【 TiDB 使用环境】测试
【 TiDB 版本】
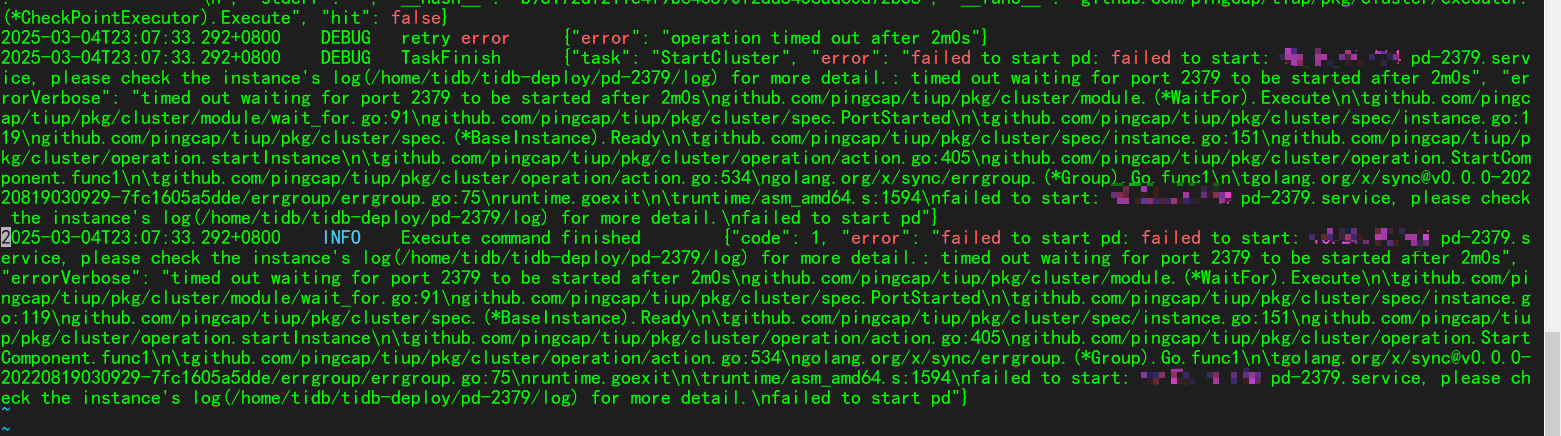
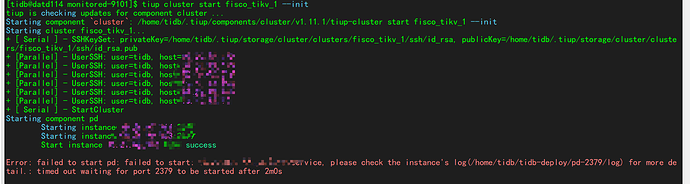
【复现路径】启动集群失败
【遇到的问题:问题现象及影响】集群部署启动失败-部署两台机器,主那台的服务一直起不来
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
救救孩子,几个小时了,没搞出来为啥
有猫万事足
2
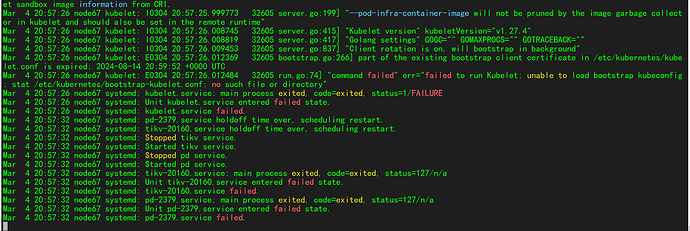
这个instance’s log里面有什么线索没?
instance’s log里空的,tiup-cluster-debug日志是如上
有猫万事足
5

pd启动失败前,kubelet已经报错了。是这个问题导致的通信中断吧。
备节点都没有kubelet这个服务,这个可能是以前安装的残留,会影响吗
乡在人间
(Ti D Ber Ki Nyc B Fs)
7
测试环境,最好保持干净,不然有时会遇到一些奇奇怪怪的错误
诶,之前其他人部过一次,可能有一部分这原因吧,现在找不到处理方法 
小龙虾爱大龙虾
(Minghao Ren)
9
kubelet 不是也用 etcd 吗,端口号也是 2379 端口吧,你把 tidb 集群的 pd 端口换一个
小龙虾爱大龙虾
(Minghao Ren)
11
看这里的对应节点的 /home/tidb/tidb-deploy/pd-2379/log 下的日志,你换了端口,目录可能不一样
舞动梦灵
(Ti D Ber Nckmz Hmh)
12
你是用tiup安装的吗?
