tidb小白
(Ti D Ber Emsp S Ckm)
1
【TiDB 使用环境】生产环境
【TiDB 版本】8.5.1
【操作系统】centos7.9
【部署方式】私有云
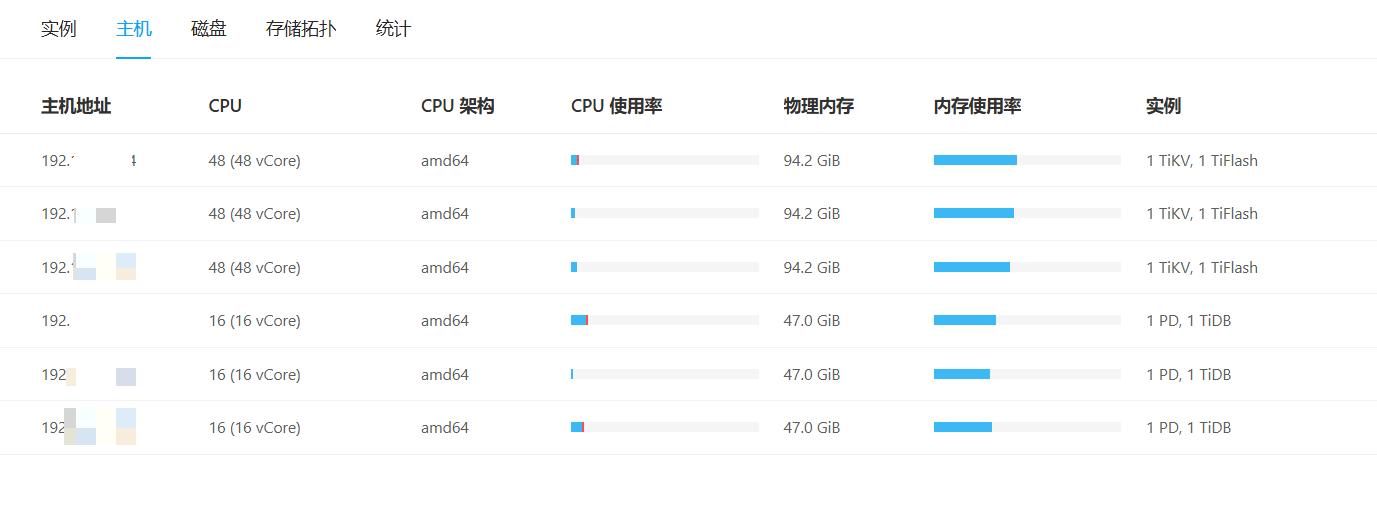
【集群数据量】
【集群节点数】6
【问题复现路径】无
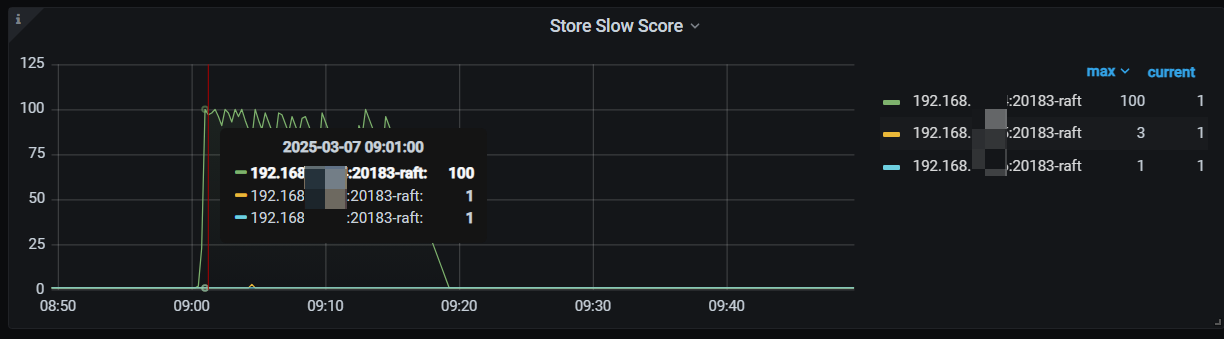
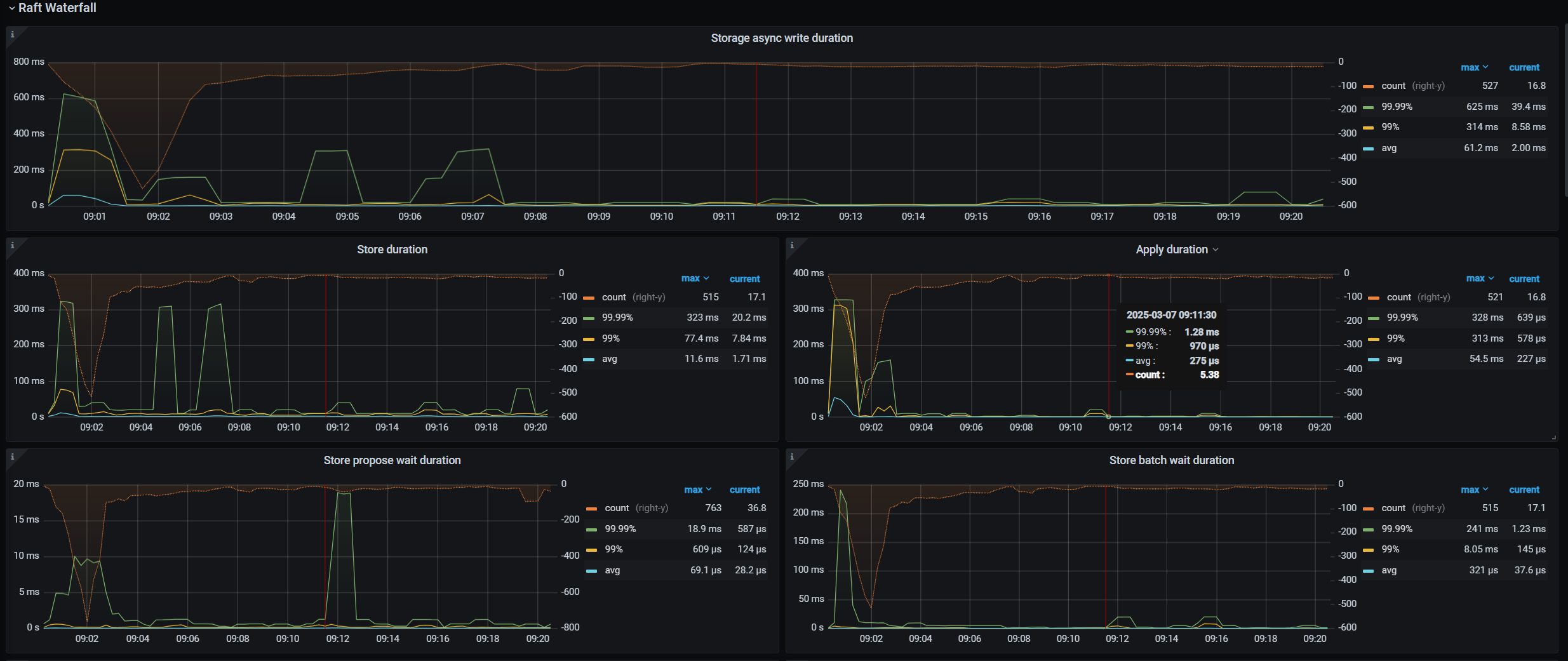
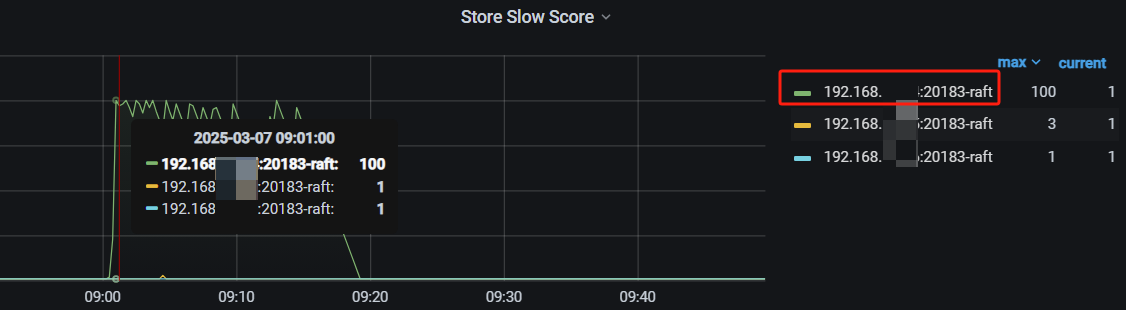
