【 TiDB 使用环境】生产环境
【 TiDB 版本】8.1.1
【复现路径】突发性(暂时还清楚什么原因会复现)
【遇到的问题:问题现象及影响】
在早上8:00左右服务宕机,tidb一台服务(243)不可用
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
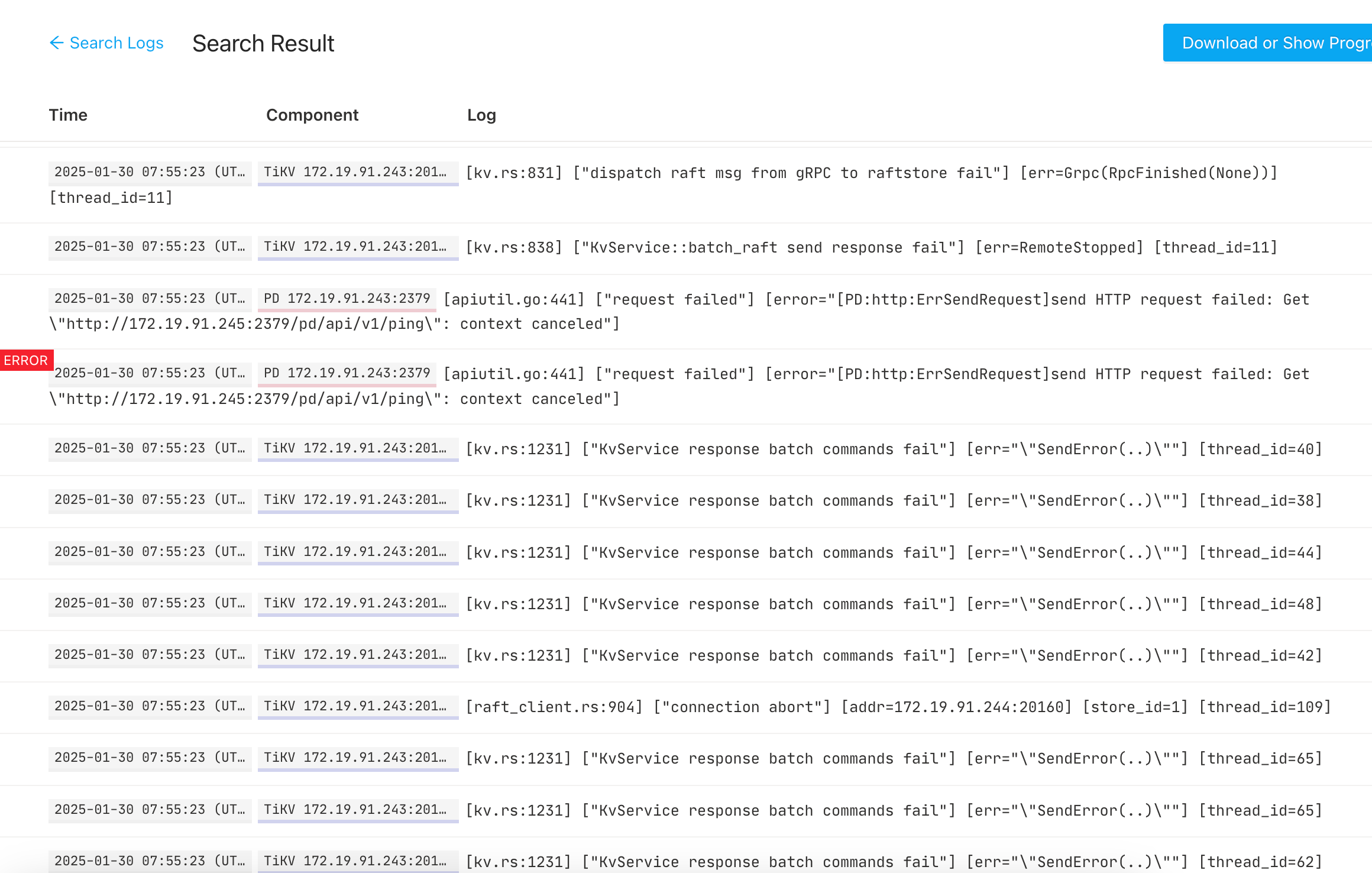
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
【 TiDB 使用环境】生产环境
【 TiDB 版本】8.1.1
【复现路径】突发性(暂时还清楚什么原因会复现)
【遇到的问题:问题现象及影响】
