【 TiDB 使用环境】生产环境
【 TiDB 版本】V6.5.2
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
TiKV主机是8C16G,并且storage.block-cache.capacity也配置了4G,
±-----±------------------±-----------------------------±--------+
| Type | Instance | Name | Value |
±-----±------------------±-----------------------------±--------+
| tikv | xxx:20160 | storage.block-cache.capacity | 4000MiB |
| tikv | xxx:20160 | storage.block-cache.capacity | 4000MiB |
| tikv | xxx:20160 | storage.block-cache.capacity | 4000MiB |
±-----±------------------±-----------------------------±--------+
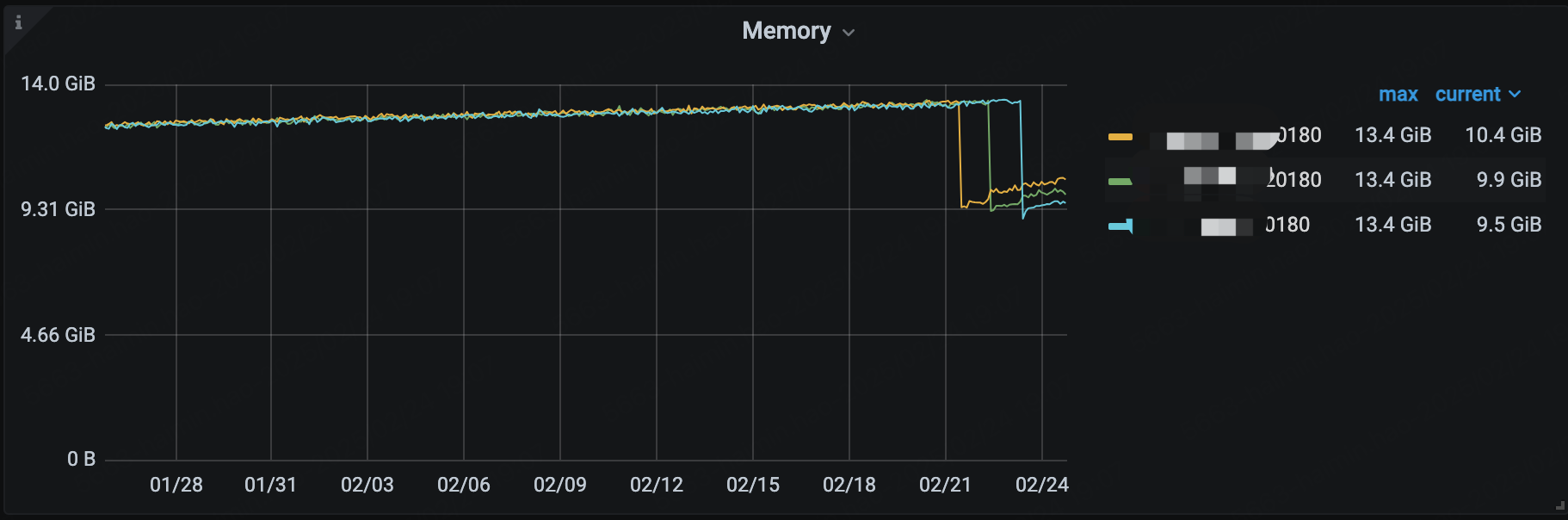
见监控截图,内存是缓慢增长最终触发oom,影响到了业务,如何排查是什么内存增长的
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
你限制一下内存
看一下 top sql
已经限制过了

隔一段时间抓一个内存的火焰图,对比下哪部分内存涨的比较高
1 个赞
看下top SQL 和慢SQL ,按对应时间查看,比较好排查
机器上是不是还跑了别的服务,tikv oom后内存没掉到0,从最高点到最低点差不多是4G,应该是有别的服务占用了内存
2 个赞
集群拓扑结构发下呢,你这tikv已经oom了,内存释放了,总的内存还有9G被占用?
