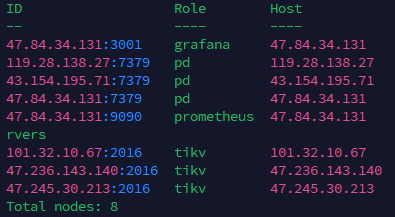
总total nodes 是8,我缩容了两台tikv的,为什么还是8,然后我想将那两台恢复是需要走scan-out扩容嘛?
总total nodes 是8,我缩容了两台tikv的,为什么还是8,然后我想将那两台恢复是需要走scan-out扩容嘛?
没有tidb节点,是被你缩掉了还是怎么回事?rawkv使用?
端口也是自己改过的。你虽然刚上手,就能看出来突出一个路子野,胆子大。
我不需要使用tikv,我只要pd和tikv就行了
目前还是测试阶段,要在生产使用不就得把所有能想到的场景进行验证一下
这样没gc吧。你要rawkv用的话,要注意自己通过client自己调用gc。
你现在这个问题我也没看懂,意思是你应该缩掉了2台,结果没缩掉是吗?
不知道为啥没缩掉,这个要看看tiup的日志。
但没缩掉是好事,3副本最多只能缩掉一个,缩2个就不满足raft组多数了。集群没法服务了。
看状态的话是缩容成功了,但我看集群状态节点还是八台,我原本是五台,我缩容成功了,现在是三台没毛病
![]() 没看明白,截图里数了一下就是8个节点吧,
没看明白,截图里数了一下就是8个节点吧,
1grafana+3pd+1prometheus+3tikv
嗯,我的问题,忘记还有Prometheus和granfan了
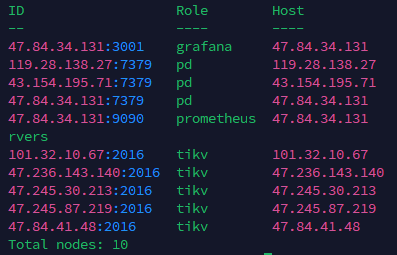
扩容回去后确实可行,但pd主节点是什么规则调度的tikv,这个有规则嘛,选择最优节点还是什么?
这是小问题。
rawkv使用的话,gc的问题还是要研究一下的,不然mvcc版本堆积, 性能越来越低。
我使用的事务:“github.com/tikv/client-go/v2/txnkv”
所有的操作都是走的leader,其他的pd只是和leader进行通信,那是不是说明,数据进出都是走的leader,其他的pd节点只是通信
![]() 应该是只有leader提供服务,其余的pd只是同步leader的信息。当leader挂掉之后,其余pd选举新的leader,保证高可用。
应该是只有leader提供服务,其余的pd只是同步leader的信息。当leader挂掉之后,其余pd选举新的leader,保证高可用。
我在客户端打断点,进出数据好像走的是http,不是长连接
是grpc ,基于http2构建的。具体看下面这个介绍。
http2是有长连接能力的。
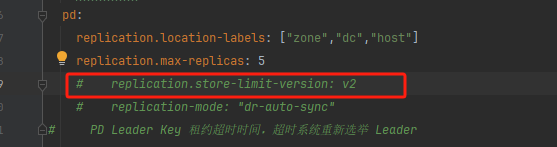
和这个没关系是吧
https://docs.pingcap.com/zh/tidb/stable/pd-configuration-file#store-limit-version-从-v710-版本开始引入
这个参数和调度有关,但是看了下记录是从调度聊到通信的。![]()
我刚才的回复,回的是这一条。
哈哈哈哈,好的,感谢
