【 TiDB 使用环境】测试/ Poc
【 TiDB 版本】7.5.3
【复现路径】做过哪些操作出现的问题
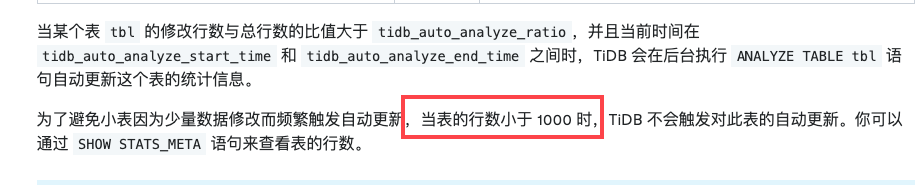
每天凌晨对 表健康度不是100的表执行 analyze table
【遇到的问题:问题现象及影响】
压测过程发现sql执行慢,查看表的健康度为 100
SHOW STATS_HEALTHY where table_name like 'account';
+----------------+------------+----------------+---------+
| Db_name | Table_name | Partition_name | Healthy |
+----------------+------------+----------------+---------+
| user_manager | account | | 100 |
+----------------+------------+----------------+---------+
查看表的统计信息 显示表行数为 401:
SHOW STATS_META where table_name like 'account';
+----------------+------------+----------------+---------------------+--------------+-----------+
| Db_name | Table_name | Partition_name | Update_time | Modify_count | Row_count |
+----------------+------------+----------------+---------------------+--------------+-----------+
| user_manager | account | | 2025-03-04 01:02:47 | 0 | 401 |
+----------------+------------+----------------+---------------------+--------------+-----------+
使用count查看实际行数为 11369 于统计信息上的相差很大:
select count(*) from account ;
+----------+
| count(*) |
+----------+
| 11369 |
+----------+
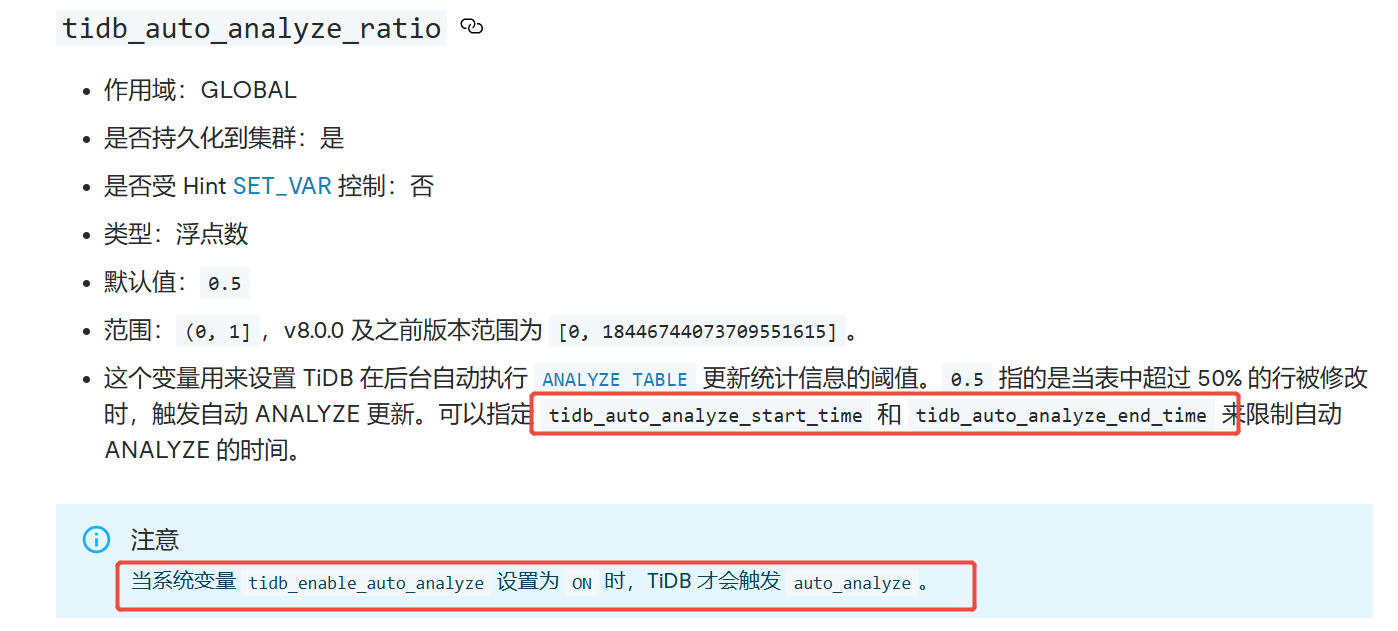
tidb相关配置:
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| tidb_auto_analyze_ratio | 0.5 |
+-------------------------+-------+
| tidb_auto_analyze_start_time | 00:00 +0000 |
+------------------------------+-------------+
| tidb_auto_analyze_end_time | 23:59 +0000 |
+----------------------------+-------------+
| tidb_persist_analyze_options | ON |
+------------------------------+-------+
查看其他表也是一样,即使健康度100但是统计信息中的行数和实际行数相差很大:
MySQL [user_manager]> select count(*) from tree_node;
+----------+
| count(*) |
+----------+
| 11892 |
+----------+
1 row in set (0.002 sec)
MySQL [user_manager]> SHOW STATS_META WHERE table_name = 'tree_node';
+--------------+------------+----------------+---------------------+--------------+-----------+
| Db_name | Table_name | Partition_name | Update_time | Modify_count | Row_count |
+--------------+------------+----------------+---------------------+--------------+-----------+