【遇到的问题:问题现象及影响】你好,我这边搭建的TIDB集群,每天早上9点多都会出现PD_cluster_slow_tikv_nums的告警问题,查看store Slow score指标,发现一个节点的得分,差不多在100左右。从SQL语句分析那里,查到每天都会一张28万左右数据的表,会进行delete全表,再insert的操作,tidb也自动执行了ANALYZE TABLE语句,想知道,这个告警,和这几个操作有关系吗

【资源配置】
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
xfworld
(魔幻之翼)
3
那是不是只有这一个节点,会出现这个问题,其他两个节点未受影响?
你需要查下关联的表了,如果是只有一个节点有影响,可能是热点问题
tidb小白
(Ti D Ber Emsp S Ckm)
4
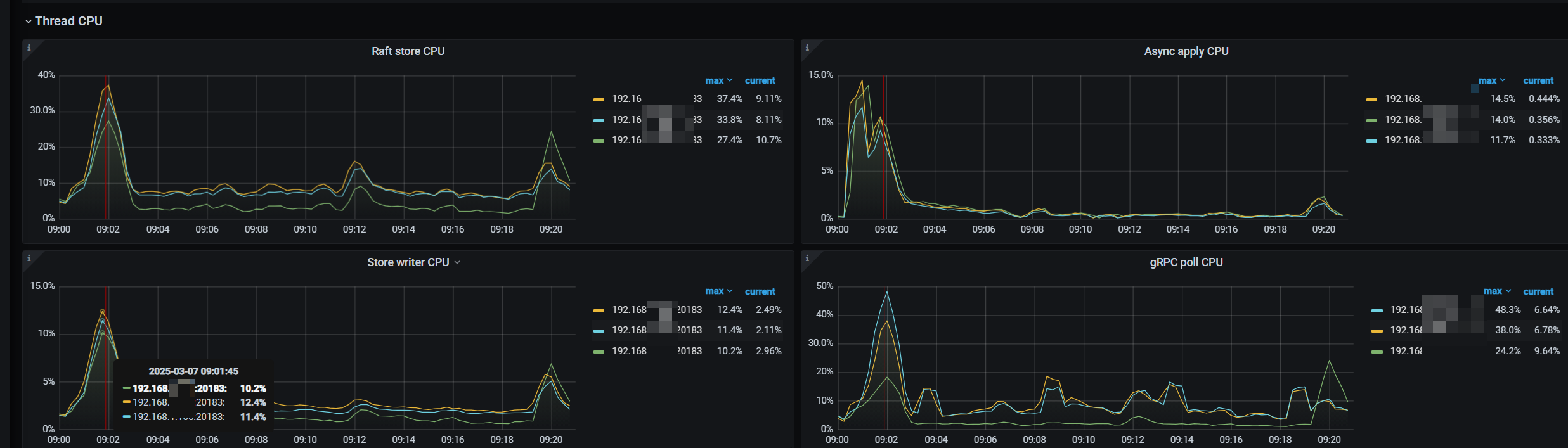
今天是这个节点,昨天不是这个,每天都有一个或者两个节点这样。持续时间也都是10-20分钟
根据是否热点问题的判断方法,查了监控,这个时候写的CPU的也没有高于其他节点,反而store slow score得分最高的节点,CPU是最低的 
tidb小白
