不输土豆
(Ti D Ber Lkg Kt Rt P)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v8.5.1
【复现路径】扩容了一些3个 tikv-server,发现在leader 迁移到这些节点的过程中,leader 数量会在某个时刻被置为0,过了一会又恢复了。
【遇到的问题:问题现象及影响】
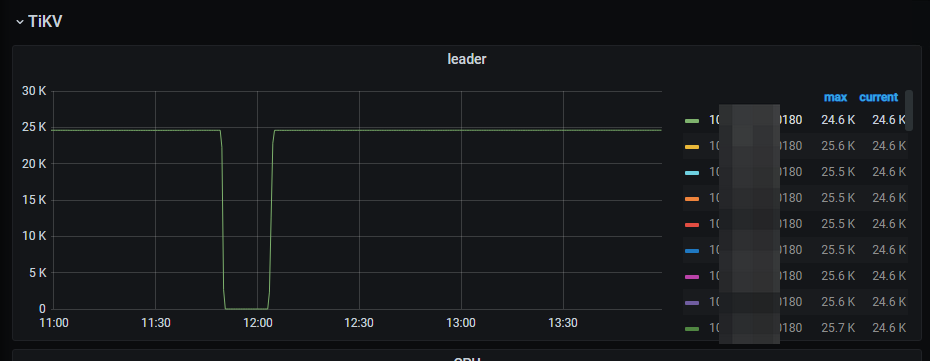
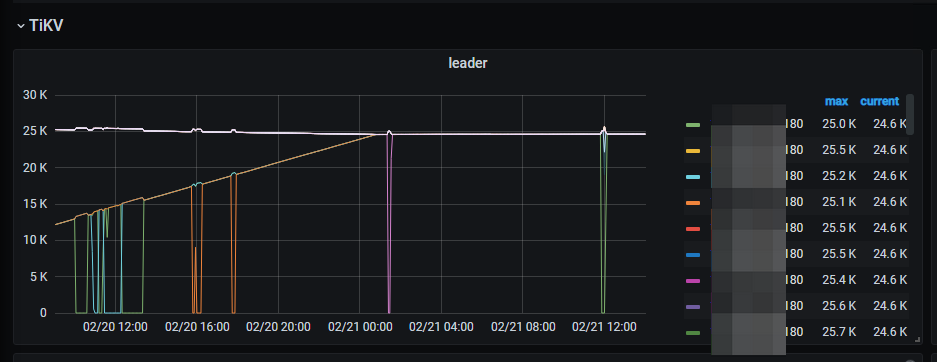
1,通过 监控 overview → tikv → leader 监控,发现某个节点的leader 会被全部切走
2,翻看监控,发现多个节点存在这种现象。多数为新扩入的tikv节点。偶然是原本的tikv节点
3,排查某个节点的,找到对应的store id
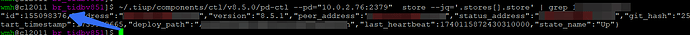
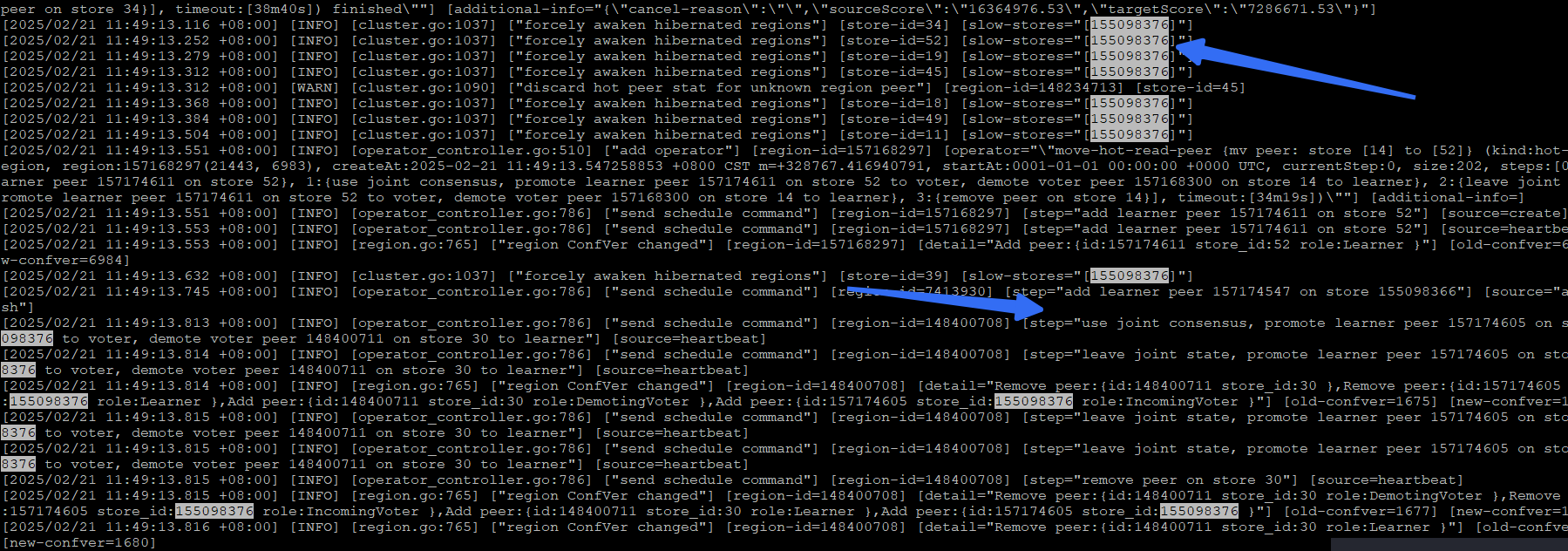
4,查看对应的pd.log 发现对应节点被其他多个节点awaken 为 慢节点。
日志关键字为 forcely awaken hibernated regions
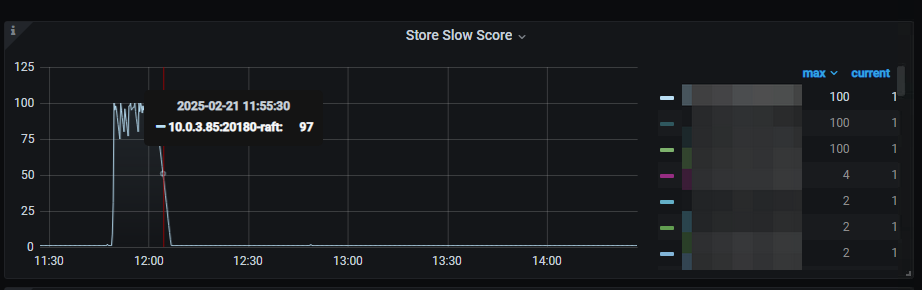
5, tikv-details → Slow Trend Statistics 监控,发现慢节点评分,对应时刻有三个节点的被检测为慢节点,其中就包括 上面我们所排查的那个节点。
机器都是同一个机房的机器,在同一个局域网内,想知道可以调整哪些参数,可以减少这种被检测为慢节点的概率