在早上8:00左右服务宕机,tidb一台服务(243)不可用
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
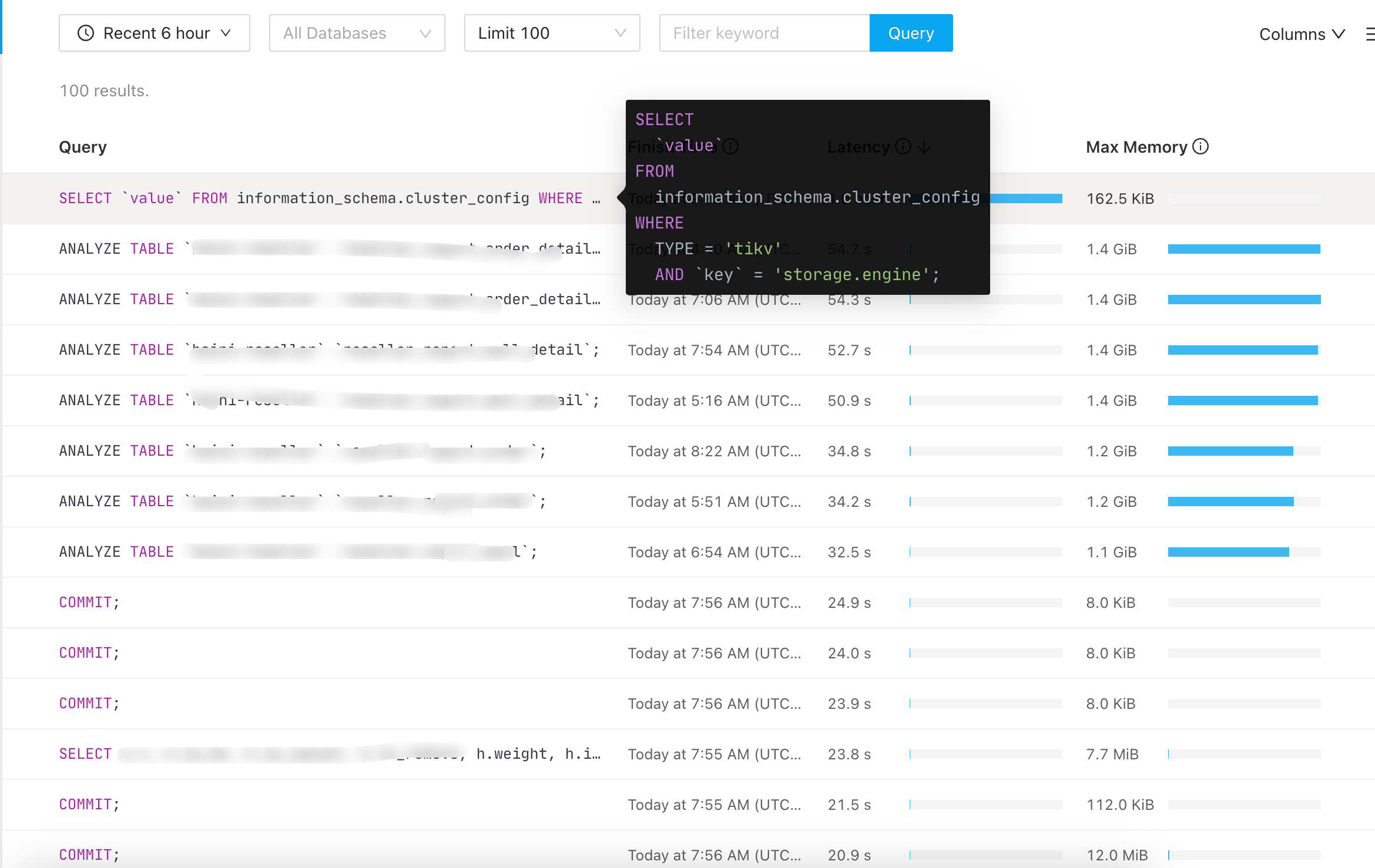
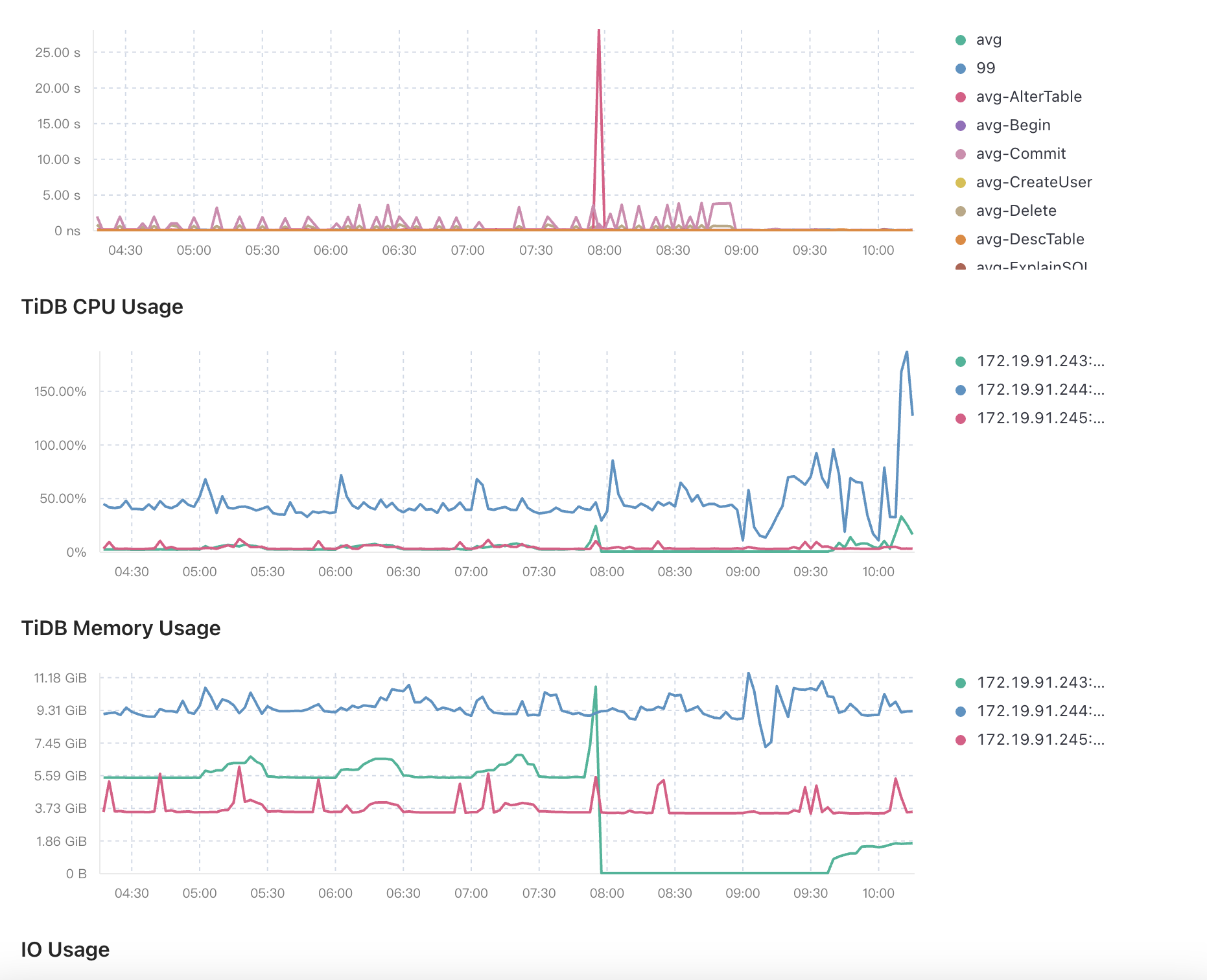
