julyxiong
(Hacker Jsjt Zo R8)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【概述】 场景 + 问题概述
一个非常简单的表,表数据量100w。
使用select查询时,加一个非索引字段的where条件,居然比不加where条件快 10几倍。这是啥原因呢?
建表语句:
CREATE TABLE reguseridlib (
REG_UID bigint unsigned NOT NULL,
ENABLED tinyint(1) NOT NULL,
PRIMARY KEY (REG_UID) /*T![clustered_index] CLUSTERED */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
1,EXPLAIN ANALYZE SELECT reg_uid FROM yygplatform.reguseridlib WHERE enabled=1 LIMIT 29394, 1;
2, EXPLAIN ANALYZE SELECT reg_uid FROM yygplatform.reguseridlib LIMIT 29394, 1;
【TiDB 版本】
V8.5.1
V7.5
你这个表是分区表吧,你可以把execution_info字段贴全一点,看一下是哪个分区扫描的慢了。其实主要是你不带order by,limit没意义的,他是随机返回的,哪个节点返回的快都不好说
乡在人间
(Ti D Ber Ki Nyc B Fs)
8
tidb要是有sql执行跟踪就好了,看看到底怎么扫描的region,甚至更小单位粒度的跟踪,,,
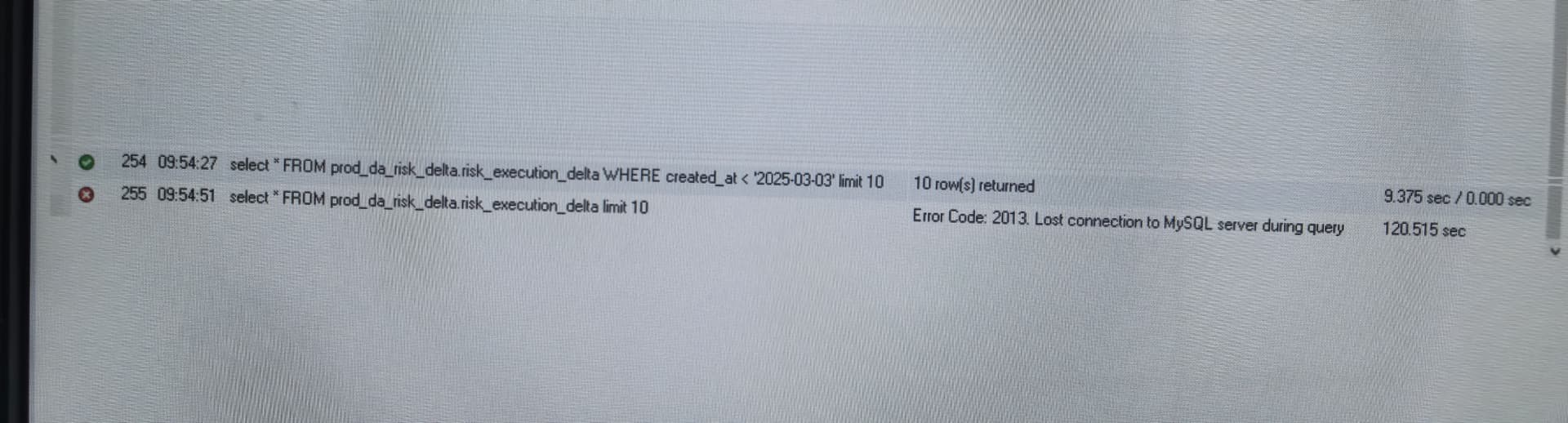
看我这个例子,都是全表扫描(其实created_at是有索引的,但是因为数据分布严重不均衡,实际走的是全表扫描)
加条件10s,不加条件120s超时
我也觉得是这样,加了where条件不得不全表扫符合条件的,然后返回第29395行数据。没加条件就任意节点扫到29395行返回。
主要你这个不加order by 里面的offset没意义啊,你29394, 1和下次29395, 1这两条不保证连续的
julyxiong
(Hacker Jsjt Zo R8)
17
同样的SQL, MYSQL 返回是us级别。
现在用的v3版本也是us级别,醉了醉了
有猫万事足
18
能给个完整的,文本的执行计划嘛?
这个看图,不太好看execution_info里面的具体信息,但是看着确实奇怪。
带where条件,其实扫描的数据更多,是34144行,不带where少了1000行,是33036行。
奇怪的是少扫了1000行反而慢了很多。这非常难理解。
从另一个角度,可以看到带where条件的时候cop_task是23个,不带where的时候cop_task只有19个。也是少了20%的。但还是慢了。
从各种角度都很难理解,execution_info里面还会包含一些扫描的key之类的信息,但是图上看不出来,我估计就是这部分的差异造成的。
所以最好能提供一个完整的,文本的执行计划。
nobody
(不定时出现)
19
底层算子都是 tablefullscan 没有变化,主要是 proc max 时间的区别, 不带 where 语句的执行时间应该不是稳定的慢吧
不带 where 语句的执行时间应该不是稳定的慢吧
还有就是关注下 执行计划里 tidb_distsql_scan_concurrency 或者 max_distsql_concurrency 的值是否有差异
沧海一声笑
(Ti D Ber Z5y Lx U Kc)
20
更新统计信息试试呢,ANALYZE TABLE reguseridlib;