通过阅读源码了解到tidb中unistore本地存储使用的是pingcap/badger开源key-value数据库,请问一下和 dgraph-io/badger是同一个吗?
我们想使用tidb的unistore作为生产环境引擎,请问一下有无使用案例,是否可靠。
多谢
通过阅读源码了解到tidb中unistore本地存储使用的是pingcap/badger开源key-value数据库,请问一下和 dgraph-io/badger是同一个吗?
我们想使用tidb的unistore作为生产环境引擎,请问一下有无使用案例,是否可靠。
多谢
说的是这个么?这个好像是存储引擎。
https://docs.pingcap.com/zh/tidb/stable/tidb-faq#119-tidb-是否支持其他存储引擎
是的,tidb支持除了tikv以外的unistore和mocktikv引擎,就是想知道这个unistore是否稳定,是否已经有了线上使用经验
Following these rules:
- v1.5.0 and v1.6.0 can be used on top of the same files without any concerns, as their major version is the same, therefore the data format on disk is compatible.
- v1.6.0 and v2.0.0 are data incompatible as their major version implies, so files created with v1.6.0 will need to be converted into the new format before they can be used by v2.0.0.
- v2.x.x and v3.x.x are data incompatible as their major version implies, so files created with v2.x.x will need to be converted into the new format before they can be used by v3.0.0.
这个dgraph-io下的badger的新版本号tag已经到4.5了,pingcap下的badger看tag只有1.5。估计就是那个时候fork过来的。
这个引擎动不动就和以前的存储格式不兼容,升级的时候需要转换才能继续用。怕是难有人敢用啊。
而且unistore感觉就类似存算一体了。初期可能少用一些机器,长期看,存算不能独立伸缩是挺难受的。
如果不考虑badger版本升级的情况的话,是不是可以不用考虑存储格式不兼容的情况。
我们项目要求使用tidb并且资源不需要伸缩,就想知道unistore是否稳定
没有商业化的案例,现在只是在测试里面用到。需要单机使用 tidb 的话,为什么不用别的专门的单机数据库呢?
唉,一言难尽,领导的需求
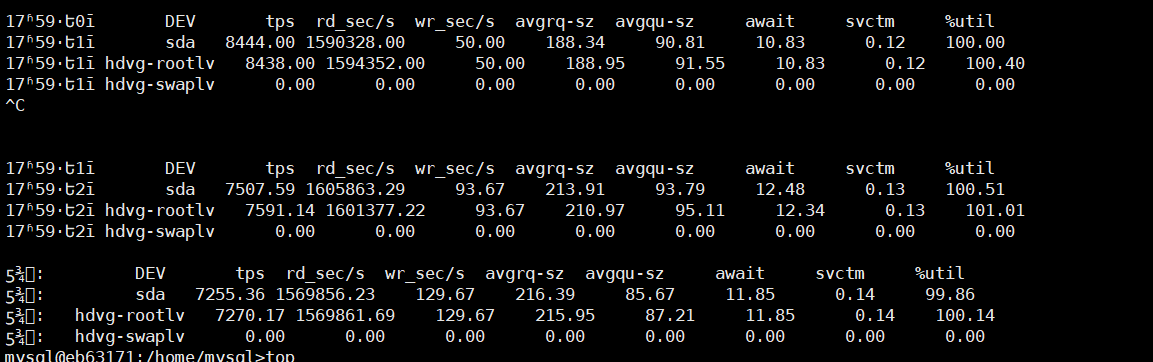
而且在使用sysbench对于unistore的存储的tidb进行性能测试的时候发现一个奇怪现象,如果sysbench只是对于单表压测,性能很好。如果对于多表压测(10张)时会出现大量io操作,导致主机iowait很高,性能上不去是什么情况呢?
