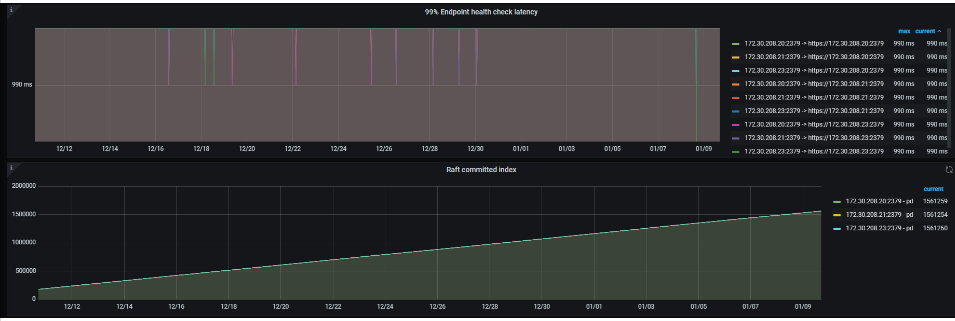
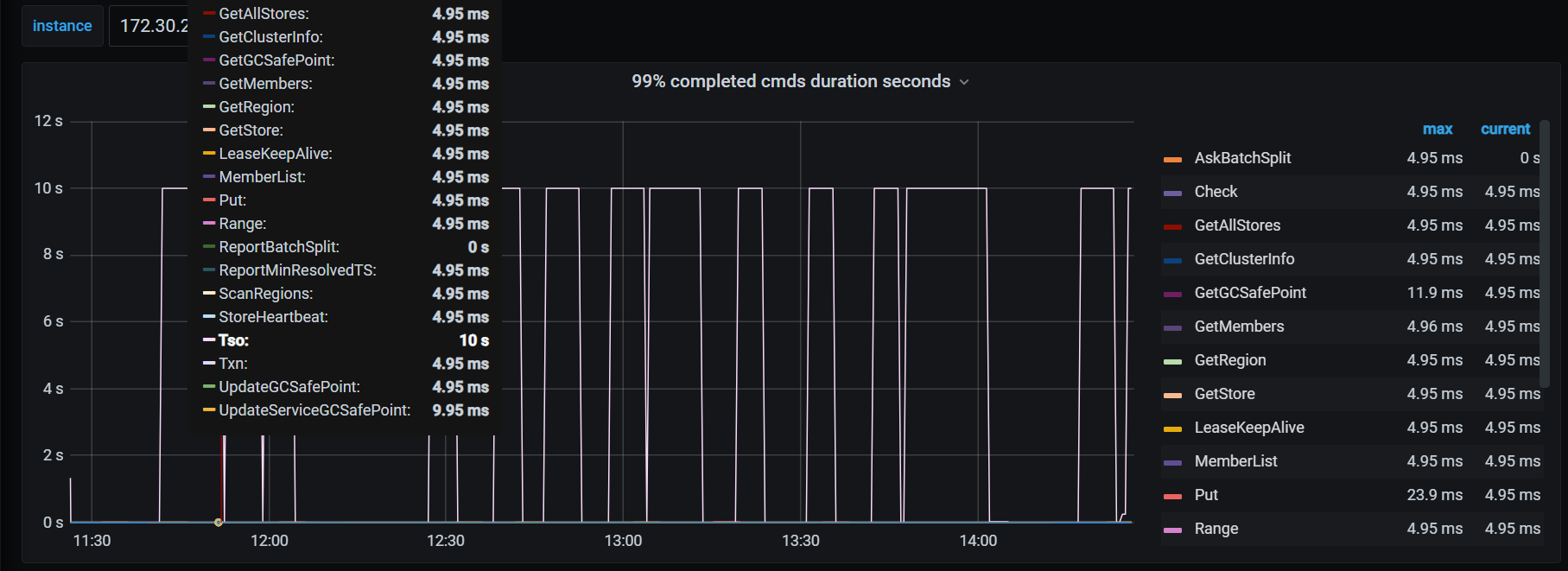
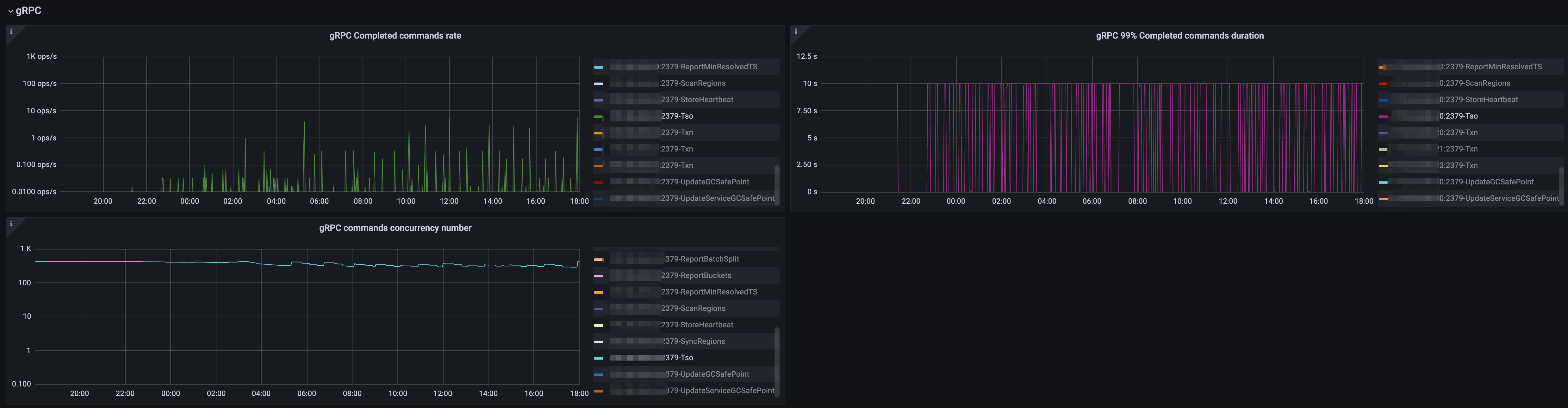
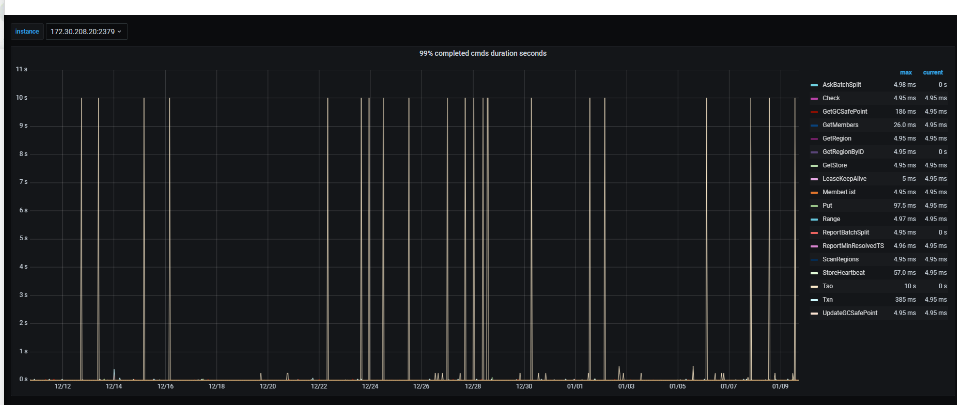
TSO 达到10s