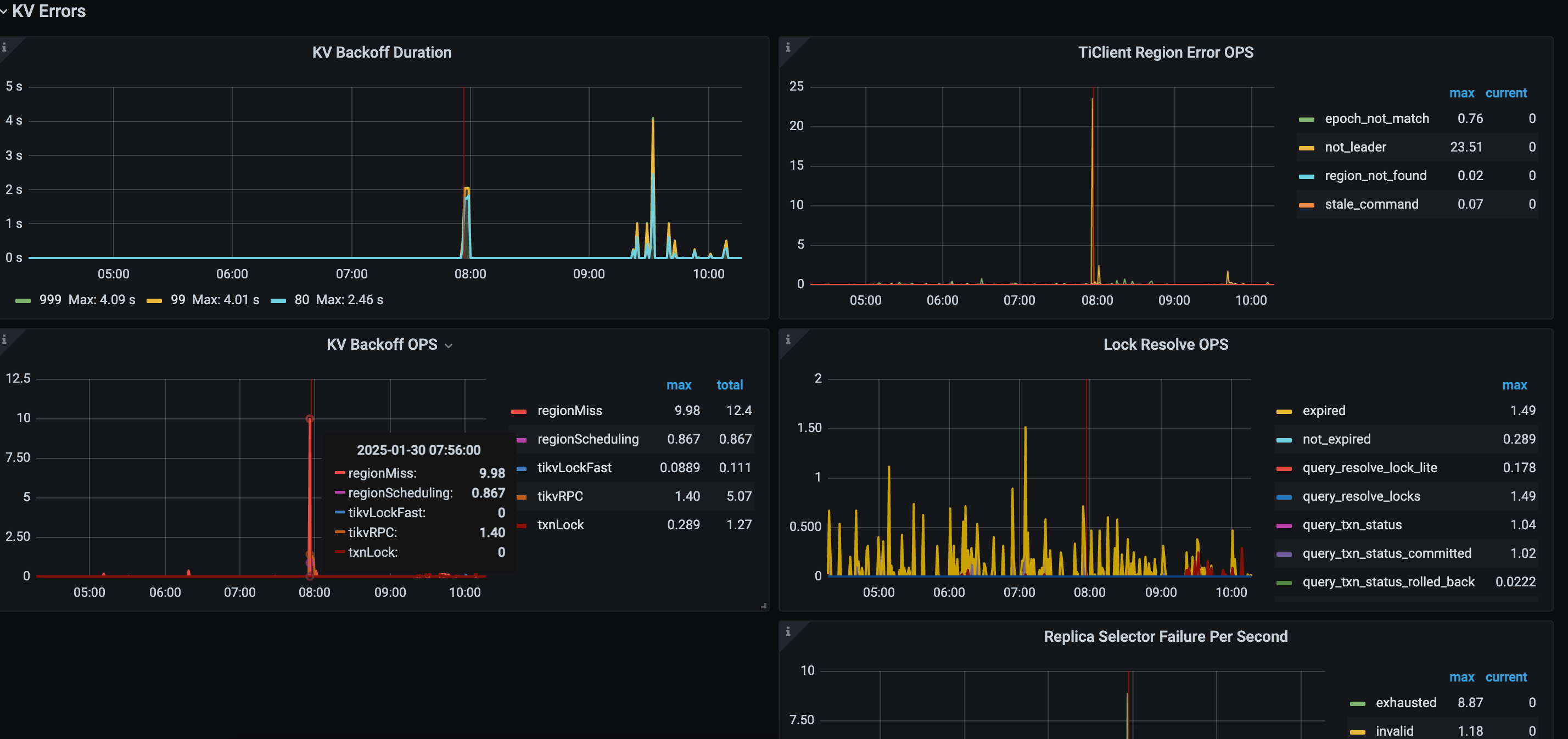
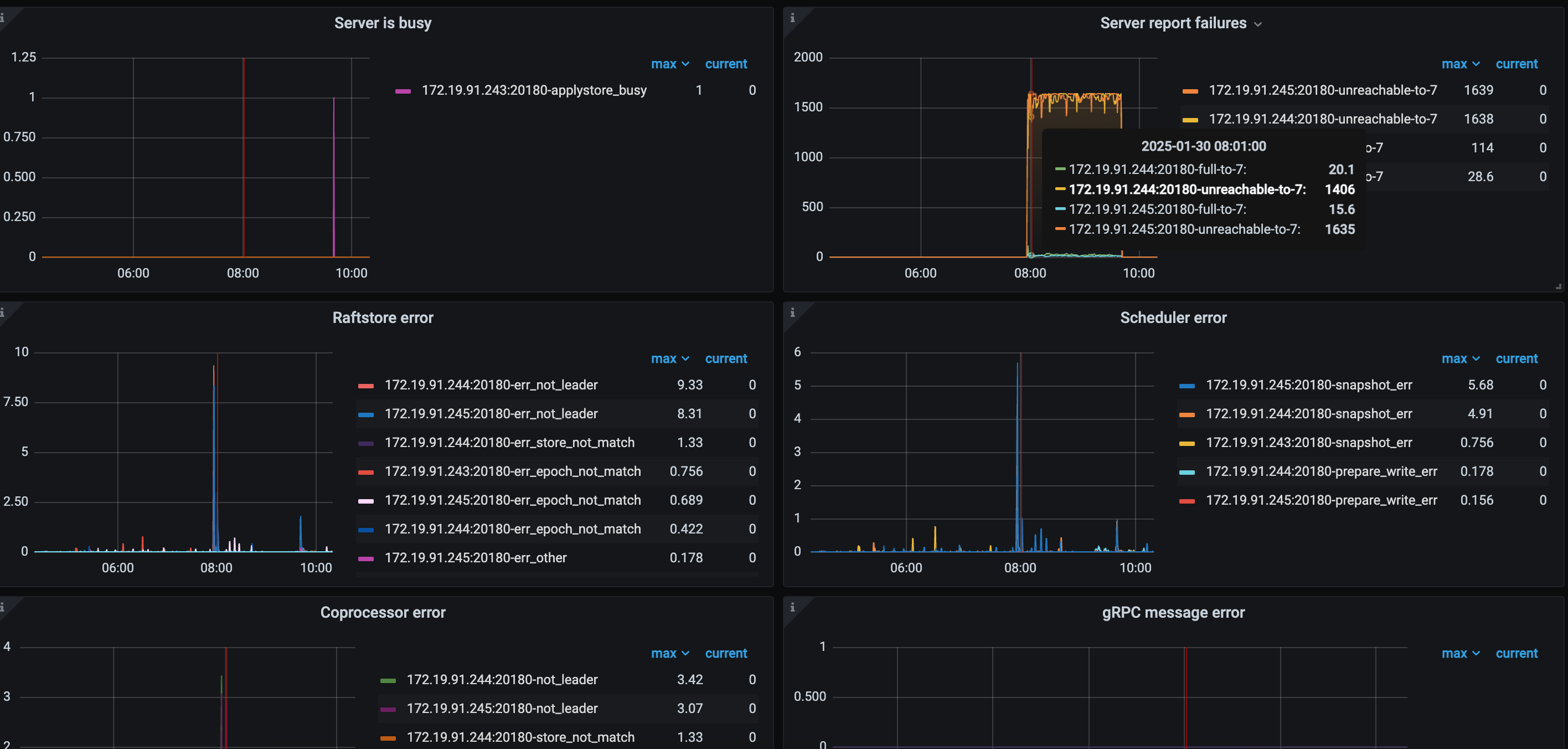
看图 243 节点有内存升高,然后其他节点报不可达,慢查询又显示有很多 analyze 任务占用很多内存,所以有可能是 analyze 的问题
