【 TiDB 使用环境】生产
【 TiDB 版本】v7.5.1
【复现路径】业务正常变更
【遇到的问题:问题现象及影响】tikv监控来看突增突降
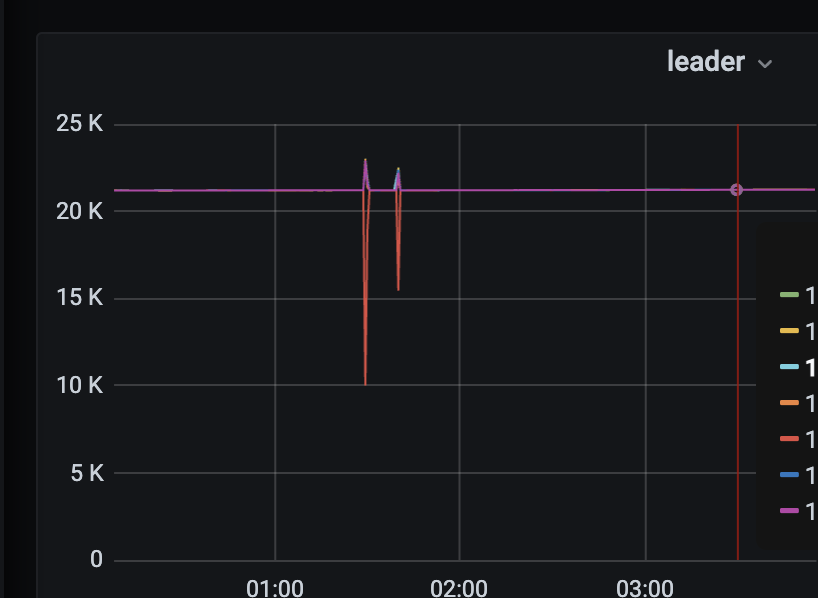
tikv的leader监控
变动时会有一些slow_tikv_nums的告警
概要: [critical] PD_cluster_slow_tikv_nums
集群: sirius-tidb-lxgzpri
彬彬之前有提到过类似显现,io压力过大,导致leader频繁变动
【 TiDB 使用环境】生产
【 TiDB 版本】v7.5.1
【复现路径】业务正常变更
【遇到的问题:问题现象及影响】tikv监控来看突增突降
tikv的leader监控
变动时会有一些slow_tikv_nums的告警
概要: [critical] PD_cluster_slow_tikv_nums
集群: sirius-tidb-lxgzpri
彬彬之前有提到过类似显现,io压力过大,导致leader频繁变动
监控里面,
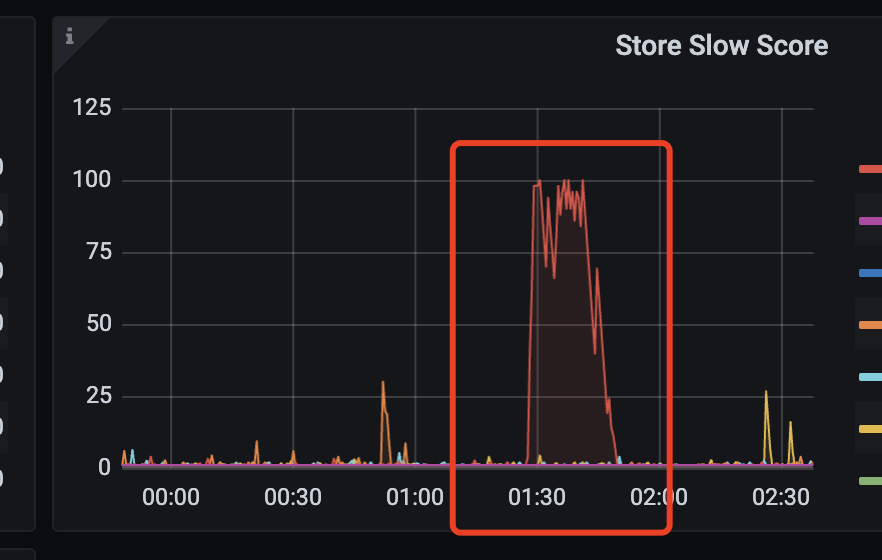
tikv-detail >> pd >> Store slow score 面板对应时间啥样的?
哦 那应该是判定相关节点是 slow store 节点,进行了 leader 驱逐。
https://docs.pingcap.com/zh/tidb/stable/pd-scheduling-best-practices#tikv-节点故障处理策略
你可以删除对应策略。
看了下文档,这个分数和判定时间好像无法调整,如果把这个调度删除会出现真的慢的时候拖慢集群的影响么,而且这个驱逐后又很快补回来的现象感觉有点怪,这个操作后感觉也会导致tikvclient的重试次数
嗯呢,这个之前也看了,但是我这个80分以上的应该超过30秒了,这里还是想确定下,对于这种高压的场景(预计持续10-30min),是让leader如现在这种切换更好呢,调高阈值,让leader不做切换更好
这就看你们能接受哪个了。
好的,感谢大佬,我这里仔细对比了下监控,目前来看起来是因为对应kv节点的cpu较高导致的,当前情况下除了tikv_client重试次数升高外,99,999没有明显变化,暂时不做处理了
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。