【 TiDB 使用环境】生产环境
【 TiDB 版本】
【复现路径】列表压测(单表查询),数据300w左右
【遇到的问题:问题现象及影响】 导致其他查询时间从1s → 50s左右
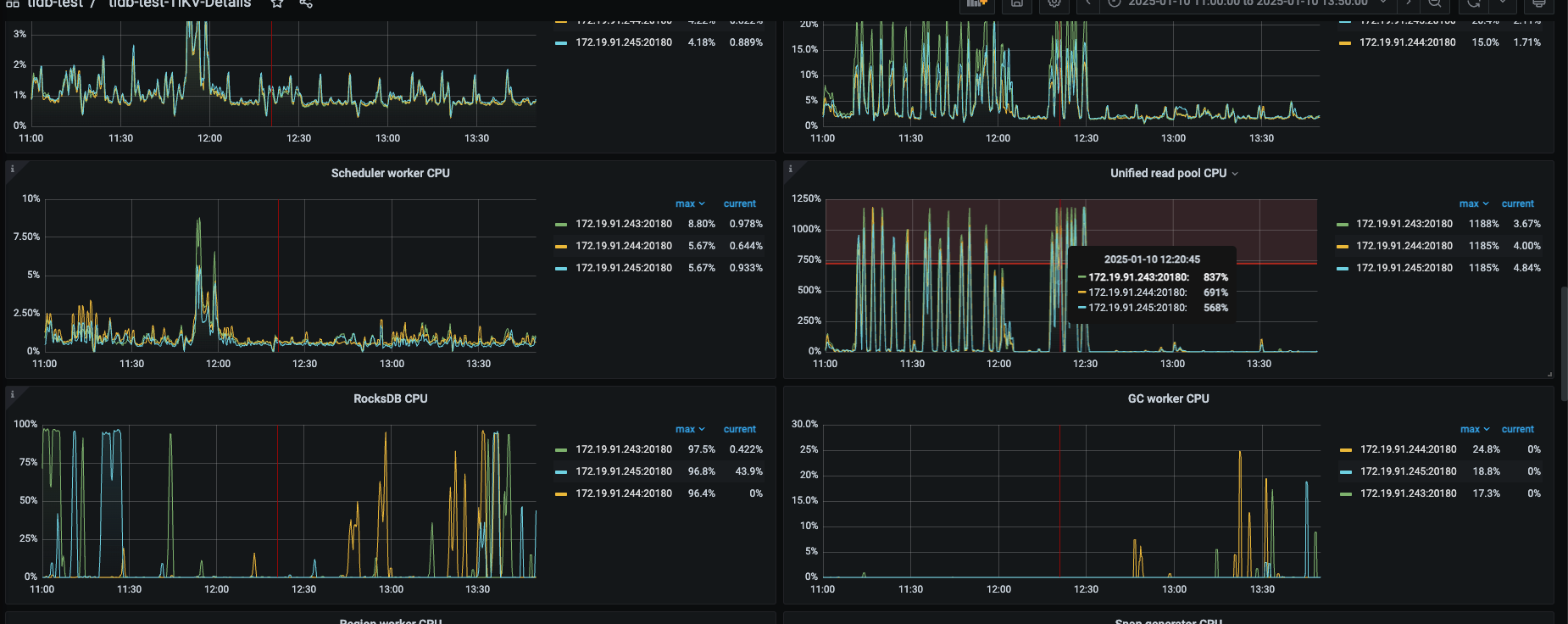
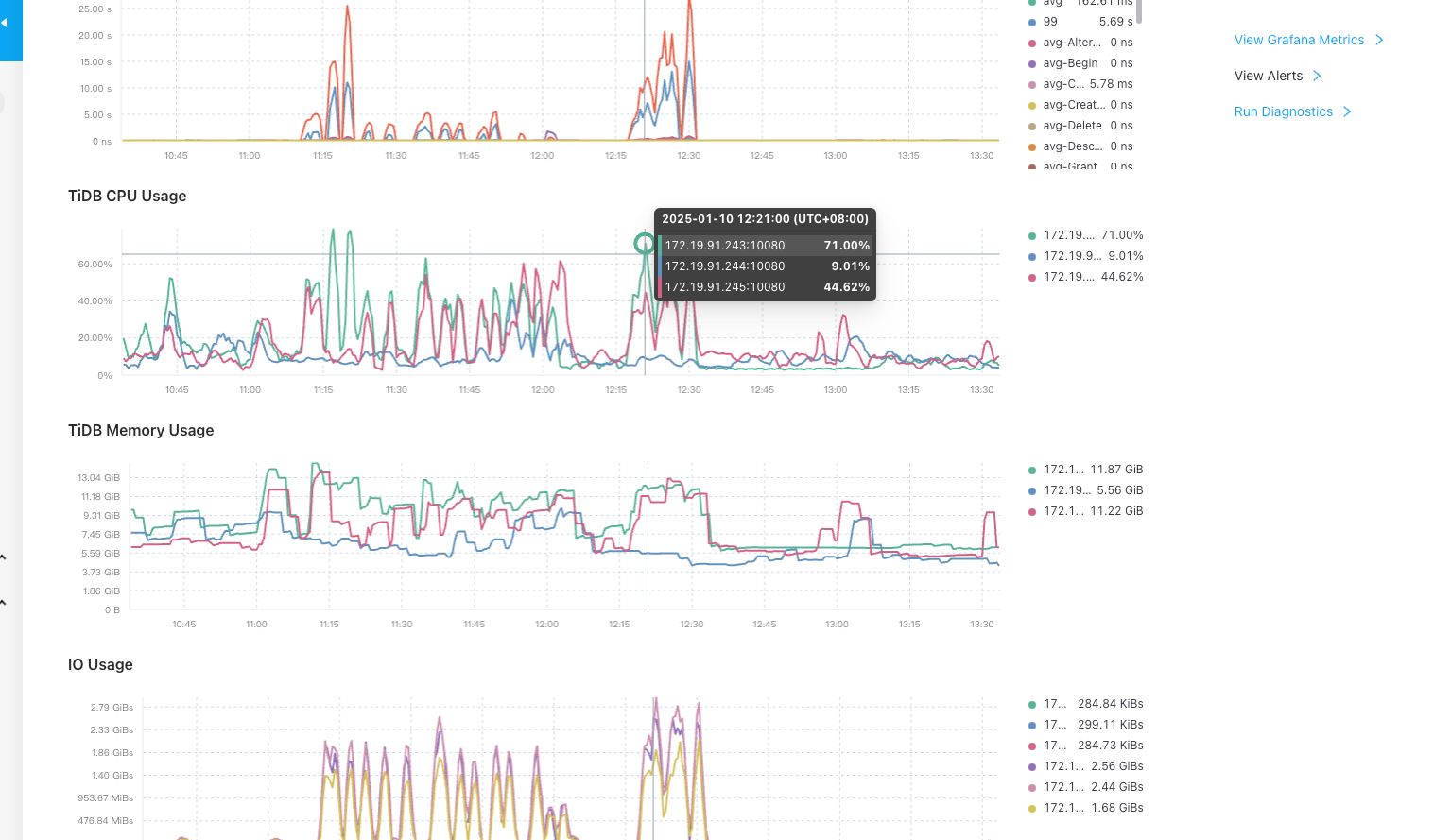
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
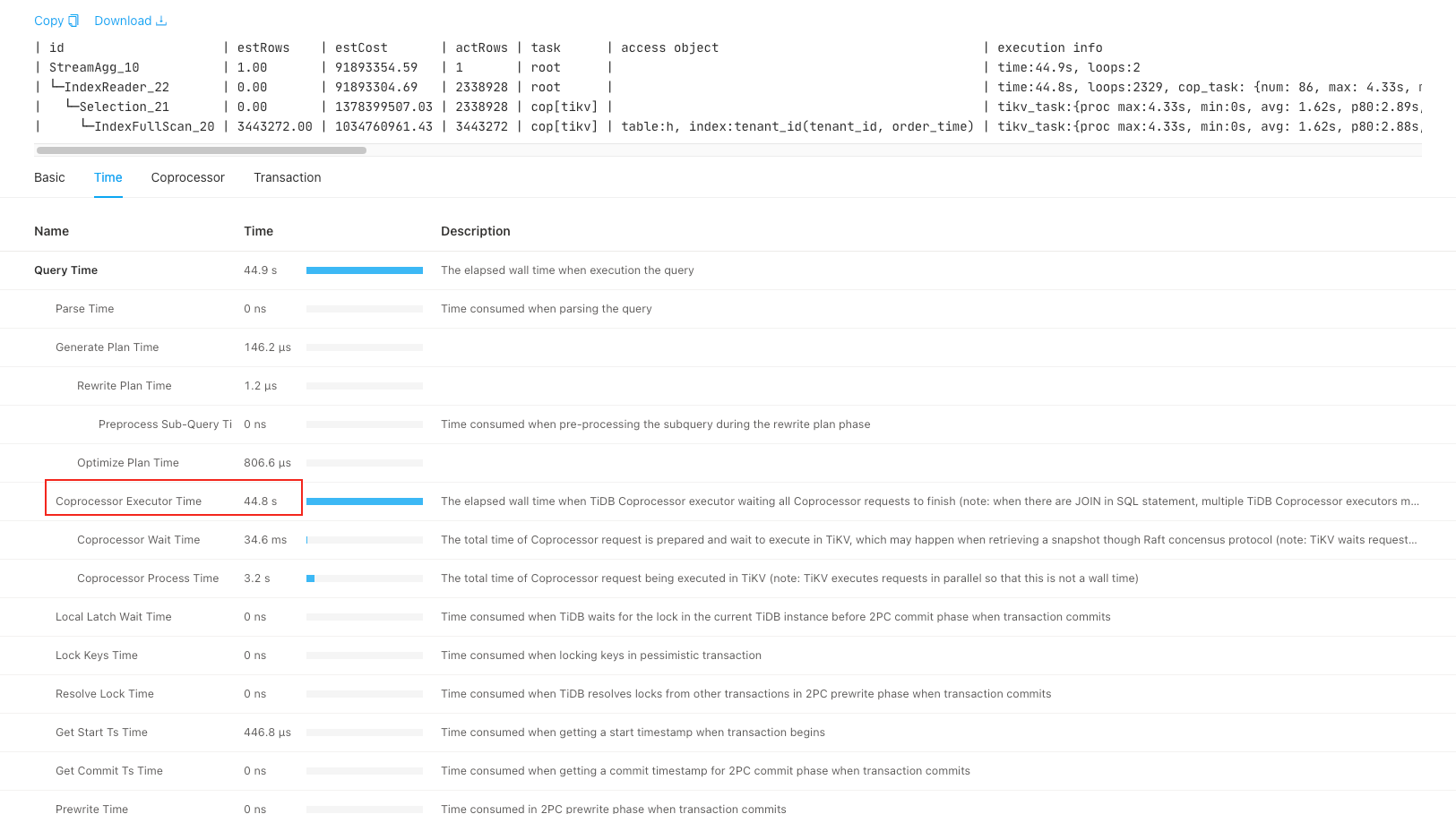
| id | estRows | estCost | actRows | task | access object | execution info | operator info | memory | disk |
| StreamAgg_10 | 1.00 | 91893354.59 | 1 | root | | time:44.9s, loops:2 | funcs:count(0)->Column#97 | 11 KB | N/A |
| └─IndexReader_22 | 0.00 | 91893304.69 | 2338928 | root | | time:44.8s, loops:2329, cop_task: {num: 86, max: 4.33s, min: 