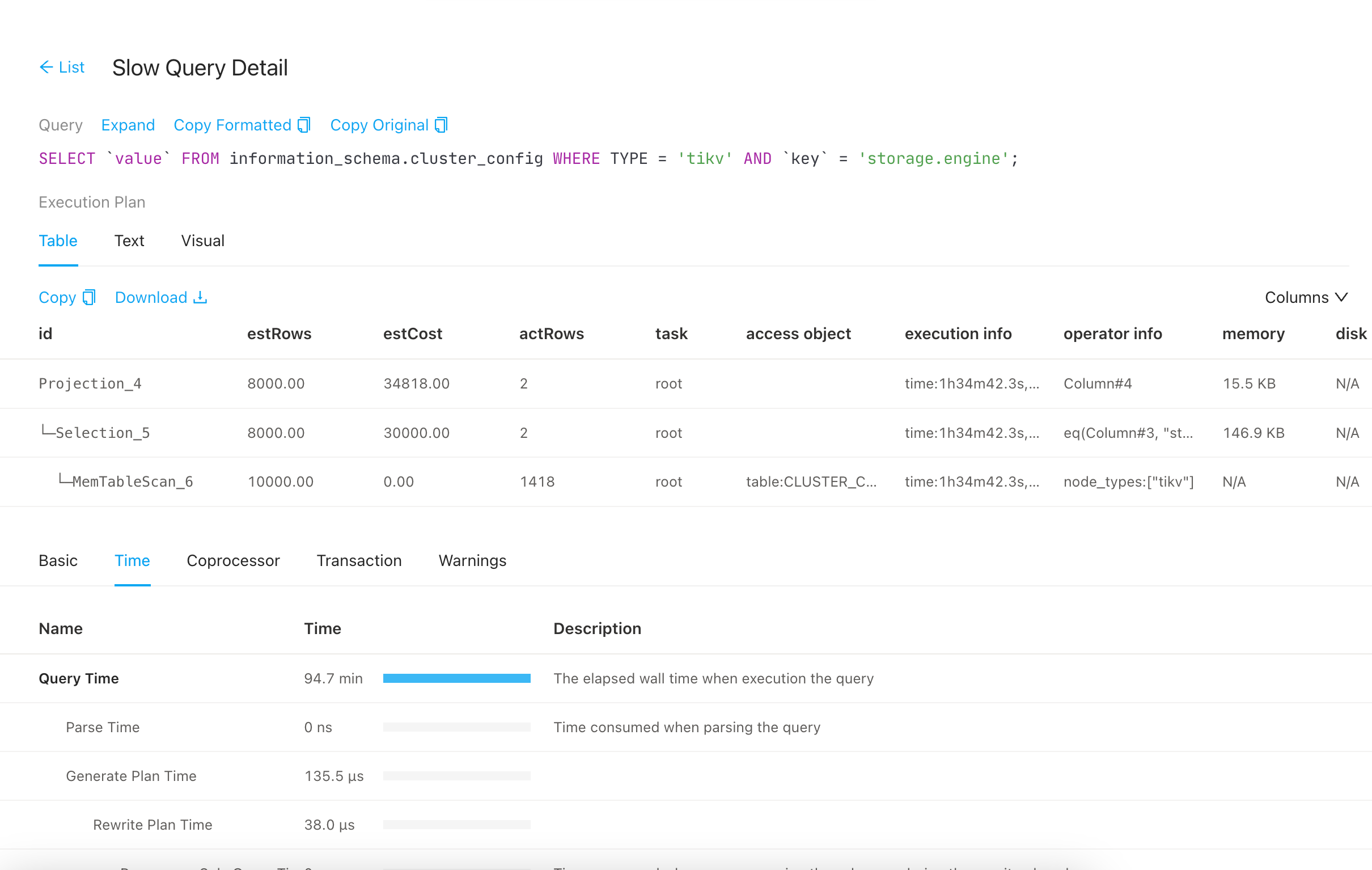
8点的时候应该是执行了一个alert table导致这个243 oom了,不过没想通的是为啥1个半小时才起来?
像是243上还有个tikv,tidb已经oom的情况下,还在疯狂扫描alter table的数据,导致tidb一直等到扫描完成才起来,这样才能解释的通。
tikv的监控信息,集群拓扑也提供一下,感觉还是混合部署的问题。
看上去analyze占用了很多内存,是否就可以将analyze改为夜间执行,白天不执行?
这内容占比太高了,后台 多少任务呢 ?
优化一下。
从图中信息看的话,感觉在7点55到8点有altertable操作,导致io超高,把服务拉挂了,所以检查下这个时间的alter和analyze