| user_manager | tree_node | | 2025-03-04 01:02:43 | 0 | 416 |
+--------------+------------+----------------+---------------------+--------------+-----------+
1 row in set (0.005 sec)
MySQL [user_manager]> show stats_healthy where table_name like 'tree_node';
+--------------+------------+----------------+---------+
| Db_name | Table_name | Partition_name | Healthy |
+--------------+------------+----------------+---------+
| user_manager | tree_node | | 100 |
+--------------+------------+----------------+---------+
1 row in set (0.008 sec)
MySQL [user_manager]> analyze table tree_node;
Query OK, 0 rows affected, 1 warning (4.338 sec)
MySQL [user_manager]> show stats_healthy where table_name like 'tree_node';
+--------------+------------+----------------+---------+
| Db_name | Table_name | Partition_name | Healthy |
+--------------+------------+----------------+---------+
| user_manager | tree_node | | 100 |
+--------------+------------+----------------+---------+
1 row in set (0.007 sec)
MySQL [user_manager]> SHOW STATS_META WHERE table_name = 'tree_node';
+--------------+------------+----------------+---------------------+--------------+-----------+
| Db_name | Table_name | Partition_name | Update_time | Modify_count | Row_count |
+--------------+------------+----------------+---------------------+--------------+-----------+
| user_manager | tree_node | | 2025-03-05 14:06:34 | 0 | 11892 |
+--------------+------------+----------------+---------------------+--------------+-----------+
1 row in set (0.002 sec)
MySQL [user_manager]> select count(*) from tree_node;
+----------+
| count(*) |
+----------+
| 11892 |
+----------+
1 row in set (0.019 sec)
多次测试 需要对这个表 手动执行一次 analyze 才能变快
问题
- 表的健康度为100的情况下 为什么还需要再执行一次 analyze 压测的sql才能变快?
- 表的健康度为100 为什么统计信息中的行数 会和实际行数相差这么大?
- 统计信息中的行数和实际行数相差很大是否会影响sql的执行速度?
- 应该使用什么方式去判断是否要对某个表执行analyze table?
- 目前我有个定时任务去每天凌晨执行一次analyze (逻辑是先检查表的健康度是不是100,对于不是100的才执行analyze) , 但是当前来看,表的统计信息实际是不准的,但是表的健康度依然是100,就无法利用这个定时任务执行analyze,争对这个问题有没有比较好的解决方案? 若直接改成不管表的健康度是不是100都执行analyze, 这样对所有库所有表都执行analyze是否会对业务造成很大的影响?
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】