【 TiDB 使用环境】生产环境
【 TiDB 版本】4.0.10
【复现路径】tidb-server下线
【遇到的问题:问题现象及影响】 遇到集群整体响应变高
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
部署描述
1.tidb-server使用容器部署
2.进行下线时,会有60s的优雅退出时间
3.下线时,会先进行摘流
4.同时会新增一个tidb-server节点
遇到的问题
1.集群整体耗时变高,慢查询并没有集中在某个tidb-server
求解答
1.tidb-server下线为什么会引起集群抖动,应该怎么样避免
有猫万事足
4
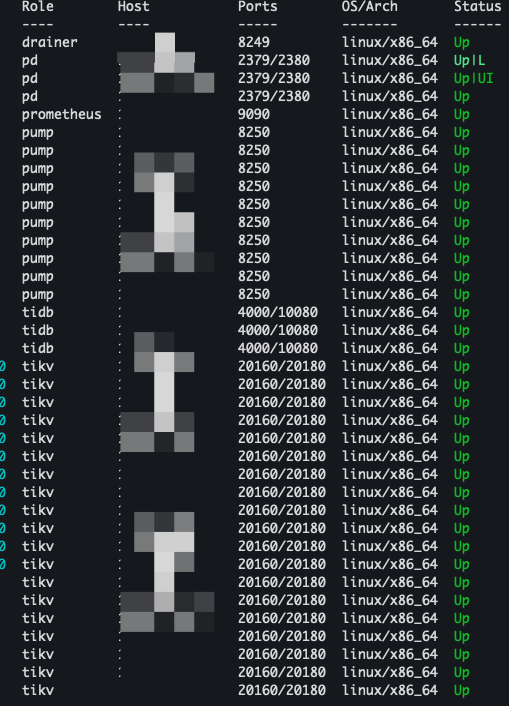
能补充一个集群拓扑嘛?
我一开始怀疑是连接没有关闭,优雅退出的流程可能有些问题,但是看到你这个描述我就想不通了。
除非是tidb-server影响了pd,或者影响到了查询扫描的数据集中在某个tikv上,不然是不应该出现这个问题的。慢查询应该都和下线的这个tidb节点有关才对。
另外就是4.0版本已经EOL的,最好是找个时间升级一下,有的问题升级之后就没有了。
https://cn.pingcap.com/tidb-release-support-policy/
这里物理机的拓扑,还有容器上的30个tidb-server
补充一下,分析日志,慢查询耗时也没有集中在某个kv
1 个赞
有猫万事足
7
那就常规一点,你看看这个
https://docs.pingcap.com/zh/tidb/stable/performance-tuning-methods#如果瓶颈在-tidb-内部如何定位
- 按 SQL 处理的 4 个步骤(即 get_token/parse/compile/execute)分解,判断哪个步骤消耗的时间最多。对应的分解公式为:
DB Time = Get Token Time + Parse Time + Compile Time + Execute Time
看看这4个阶段那个阶段慢,往下分解。
有猫万事足
9
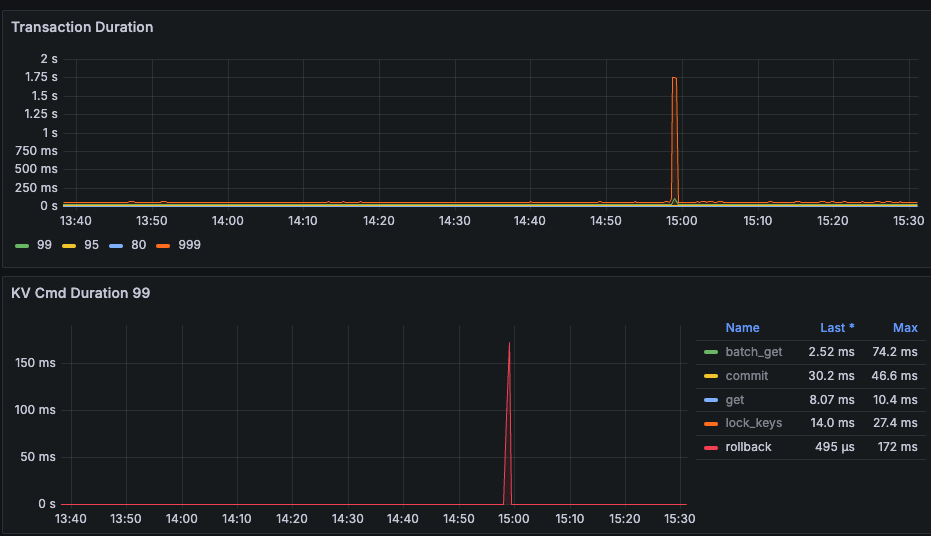
没懂什么意思,其实看图也就p999升高到2s。也就1/1000的影响。从p99看平均250ms都没到。
对,就抖动了下,只是不知道为什么抖动,业务有影响,尽可能避免这种抖动
有猫万事足
11
这个查不出来是怎么回事?是延迟拆解不下去,还是找不到看那个图?