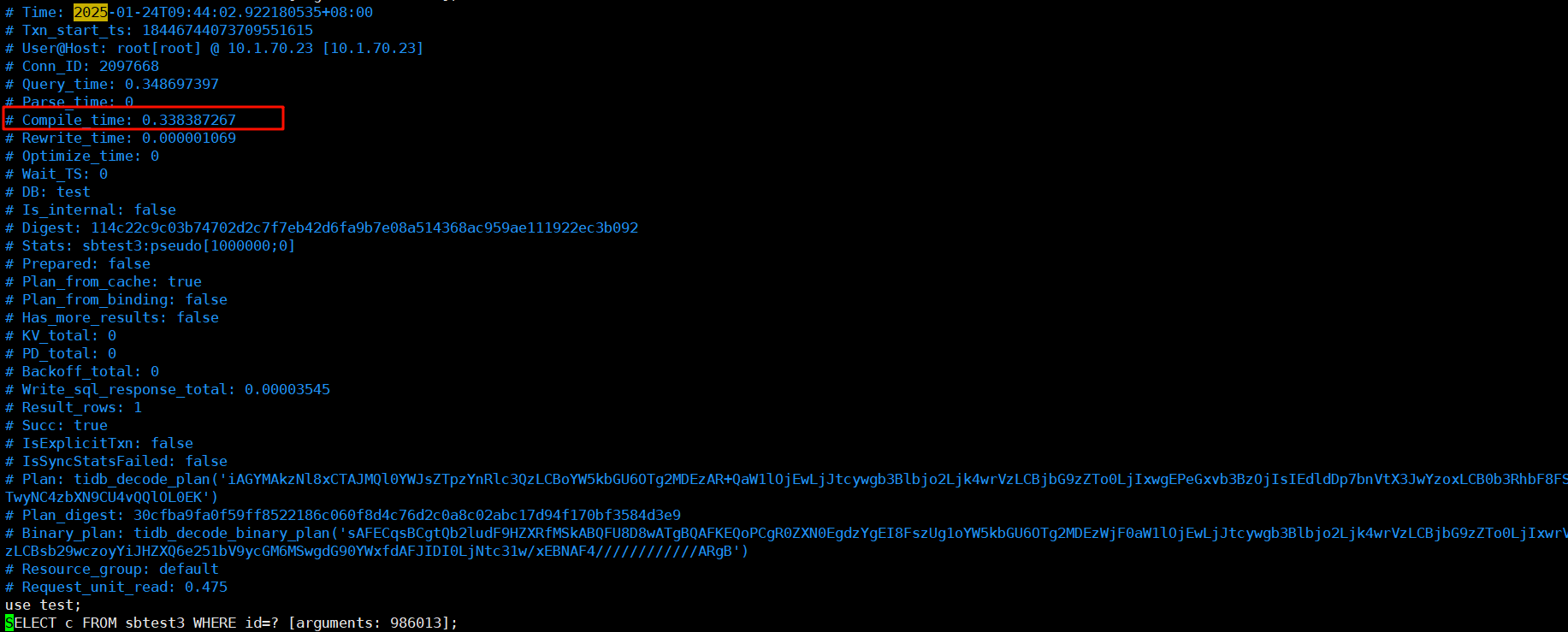
编译都慢,一般都是cpu已经打满了。
能做的优化也就是使用执行计划缓存,看能否跳过编译阶段。
https://docs.pingcap.com/zh/tidb/stable/sql-prepared-plan-cache#prepare-语句执行计划缓存
https://docs.pingcap.com/zh/tidb/stable/sql-non-prepared-plan-cache#非-prepare-语句执行计划缓存
磁盘是什么类型的? 是不是 IO 就很低,没办法支持这么大的写入和读取的需求
新年好呀。qps固定的情况下,只是增加表数量应该不会涉及到突然增大的磁盘io吧
IO是固定的,处理的量级不是固定的,这个就是矛盾点了
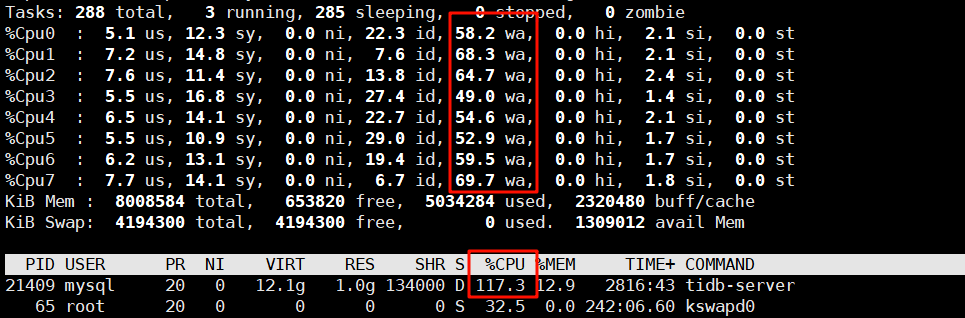
cpu并没有满哦。就是系统的wa会突然变得很高
该存储引擎大部分情况是为了 tidb 本地 debug 使用,缺乏商业支持和版本迭代。建议谨慎使用。
另外单机引擎其实是有很多成熟的优化技术的,这些 unistore 大概率是没有深度优化的,所以相比于 mysql pg 等成熟的单机引擎性能会差很多。
猜测可能是没有 blockcache 或者异步 IO 的问题
wa会变高,感觉你大概率是混合部署,是tikv和tidb部署在一起了嘛?
如果是tikv挤占了cpu时间,效果也和tidb的cpu打满了是差不多的。
明白,多谢
只是增加测试的表数量,其它都不动的情况,突然就出现了