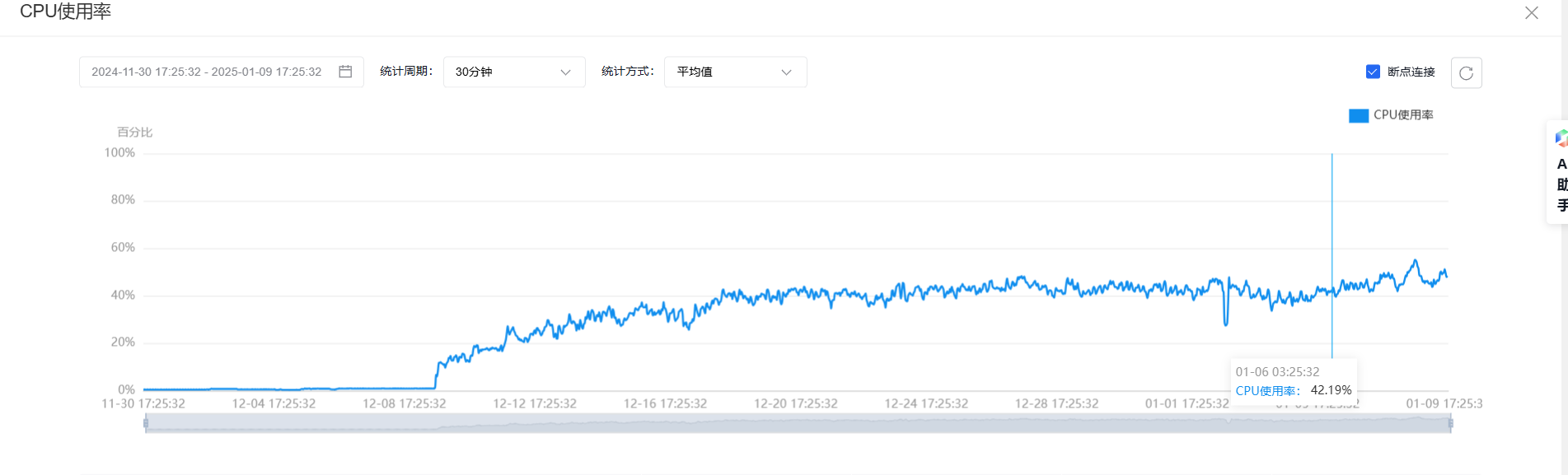
pd-leader cpu 长期处于60%左右
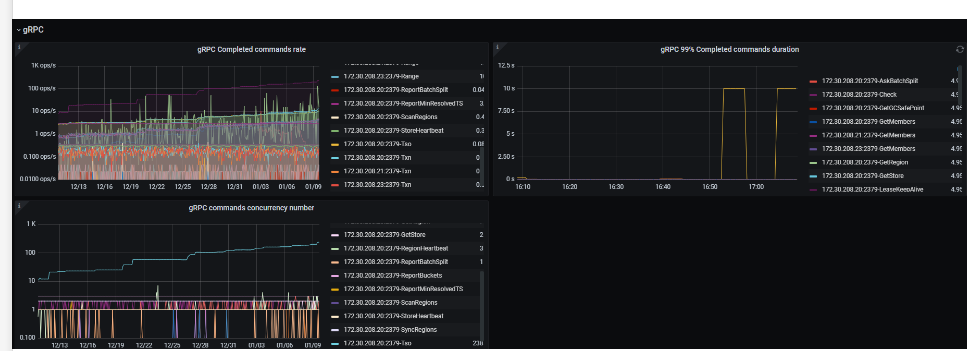
grpc
etcd
集群什么规模,抓一下pd的火焰图看一下吧
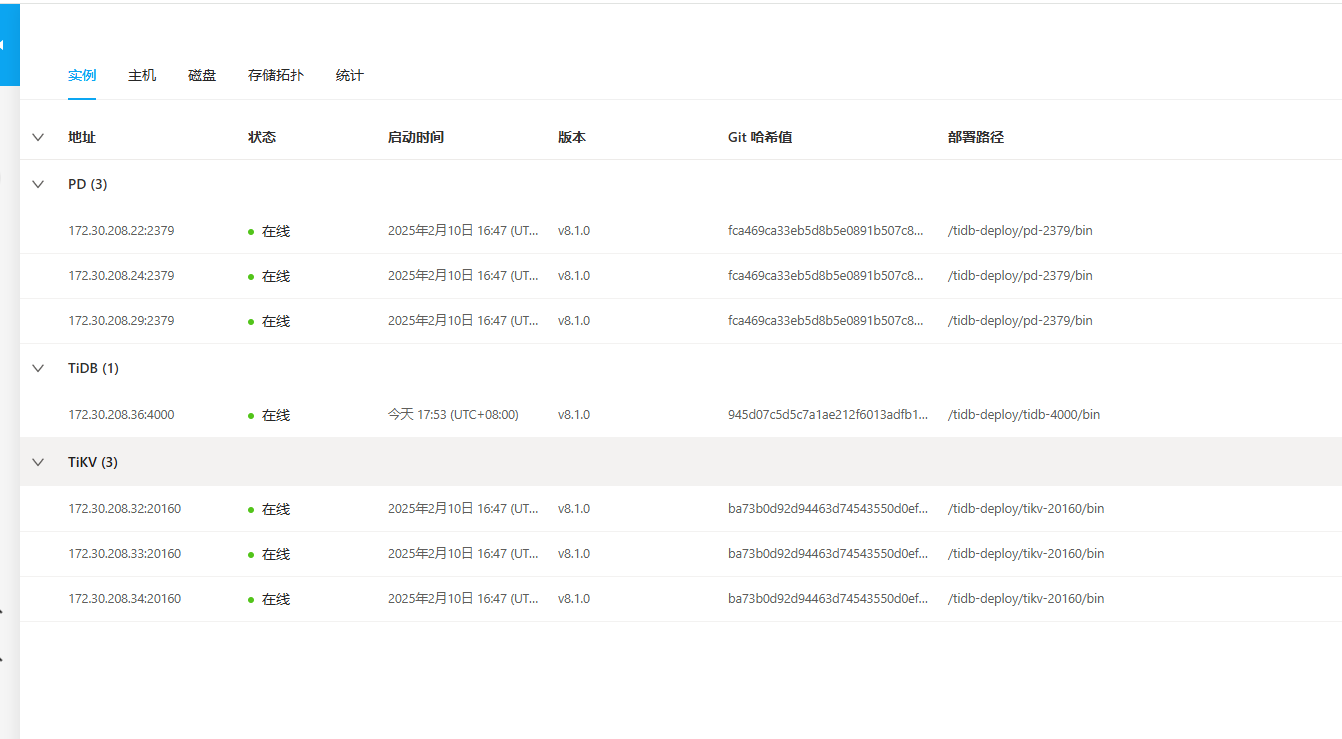