2台机器。你怎么分布的?1台 tidb pd monitor 1台tikv这样吗?
建议铲掉,重新安装吧。感觉像是tikv数量问题,tikv你是搞了1个副本,还是同1个服务器搞了3个分区作为他的副本。
嗯嗯用的的tiup,两台分别都有 tidb pd monitor tikv。清除后重新安装,只留一台机器,还是报同样的错
舞动梦灵
(Ti D Ber Nckmz Hmh)
14
如果你只用一台安装,用快速上手这里的操作,配置文件里面写好IP对应的服务,那就如下图所示,所有服务写一个IP,就算有2台,monotor也是写1个,pd和tikv服务不能只写2个ip要么1个要么3个以上。 你把yaml文件发下看看
# Global variables are applied to all deployments and used as the default value of
# the deployments if a specific deployment value is missing.
global:
user: “tidb”
ssh_port: 22
deploy_dir: “/home/tidb/tidb-deploy”
data_dir: “/home/tidb/tidb-data”
monitored:
node_exporter_port: 9100
blackbox_exporter_port: 9115
deploy_dir: “/home/tidb/tidb-deploy/monitored-9100”
data_dir: “/home/tidb/tidb-data/monitored-9100”
log_dir: “/home/tidb/tidb-deploy/monitored-9100/log”
server_configs:
tidb:
log.slow-threshold: 300
pd:
replication.location-labels: [“host”]
schedule.leader-schedule-limit: 4
schedule.region-schedule-limit: 2048
schedule.replica-schedule-limit: 64
/* pd:
replication.location-labels: [“host”]
schedule.leader-schedule-limit: 4
schedule.region-schedule-limit: 2048
schedule.replica-schedule-limit: 64 */
pd_servers:
- host: 10.0.0.1
ssh_port: 22
name: “pd-1”
client_port: 2379
peer_port: 2380
deploy_dir: “/home/tidb/tidb-deploy/pd-2379”
data_dir: “/home/tidb/tidb-data/pd-2379”
log_dir: “/home/tidb/tidb-deploy/pd-2379/log”
/* - host: 10.0.0.2
ssh_port: 22
name: “pd-2”
client_port: 2379
peer_port: 2380
deploy_dir: “/home/tidb/tidb-deploy/pd-2379”
data_dir: “/home/tidb/tidb-data/pd-2379”
log_dir: “/home/tidb/tidb-deploy/pd-2379/log” */
tidb_servers:
- host: 10.0.0.1
ssh_port: 22
port: 4000
status_port: 10080
deploy_dir: “/home/tidb/tidb-deploy/tidb-4000”
log_dir: “/home/tidb/tidb-deploy/tidb-4000/log”
numa_node: “0”
/* - host: 10.0.0.2
ssh_port: 22
port: 4000
status_port: 10080
deploy_dir: “/home/tidb/tidb-deploy/tidb-4000”
log_dir: “/home/tidb/tidb-deploy/tidb-4000/log”
numa_node: “0” */
tikv_servers:
- host: 10.0.0.1
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: “/home/tidb/tidb-deploy/tikv-20160”
data_dir: “/home/tidb/tidb-data/tikv-20160”
log_dir: “/home/tidb/tidb-deploy/tikv-20160/log”
numa_node: “0”
config:
server.labels: { host: “tikv1” }
/* - host: 10.0.0.2
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: “/home/tidb/tidb-deploy/tikv-20160”
data_dir: “/home/tidb/tidb-data/tikv-20160”
log_dir: “/home/tidb/tidb-deploy/tikv-20160/log”
numa_node: “0”
config:
server.labels: { host: “tikv2” } */
单台的配置是这样的,一开始两台部署的配置就是把注释取消了。我是看部署后deploy文件夹里均有tidb pd monitor tikv
如果是测试环境简单测试的话,建议直接用tiup playground v6.5.8 --host 0.0.0.0 --tag smk-test --without-monitor --tiflash 0命令一键启动吧,一台机器没啥好集群部署的。
最终还是要部署多台的,我这是部署失败了,所以试了一下一台的,没想到也失败了 
清风明月
21
还是pd所在的2379没有起来啊,进服务器看下目录日志文件呢。