707.4µs, avg: 1.62s, p95: 4.11s, max_proc_keys: 405311, p95_proc_keys: 108512, tot_proc: 3.18s, tot_wait: 34.6ms, copr_cache_hit_ratio: 0.00, build_task_duration: 25.6µs, max_distsql_concurrency: 5}, rpc_info:{Cop:{num_rpc:86, total_time:2m19.4s}} | index:Selection_21 | 794.3 KB | N/A |
| └─Selection_21 | 0.00 | 1378399507.03 | 2338928 | cop[tikv] | | tikv_task:{proc max:4.33s, min:0s, avg: 1.62s, p80:2.89s, p95:4.1s, iters:3704, tasks:86}, scan_detail: {total_process_keys: 3443272, total_process_keys_size: 406306096, total_keys: 3443358, get_snapshot_time: 1.32ms, rocksdb: {key_skipped_count: 3443272, block: {cache_hit_count: 10560}}}, time_detail: {total_process_time: 3.18s, total_suspend_time: 2m16s, total_wait_time: 34.6ms, total_kv_read_wall_time: 2m18.9s, tikv_wall_time: 2m19.3s} | ge(haini-reseller.reseller_hjs_order_archive.order_time, 2024-05-01 00:00:00.000000), lt(haini-reseller.reseller_hjs_order_archive.order_time, 2024-09-08 23:59:59.000000) | N/A | N/A |
| └─IndexFullScan_20 | 3443272.00 | 1034760961.43 | 3443272 | cop[tikv] | table:h, index:tenant_id(tenant_id, order_time) | tikv_task:{proc max:4.33s, min:0s, avg: 1.62s, p80:2.88s, p95:4.1s, iters:3704, tasks:86} | keep order:false | N/A | N/A |