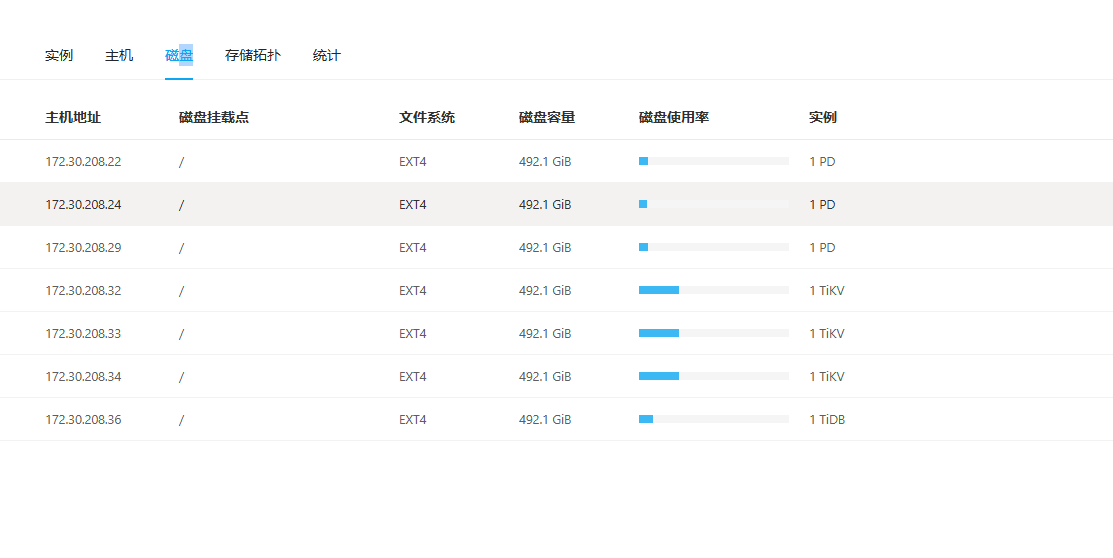
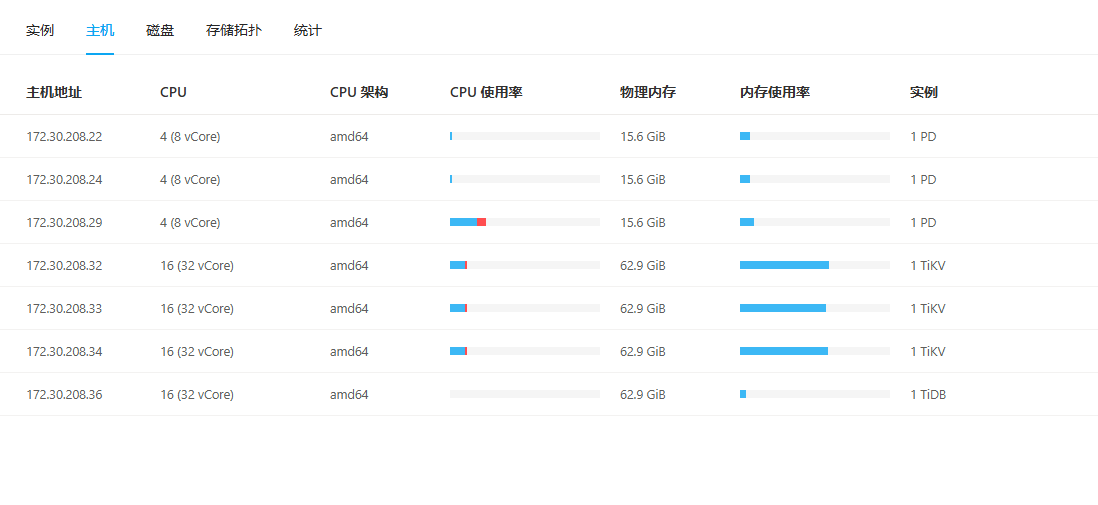
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
看一看你这一页的情况~
什么配置?
部署在虚拟机上的吗?
部署在云上的机器
