大钢镚13146
(Ti D Ber L Uxk Vpp3)
1
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】 7.5.1
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
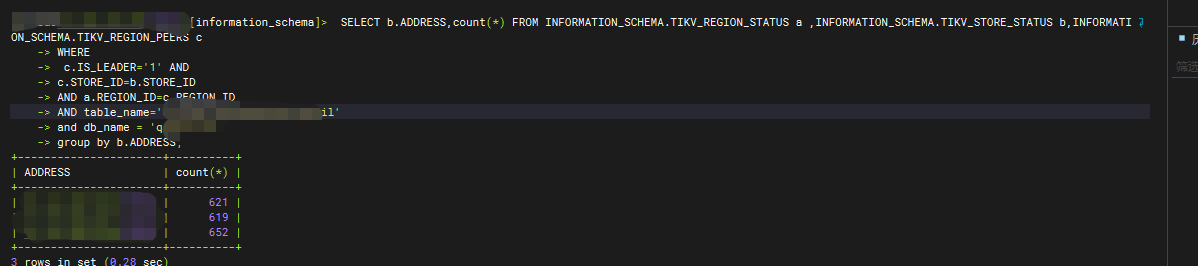
有一个tidb集群,应该是存在热点读的情况,三个tikv节点cpu依次的高
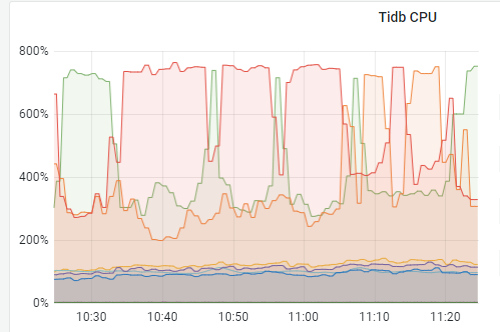
主要的批量查询语句 是对于热点表的主键排序后的 limit 10000的操作,都是连续的往后查询 一直查完所有的
怀疑是连续的 limit 10000的操作打到了相同的tikv节点,导致分批的的tikv cpu 高
看这个表的leader region 也是差不多的
后面应该怎么排查,请给与思路
有猫万事足
2
连续一小时一直对着一个表limit 10000?
如果连续扫到的都是这一段数据的话,那不就是说着这1小时内,这一段数据其实也没有大的变化。
最好是考虑把最新的10000w条放redis里面去
大钢镚13146
(Ti D Ber L Uxk Vpp3)
3
相当于对表的一大部分做扫描 只不过是按照主键进行排序 每次取 10000 处理 一直扫完
1 个赞
小龙虾爱大龙虾
(Minghao Ren)
4
cpu 高就看 dashboard 上的 top sql
有猫万事足
5
就是分页查,每次取10000行,这样?
那这部分查出去,后续是做了什么?如果是后续还需要聚合,可以考虑别查出去了,直接在tiflash上算。
读热点,现在除了副本读也没有太好的解决方法。
https://docs.pingcap.com/zh/tidb/stable/troubleshoot-hot-spot-issues#打散读热点
大钢镚13146
(Ti D Ber L Uxk Vpp3)
6
top sql就是我上面发的那个 对主键批量的 进行 limit 10000 循环取
大钢镚13146
(Ti D Ber L Uxk Vpp3)
7
走联合索引 order by 主键 limit 10000 走tiflash 应该不好用吧
有猫万事足
8
不好用,但是后续如果查出去还需要再聚合一次的话,这个聚合可以用tiflash,没聚合就算了。不要这么折腾了。
大钢镚13146
(Ti D Ber L Uxk Vpp3)
9
感觉可以切割下region 或者给整个表的region再重新打散一下
有猫万事足
10
Kongdom
(Kongdom)
11