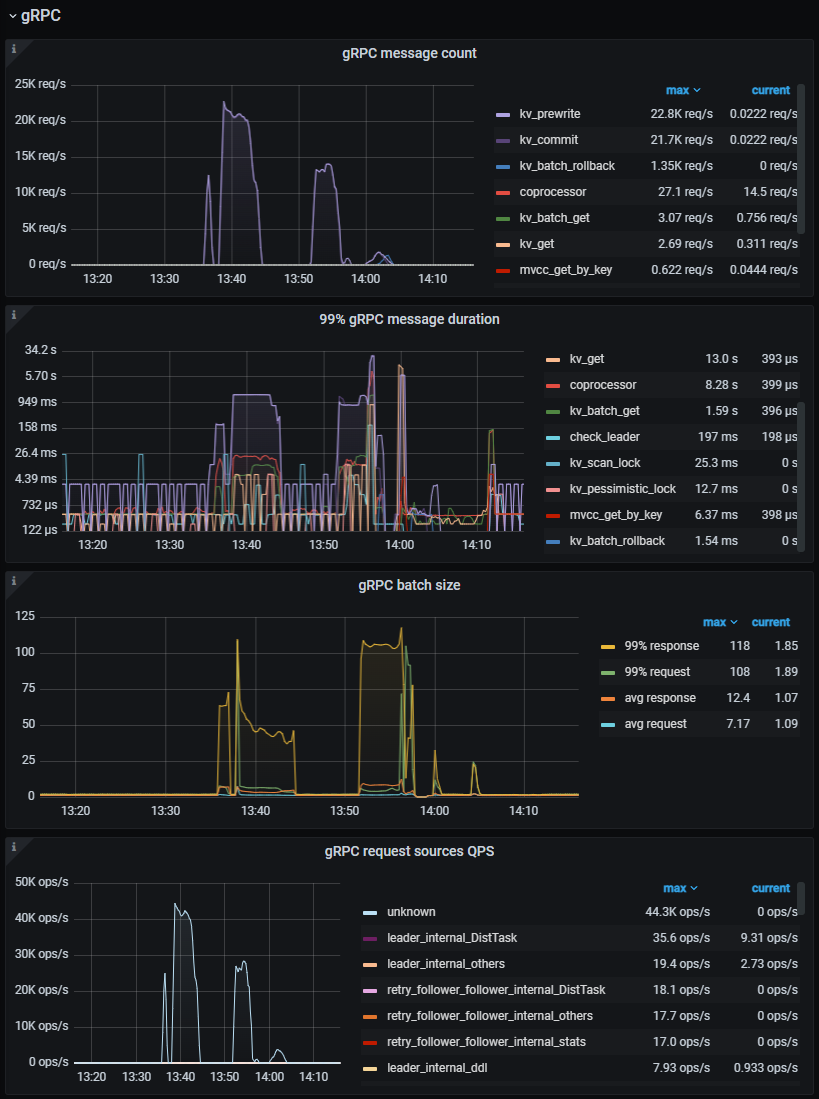
求解释一波为什么grpc message count的量和qps的量有什么关系,区别还是蛮大的,我是事务写的操作进行测试
如下是我grafana中tikv-details中的grpc报告:
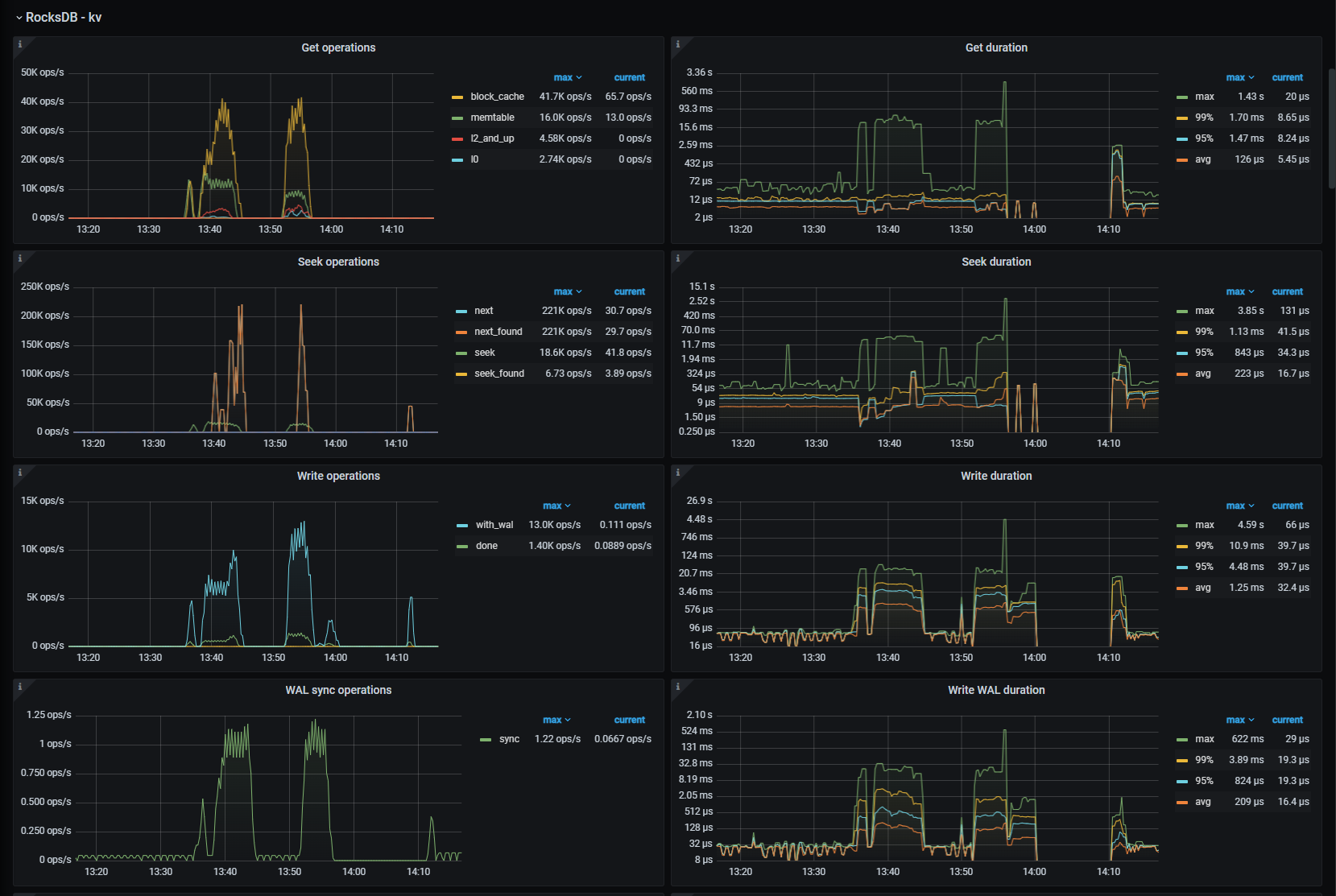
如下是我rockesdb的报告:
求解释一波为什么grpc message count的量和qps的量有什么关系,区别还是蛮大的,我是事务写的操作进行测试
如下是我grafana中tikv-details中的grpc报告:
如下是我rockesdb的报告:
附带一个问题,我压测时数据写入到数据盘中,为什么系统盘的读占用会这么高,有大佬解释一下嘛?
看这个,因为写数据把L0层写满了,触发compaction的情况下,需要对下一层数据进行全局排序。而全局排序需要读取。
insert写操作自动提交的情况下应该大致是2:1=grpc message count:insert qps。具体还要看事务怎么分的,会有一些出入。反正一次自动提交的insert,会有一次rewrite一次commit。
我看你图上的数量差不多就是这样。
那是不是说我压测的时候tikv最大接收的qps是看grpc message count中的 kv_commit值是吧,这个才是真是事务写入最大的请求数
这个qps和你事务是怎么分的关系更密切一些。
比如insert 自动提交的情况下,其实就是一个insert 一个事务。有10条insert就是10个事务。10个prewrite,10个commit。
如果10条insert 在一个begin 。commit里面。那就是一个事务。一个prewrite一个commit。
我看了你以前的帖子,好像是rawkv使用。
这个QPS和tidb的QPS还有点不一样,不太适合评估tikv的负载。
我感觉你还是想推测这个tikv到底能承载多少qps。