另外你要做到扩容缩容时,业务完全无感,可能需要tiproxy,但这个组件需要更高的tidb版本才能支持。
https://docs.pingcap.com/zh/tidb/stable/tiproxy-overview#连接迁移
连接迁移通常发生在以下场景:
- 当 TiDB server 进行缩容、滚动升级、滚动重启操作时,TiProxy 能把连接从即将下线的 TiDB server 迁移到其他 TiDB server 上,从而保持客户端连接不断开。
- 当 TiDB server 进行扩容操作时,TiProxy 能将已有的部分连接迁移到新的 TiDB server 上,从而实现了实时的负载均衡,无需客户端重置连接池。
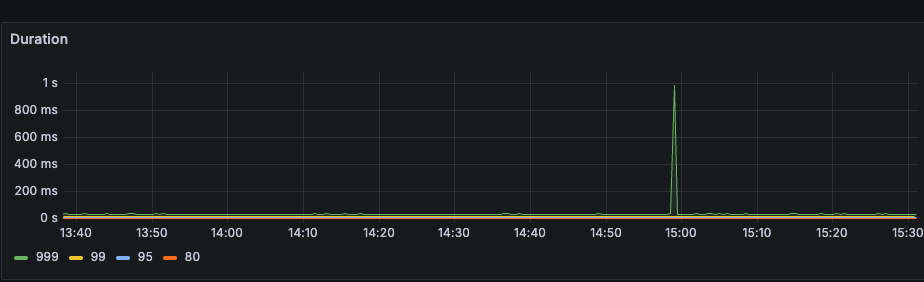
嗯嗯,了解。目前版本确实很低了。拆解不下去了,慢的阶段是在kv层
1 个赞
不过我们这边,上层有自己实现的proxy,理论上跟这个功能类似
有猫万事足
14
https://docs.pingcap.com/zh/tidb/stable/latency-breakdown
对照这个分读写,尝试往下拆解看看吧。到tikv这层往下拆确实是有点难度的。
另外代理的问题,最好也能排除一下,我感觉还是升级后,用tiproxy替代常用代理,看是否还有这类问题,是最能排除代理的潜在问题的一种方式。
2 个赞
乡在人间
(Ti D Ber Ki Nyc B Fs)
16
一、核心抖动触发机制
当 TiDB-Server 节点下线时,可能触发以下四类集群抖动:
-
分布式事务雪崩效应
正在处理的分布式事务因节点下线中断,触发 TiDB 事务管理器的自动重试机制。大量事务重试请求会集中冲击其他 TiDB-Server 节点,导致其工作线程池(如 Golang 的 Goroutine 调度器)出现调度延迟。典型表现为tidb_retry指标突增和process_cpu_usage瞬时冲高。
-
PD 元信息更新延迟
TiDB-Server 注册信息在 PD 的 etcd 存储中存在心跳保活机制(默认 2 秒 TTL)。节点下线后,PD 需要完成 Leader 重新选举(通过 Raft 协议)和路由表更新。若 PD 节点高负载时,元信息同步延迟会导致客户端出现短时路由错误,触发ErrTiKVServerTimeout连锁反应。
-
TiKV Region 负载突变
每个 TiDB-Server 维护本地 Region 缓存(Region Cache)。节点下线后,客户端连接池(如 Go-TiDB 的connPool)会重新建立到其他 TiDB-Server 的连接,导致这些节点同时发起 Region Cache 预热操作,引发 TiKV 的batch_requests量激增。若未开启流控,可能触发 TiKV 的server_is_busy保护机制。
-
内存回收竞争
突然释放大量连接资源(如每个 TiDB-Server 默认维持 1,600 个连接)会导致 Go 运行时内存回收器(GC)出现 STW 停顿。通过 Go 的GODEBUG=gctrace=1日志可观测到GC forced标记,此时业务 SQL 的execution_latency会出现尖峰。
1 个赞
system
(system)
关闭
17
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。