抓一下 172.30.208.29 这台 PD 的 profile。这台 CPU 最高
另外,请下载一下原始 profile 上传上来。截图不好看
172.30.208.20 是另一个集群pd 都有同样的问题,下面的是抓取的profile
profiling_2025-03-28_10-58-46.zip (1.0 MB)
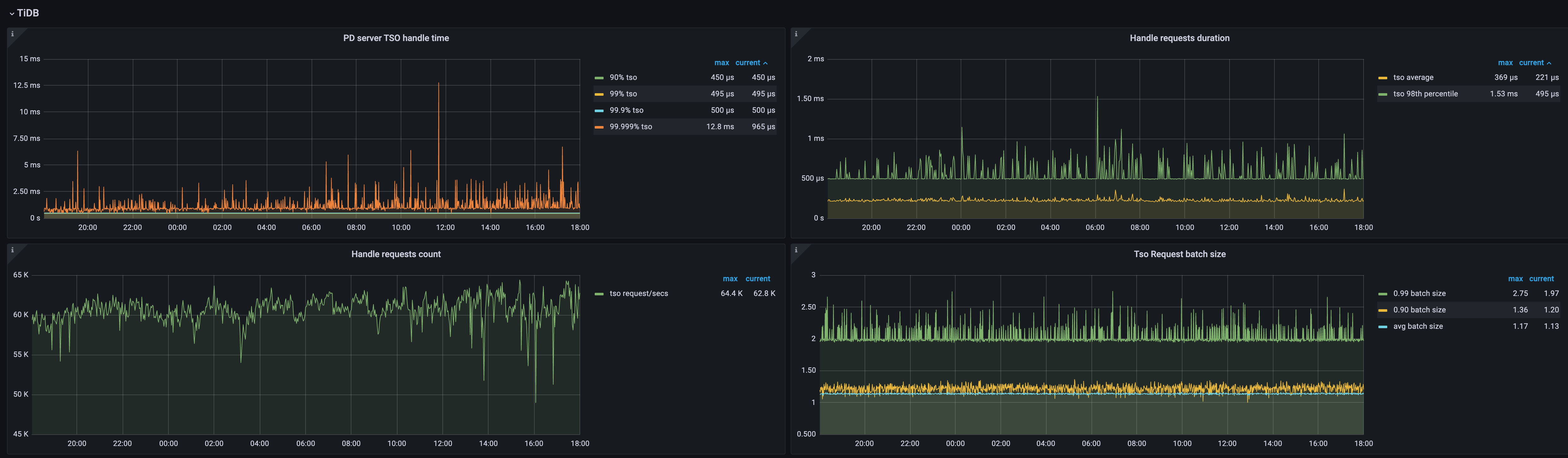