(Ti D Ber Emsp S Ckm)
8
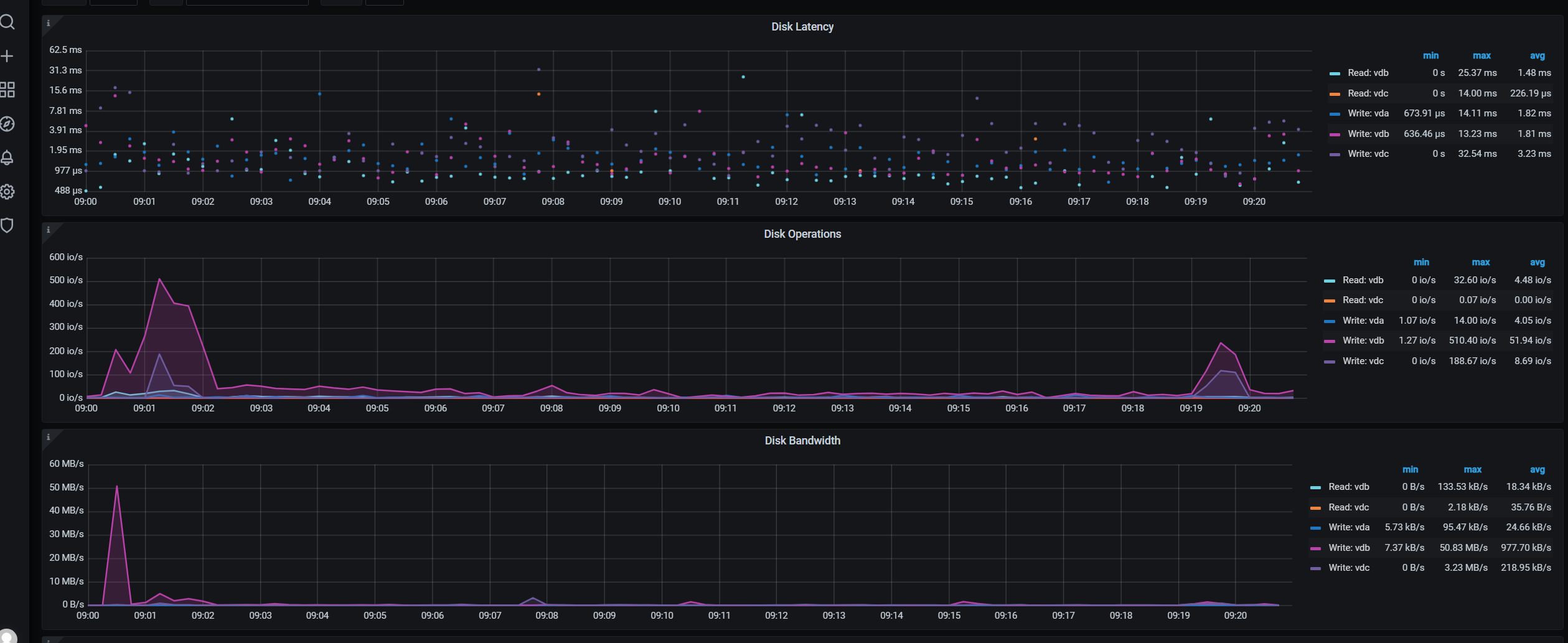
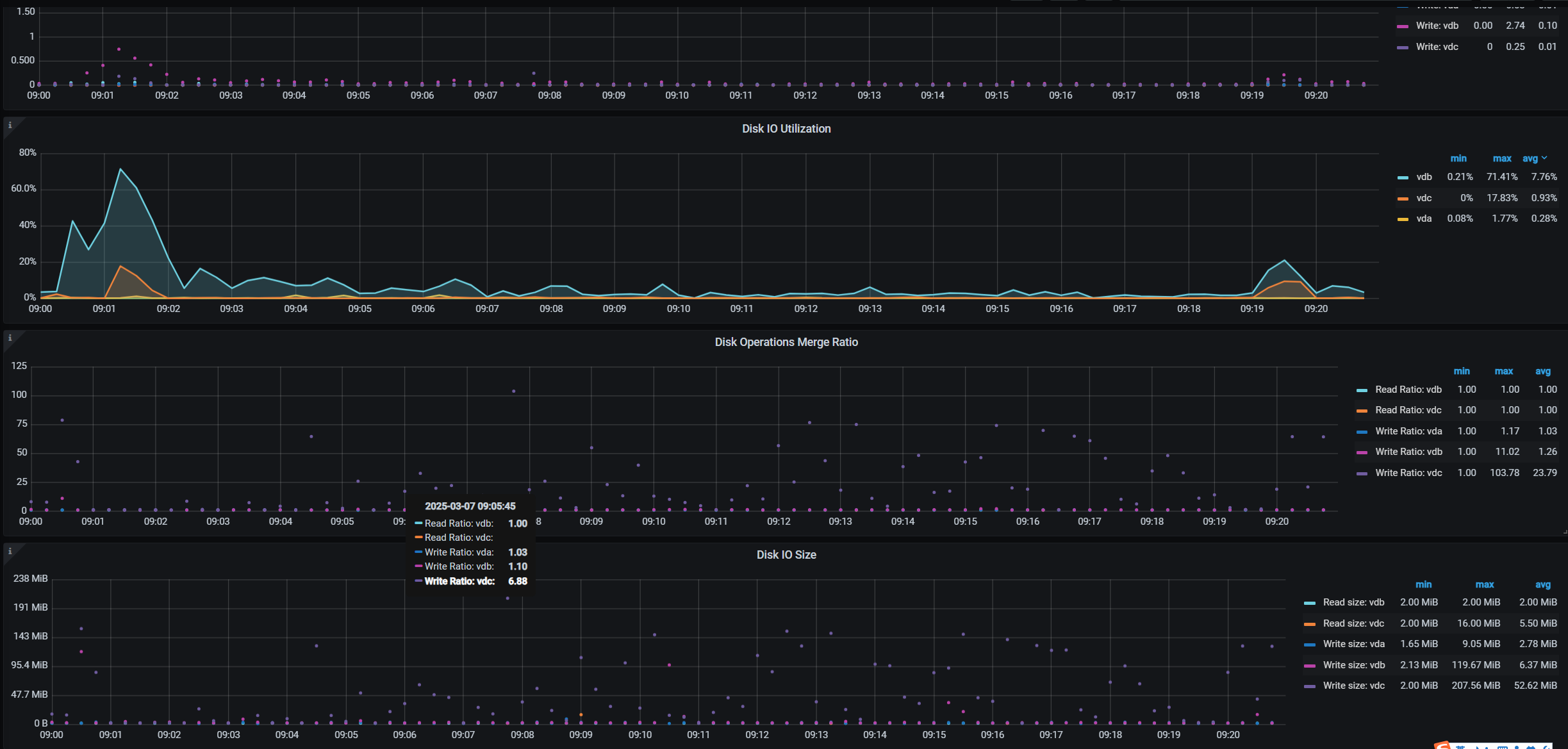
不是云盘。咱们的自己机房的,宿主机的硬盘还是SSD的
乡在人间
(Ti D Ber Ki Nyc B Fs)
10
出现PD_cluster_slow_tikv_nums告警的原因可能有多种,下面的几个都需要排查一下:
- 硬件资源限制:如果某个或某些TiKV节点所在的机器CPU、内存、磁盘I/O或网络带宽等资源使用达到瓶颈,可能会导致该节点响应变慢。
- 配置问题:不合适的TiKV配置参数(如raftstore相关配置、rocksdb配置等)可能导致性能不佳。
- 热点问题:数据分布不均造成某些TiKV节点成为读写热点,处理请求过多而变慢。
- 网络延迟:节点间网络延迟高或者不稳定也可能导致TiKV节点响应速度下降。
沧海一声笑
(Ti D Ber Z5y Lx U Kc)
11
考虑将全表的DELETE 和INSERT 替换为批量操作,或者使用TRUNCATE TABLE 替代DELETE,因为TRUNCATE 操作不记录单个行的删除,因此速度更快且对事务日志的压力更小
Kongdom
(Kongdom)
12