【 TiDB 版本】 V7.5.4
【遇到的问题:问题现象及影响】
32C、128G 的机器上部署了三个 tikv节点,每个节点单独挂载了一个磁盘,经过观察,可用内存长时间在 3G 左右。此时我是否应该增加资源或者调整参数?tikv配置如下图。
【附件:截图/日志/监控】
可用内存:

tikv占用内存:

tikv参数配置:
【 TiDB 版本】 V7.5.4
【遇到的问题:问题现象及影响】
32C、128G 的机器上部署了三个 tikv节点,每个节点单独挂载了一个磁盘,经过观察,可用内存长时间在 3G 左右。此时我是否应该增加资源或者调整参数?tikv配置如下图。
【附件:截图/日志/监控】
可用内存:
tikv占用内存:
tikv参数配置:
我理解的是,业务正常,系统平稳的情况下,最好不要随便调整参数。
虽然我确实是按照文档中说的配置的,但是3个G 可用我的心里好慌啊。
你没配置tikv的混合部署内存限制吗,很容易oom的
第三张图就是的嘛
看起来你这个大概率是数据量太大了。这是 tikv 内存使用的大头:你可以看看
Region 内存
rocksdb
block cache :默认值为 TiKV 默认将系统总内存大小的 45% storage.block-cache.capacity
memtable ( tikv details / rocksdb kv / memtable size)
raftstore
memory fragmentation (tikv details / memory / allocator stats → fragmentation and dirty and meta )
resolved-ts
ticdc
TiKV 无负载下启动常驻 =~ 1.3G
Task
Unified Read Pool
TiKV 本来就比较吃资源,按照三个节点混合部署,业务稳定,你这使用量挺正常的,怕内存不够增加内存资源
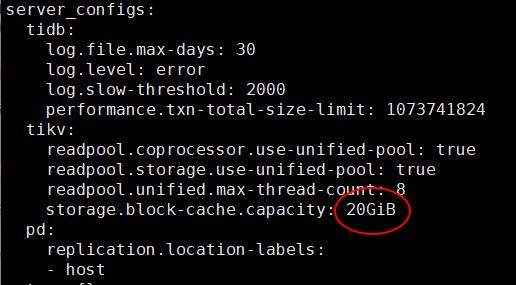
我另外还有一个集群,也是 3 个 KV 节点,但是在三台不同的机器上,每台机器 48G内存。配置上 storage.block-cache.capacity: 30GiB,这个集群中每个节点都有一个 9G的内存剩余,非常稳定。所以这个 128G 内存的机器, storage.block-cache.capacity 为 20G 的时候,感觉怎么应该也有 10几G 的剩余内存。
我调哪里能让他少占用些内存,可以接受速度慢些。但是资源确实没有了。 ![]()
调小点,看起来20G太大了
好的,谢谢。
你可以top -H看下哪个线程占的内存多,之前我发现调整storage.block-cache.capacity是最快的,但是tikv组件比较多,所以肯定比这个参数设置的值再多20%+
这种情况主要是看看整个集群的duration怎么样。延迟大了就得找找瓶颈在哪里在对应扩容。Linux的内存一般都是预分配的。
数据量呢 上面 case集群的数据量是不是大很多了,还有就是 cdc 的使用情况。配置参数也完全一样吗,raftstore 的这些。
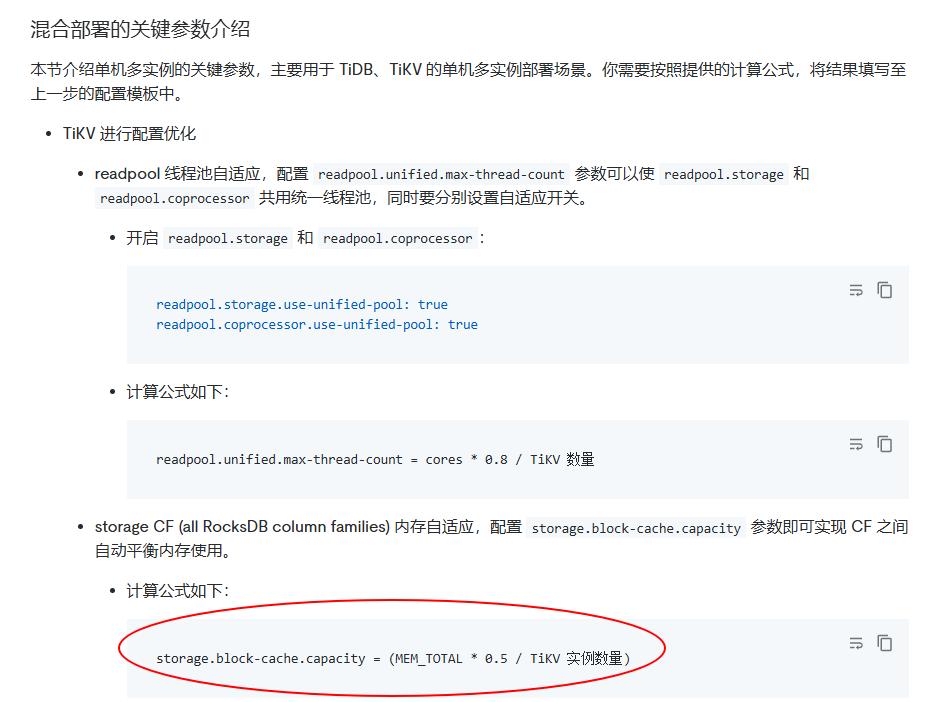
官方文档中 混合部署拓扑结构 说明计算公式为 storage.block-cache.capacity = (MEM_TOTAL * 0.5 / TiKV 实例数量) ,但是 tikv内存调优中说 shared block cache 的大小正常情况下应设置为系统全部内存的 30%-50%。所以 128G 的机器部署三个节点,理论上每个 kv 就是40G 内存,block-cache.capacity 设置为 20G 的话是 50%了,已经达到推荐的上限了,应该调小尝试。
最好是扩容个节点 ,要是不行限制下内存
memory-usage-limit :
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。