CPU profile 看着没什么问题
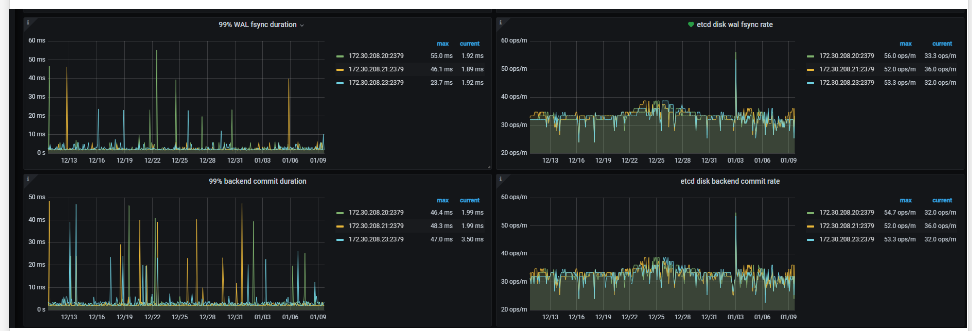
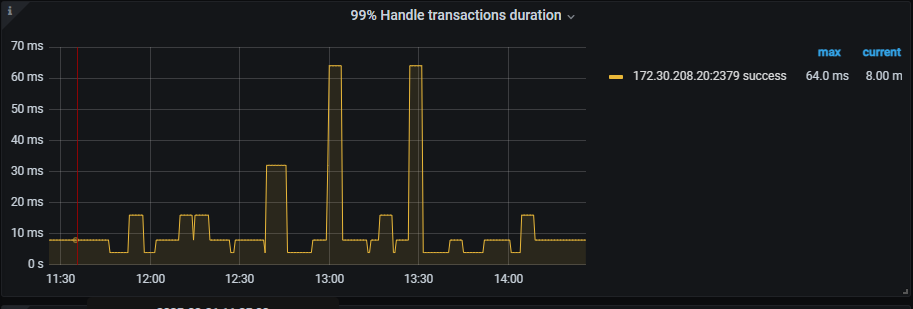
从目前已提供的信息,有一个疑点是 etcd 写延迟导致的。可以把 PD 的 etcd “99% Handle transactions duration” PromSQL 里的 0.99 改成 0.999999,然后与 TSO 的延迟对照,看是否相关
如果不是这里的原因,就只能在更大范围的数据里寻找线索了。建议提供 2~3 天的 PD 监控和日志,其中覆盖 2~3 次 TSO 延迟达到 10s 的情况。可以通过 clinic 采集,参考 https://asktug.com/t/topic/272957
改完之后三小时的