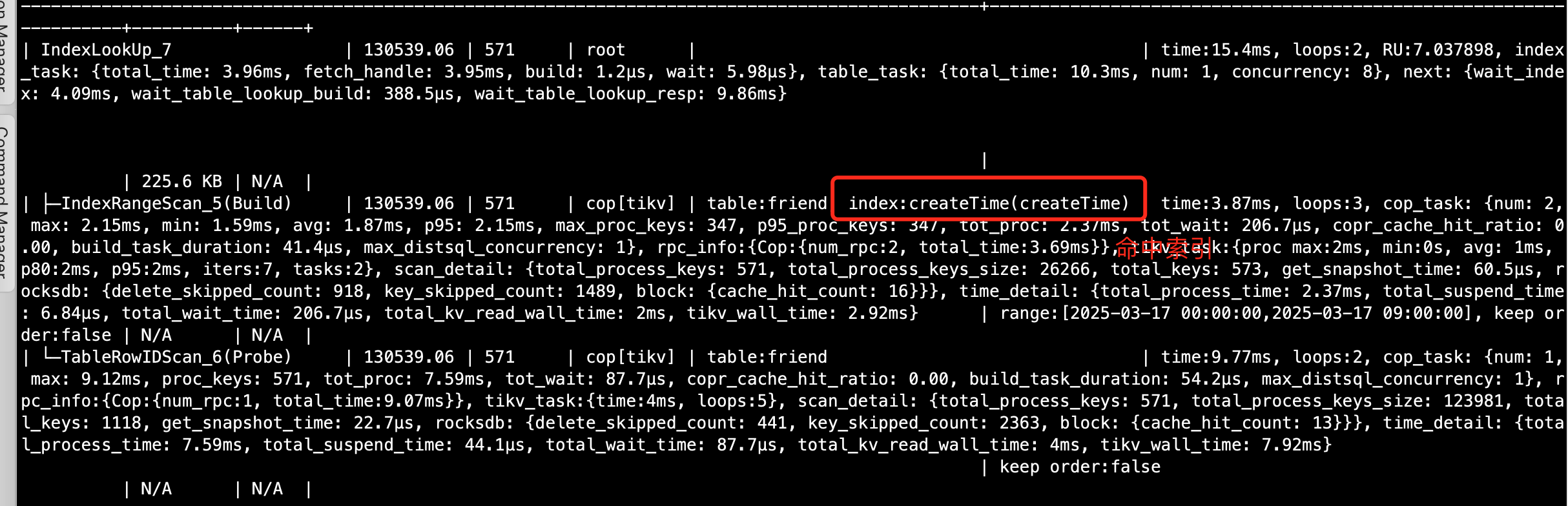
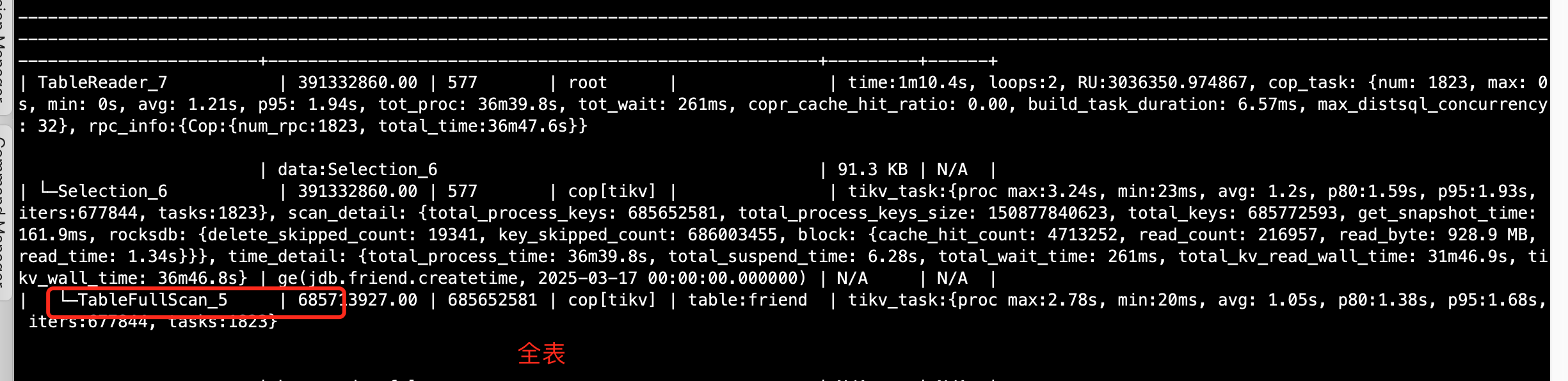
如果是mysql中应该两种写法都能命中索引,tidb刚使用请大佬解惑!