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
1 个赞
Denis
2
从pd的监控里应该也能看到对应时刻的slow stores。
检测的阈值应该没法调整,如果不想要 evict slow store 的话,可以删除掉对应的调度器
PD 调度策略最佳实践 | TiDB 文档中心
舞动梦灵
(Ti D Ber Nckmz Hmh)
4
我也发现一个,我的群集中有20多个tikv,突然发现有一个leader是个位数,region数量空间占的和其他tikv一样。我是4.0版本的,准备直接收缩掉这个服务器
不输土豆
(Ti D Ber Lkg Kt Rt P)
5
在v8.5.1 中,show config where type='tikv’中,好像没有这个参数了 

不输土豆
(Ti D Ber Lkg Kt Rt P)
7
在测试环境,edit-config 了一下,然后reload , 报错了
不输土豆
(Ti D Ber Lkg Kt Rt P)
8
写错了,是raftstore.inspect-interval。可以正常reload
有猫万事足
9
这个帖子你可以翻一下,处理方法和楼上的大同小异。
不过从机制上讲,当一个节点被判断为slow ,readpool应该是有排队现象的。对整体的QPS应该是一种保护。
Kongdom
(Kongdom)
10
 是不是可以把慢的tikv缩容?感觉这样抖动挺影响性能的。
是不是可以把慢的tikv缩容?感觉这样抖动挺影响性能的。
system
(system)
关闭
11
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。