【 TiDB 使用环境】生产环境
【 TiDB 版本】v7.1.3
【复现路径】
【遇到的问题:问题现象及影响】
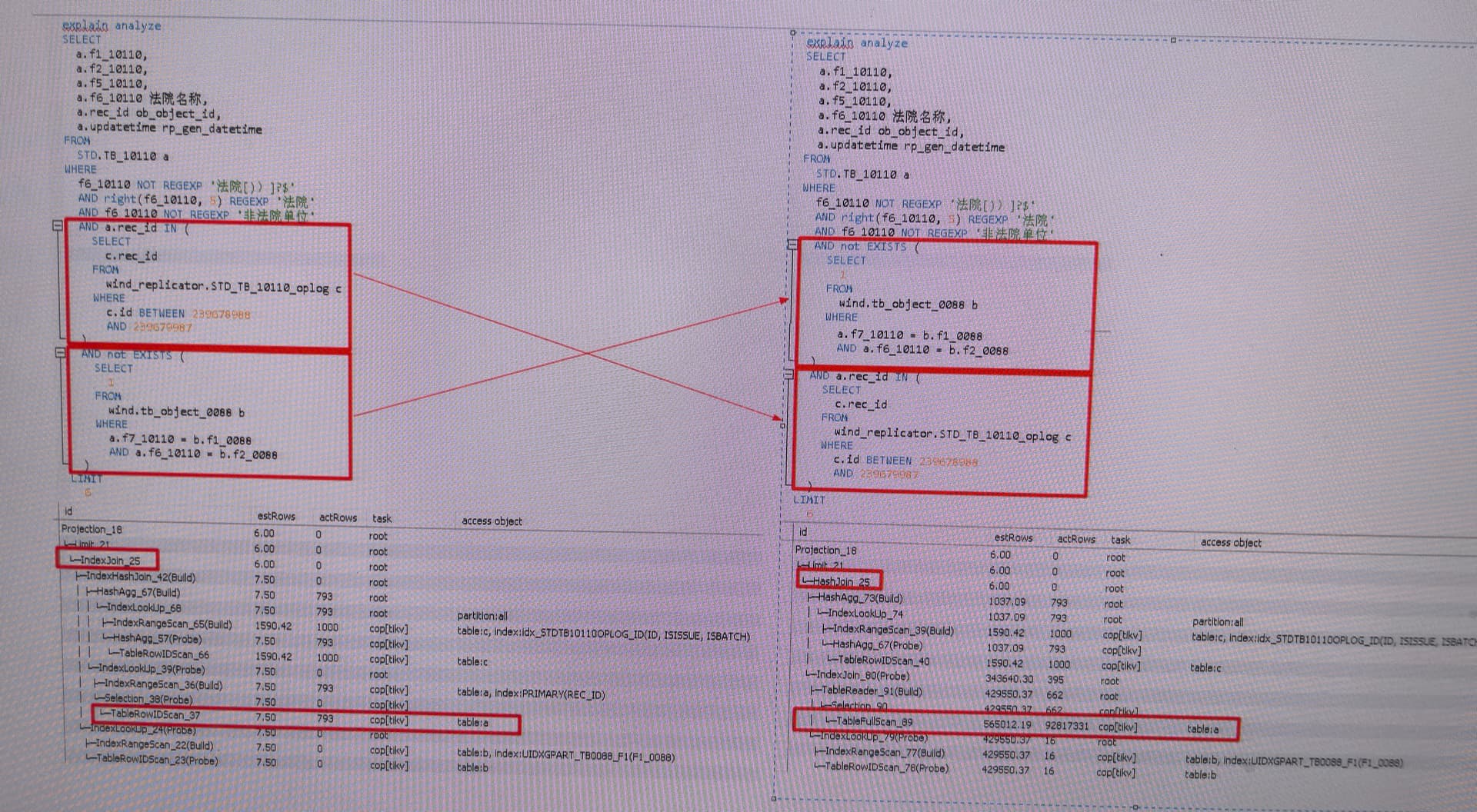
只是更换了两个条件的位置,其他内容完全一样,执行计划就大不一样了,有点颠覆我的认知了
【附件:截图/日志/监控】
【 TiDB 使用环境】生产环境
【 TiDB 版本】v7.1.3
【复现路径】
【遇到的问题:问题现象及影响】
只是更换了两个条件的位置,其他内容完全一样,执行计划就大不一样了,有点颠覆我的认知了
【附件:截图/日志/监控】
主要是你的条件里面是子查询,相当于要和别的表进行关联吧,类似你select * from a join b join c和select * from a join c join b了,你实际执行下analyze explain看下一样不,哪个更快?
带上analyze,这样的才是真实的执行计划
真实的执行计划和预估执行完全相同,前者妙出,后者需要5-10s
explain analyze 执行计划已更新,间上图
能加上表别名么?哪个字段是哪个表的,分不出来。
已更新别名
![]() 放在后面的时候没有走索引了。使用hint写法,强制走索引试试
放在后面的时候没有走索引了。使用hint写法,强制走索引试试
a表的主键为REC_ID, 强制使用主键索引都不行,还是全表扫描
select /*+ USE_INDEX(a, PRIMARY) */ a.f1_10110 …
![]() 搞不好还真是个bug,等别人看看吧。不过我们一般都是把 等号 in exists这种放在前面,不等于 not in not exists 这种放后面,默认认为条件越靠前的越先筛选。
搞不好还真是个bug,等别人看看吧。不过我们一般都是把 等号 in exists这种放在前面,不等于 not in not exists 这种放后面,默认认为条件越靠前的越先筛选。
确实好奇怪,,试试hint提示,能不能将执行计划调整一致。另外,每个子查询都单独执行以下,看看执行计划的统计信息有没有区别
涉及的表analyze分析下再看看呢
涉及的3张表全部手动analyze了,问题依旧
问了下优化器相关老师:
semi join 现在还不支持 reorder,之后在完善 outer join reorder 的同时会同时处理 semi join 了。
相关问题就会消失。
![]() 这么看还是应该规范写法,优先将能走索引的条件放在前面
这么看还是应该规范写法,优先将能走索引的条件放在前面
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。