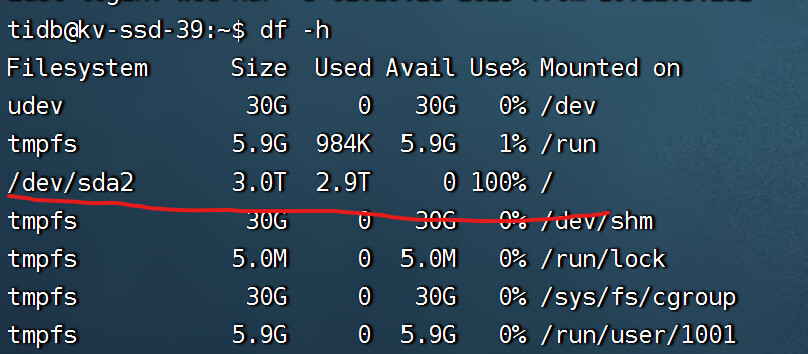
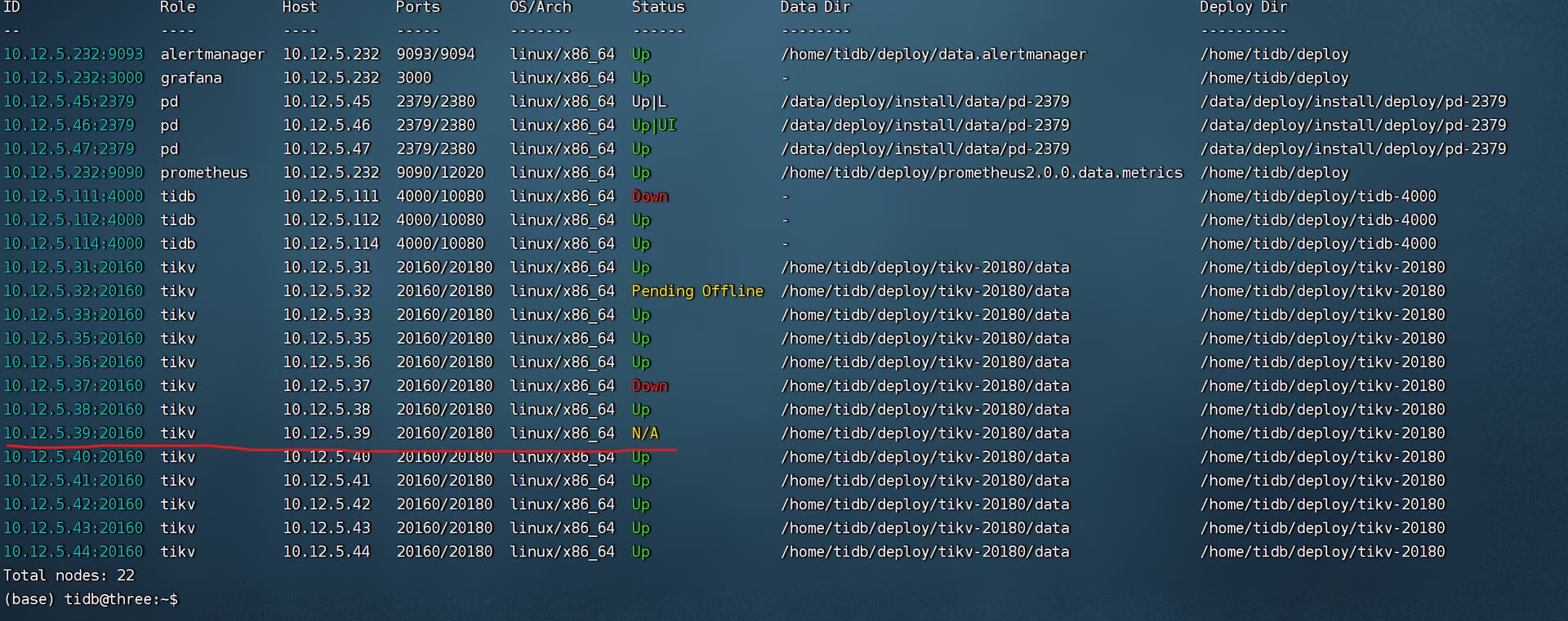
首先我查到39节点剩余一个region,查询到了该region其对应的其他两个store_id,对应kv为36和38节点。然后
根据文档专栏 - 加载中 | TiDB 社区 在36和38先stop,发现其变为disconnect状态后执行了恢复命令,
./tikv-ctl --db /home/tidb/deploy/tikv-20180/data/db unsafe-recover remove-fail-stores -s xxx -r xxx
发现如下问题
然后使用sudo,提示成功
然后查看集群状态39节点仍然为offline,region count仍然为1
现在发现上边导致 新增加了一个"raft"文件夹,进而导致36和38节点无法启动了。
我删除新增的raft文件夹后节点可以启动了
上线36和38后发现 39变为了N/A , pd-ctl store里已经没有39相关的信息了
然后进入kv39查看,发现空间仍然被占满了,请问这种下线的结果正常吗?我能否重新直接scale out kv39节点,继续使用kv39?
乡在人间
(Ti D Ber Ki Nyc B Fs)
2
可以尝试先scale-in kv39,再重新scale out 39回来
舞动梦灵
(Ti D Ber Nckmz Hmh)
3
1.变成N/A 有可能是已经收缩掉了, 但是你磁盘使用2.98T 使用了100% 感觉又没有收缩。
我所有收缩的,都是吧收缩掉的那个tikv服务器数据迁移走了。最后只有几百兆使用。才是正常的。
2.你这个N/A也有可能是磁盘使用100%,无法使用出现的异常。
3.任何情况下,磁盘都不能低于100G,否则在操作tidb的时候极有可能因为磁盘不够导致其他各种问题。
xfworld
(魔幻之翼)
4
tidb 监控体系会对 tikv 的可用容量有比较强制的监控和使用措施,怎么弄成 100% 的?
有猫万事足
5
不正常,本来等着32 pending offline的问题解决,可能还有的救。
你这么搞,那就是人为制造问题了。
你想啊,这个regoin的raft组在36,38,39.你非要把36,38关掉,破坏这个3副本,再使用unsafe recovery让这个region恢复,这没有意义的啊。
39状态是offline。我感觉你直接scale out应该是没什么大问题的,另一个帖子的39日志上看错误也主要是和32和37连不上,37是已经坏了,32pending offline。你就等32迁移完了,再用unsafe recovery是最有可能把集群救起来的。
你现在这么操作一番是人为增加了恢复的困难。
别乱搞了,赶紧把32迁移完,你另一个帖子里面我就感觉你乱了,另一个帖子里面写32调了remove-peer的速度,这对迁移作用不大,因为add-peer是15,那迁移的速度就快不了。把add-peer调到500.赶紧让32 offline,再看那个regoin副本不够,再尝试unsafe recovery。这就是最有可能把集群救起来的方式。