1 个赞
这是监控图显示的问题,这个是放大的图
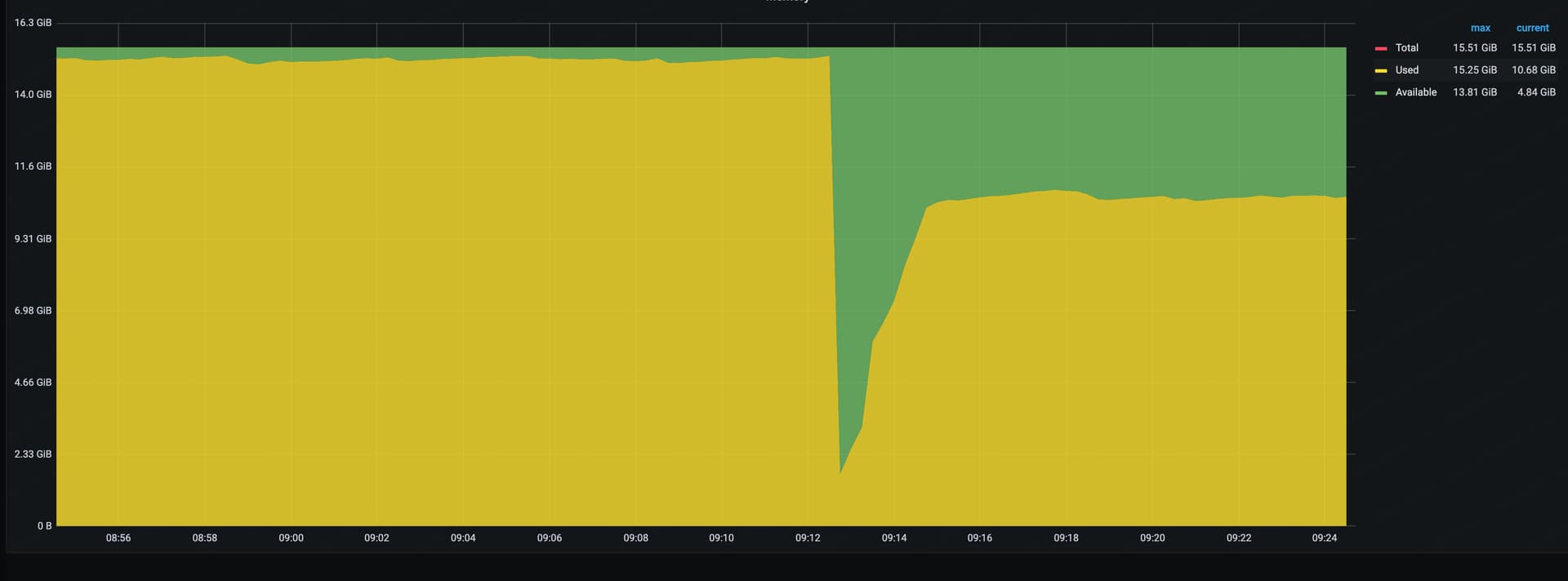
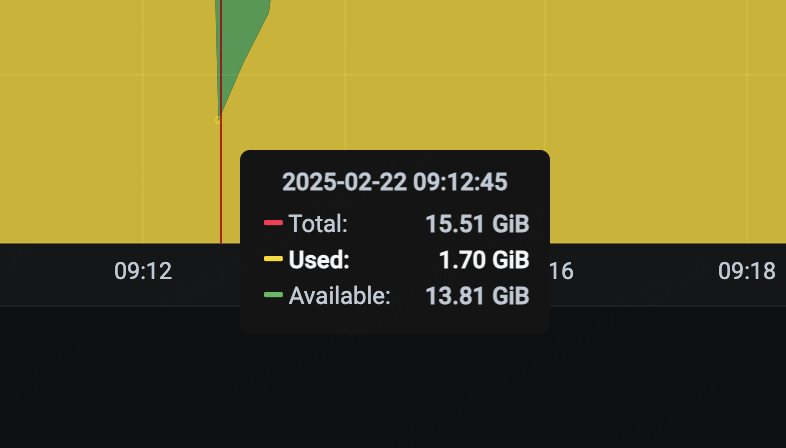
在系统日志里查到了同一时间点,两次out of memory
Feb 22 01:12:25 kernel: Out of memory: Kill process 10845 (tikv-server) score 879 or sacrifice child
Feb 22 01:12:25 kernel: Out of memory: Kill process 10860 (grpc-server-4) score 879 or sacrifice child
1 个赞
目前能看到的信息还是比较少,可以从一下几个点排查:
最首先的是慢 sql 层面,可以通过 dashboard 界面 slow query 界面 max-mem 看一看。同时有 OOM 的话 会记录 OOM record 中的 runningsql 去定位。tidb.log故障时间段的 expensive query 去定位。
其次通过下面的方法去定位一些其他原因
1.tikv 所在服务器 region 会占一些 memory,你看看集群数据量是不是比较大,10K region 大概消耗 500M 内存;
2. memtable ( tikv details / rocksdb kv / memtable size)
3. ticdc TiCDC Old Value Cache / Sink Size (TiCDC / TiKV / CDC memory → old-value and sink)
4. raftstore memtrace ( tikv details / server / memory trace → raftstore)
5. TiKV 无负载下启动常驻 =~ 1.3G
1 个赞
内存偏低,需要根据具体sql详情分析、比如用到大表查询。临时表等。
granfana监控中 process_resident_bytes (进程占用的物理内存)、tikv_memtable_size (MemTable大小)、tikv_block_cache_size (RocksDB block cache大小)这些指标有吗?可以看看这些指标的变化