考虑命中数据量的问题,基于开销选择是否使用索引,如果命中数据量太大,通过索引再回表刘不划算了。 如果命中数据量并不大,可以考虑收集下统计信息再试试,如果还不行,可以反馈bug看看
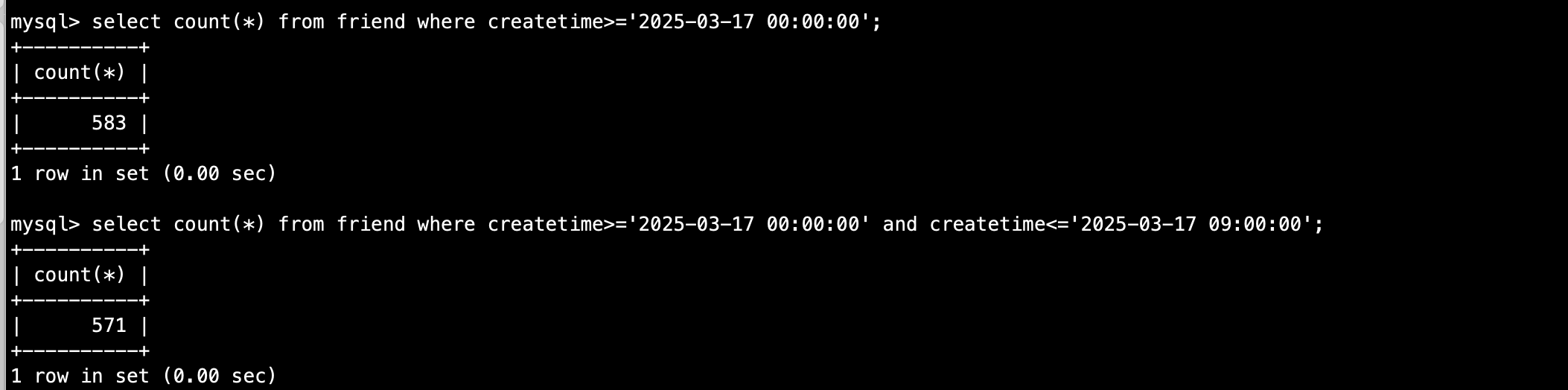
表的统计信息问题吧,你看你上面的执行计划,createtime>=‘2025-03-17 00:00:00’ and create time<=‘2025-03-17 09:00:00’预计所有要扫描的行数已经是13万了,估计cbo认为你 createtime>='2025-03-17 00:00:00’预计要扫描的行数远超13万,所以回表不值当,直接全表扫了
谢谢,表收集过几次统计信息了,还是这样。刚刚已经通过force index生成新执行计划然后再通过绑定这个执行计划来解决了
从现象上看大概率是碰到谓词越界的问题,条件里是大于某个时间点的开区间,导致有一部分时间点是落在收集统计信息之后。如果表收集完统计信息后,数据量变化很大的话,会导致modify_count值大,这样就会导致对开区间的数值估算过大,引发全表扫描。
关于谓词越界可以关注这些参数:
v7.4引入变量 tidb_opt_obiective 来让优化器忽略modify_count,这时越界估算的上界会使用选择率1/ndv(只考虑直方图部分数据)。
v8.1对越界传算又做了进一步优化https://github.com/pingcap/tidb/pull/50970

![]() 会不会存在异常数据,比如大于当前时间的数据。如果加上小于当前时间的条件,会不会走索引?
会不会存在异常数据,比如大于当前时间的数据。如果加上小于当前时间的条件,会不会走索引?