但在就是QPS和事务大小有一定的关系的情况下,直接用来评估单tikv QPS上线,在事务规模变化的情况下未必靠谱,多结合实际使用中的事务大小来推测上限会比较贴切。
如果你现在测试的事务大小就是你实际rawkv使用的事务大小,我觉得这个压测的qps上限就是有意义的。可以当作一个tikv负载的上限用于评估。
我一个请求一个事务,一个事务就一个key的处理
那我觉得非常贴合实际。这个压测的qps评估是没什么问题的。
那是看那个模块的值呢?是kv_commit的还是grpc request sources QPS的?
我感觉这个好点。
另外这个unknown的分类标签是可以自己设置的。
看上面这个帖子。
还一个问题,就是我原先系统盘飙高使用的问题,因为看文档,内存默认占比是75%,是只有达到了75%才会进行内部缓存会被清除以释放内存嘛?我刚压测的时候出现tikv打崩的情况,我看的是如下文档的解释:
https://docs.pingcap.com/zh/tidb/stable/tikv-configuration-file#memory-usage-limit memory-usage-limit,因为rocksdb是有热冷数据区分的,这部分可有更详细的解释,不然我线上环境一味的提高内存也不是办法
控制tikv内存memory-usage-limit是不好用的。
https://docs.pingcap.com/zh/tidb/stable/tikv-configuration-file#capacity
控制blockcache的容量会比较容易控制。
我目前测试环境是并没有设置 memory-usage-limit值得,没设置是自带默认值使用75%得内存嘛?
memory-usage-limit这个你怎么设置,对oom都不会有改善。放着就行了。
亲测有效控制内存的手段就是调整block-cache。oom就往下调,可能需要多试试,但是肯定能控制住的。
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。