【 TiDB 使用环境】生产环境
【 TiDB 版本】7.6.0
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】一台16C 48GB的虚拟机,部署了1PD 1TIKV 1TIDB 1TIFLASH
问题:内存满后重启服务器无法正常启动所有服务
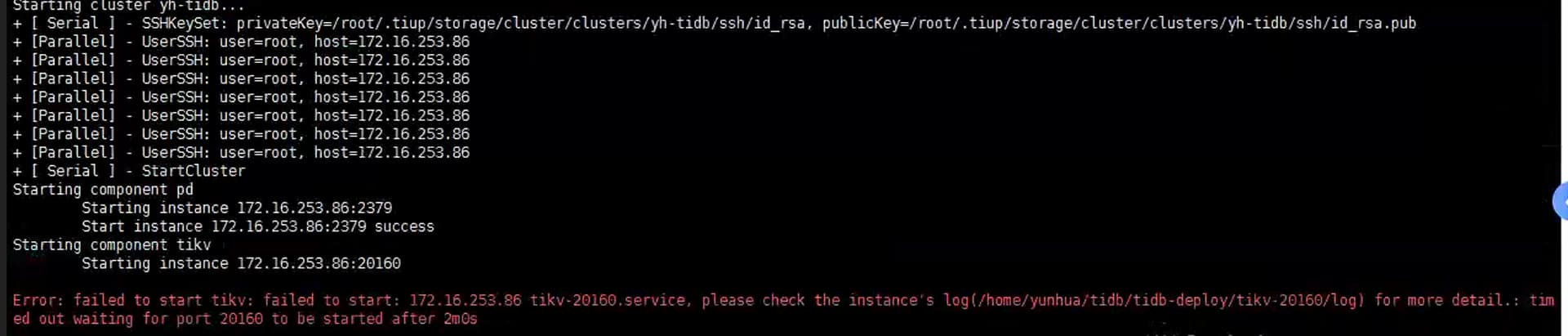
现象:只有PD启动了,但是启动日志有错误,错误信息见下图,其他组件都没有正常启动
更多日志见附件
pd.log (96.5 KB)
【 TiDB 使用环境】生产环境
【 TiDB 版本】7.6.0
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】一台16C 48GB的虚拟机,部署了1PD 1TIKV 1TIDB 1TIFLASH
问题:内存满后重启服务器无法正常启动所有服务
现象:只有PD启动了,但是启动日志有错误,错误信息见下图,其他组件都没有正常启动
tiup cluster scale-in 下线掉 tifalsh 节点
-N, --node 选择要缩容的节点,
单机不要这玩~
确实不应该这么玩,架不住技术干不过销售,非说要的资源多了,甲方不同意。
不过你说的下掉tiflash,可以解决启动问题吗
单机不要这么玩,很吃资源的
技术去和甲方交流后,一下大气了,直接两台物理机,但问题是现在的环境是崩着的状态
生产环境不要用 DMR 版本
有服务器了,扩容试试呢。
嗯,现在的问题是:先把服务启动起来,再才有可能把数据迁移到新集群去
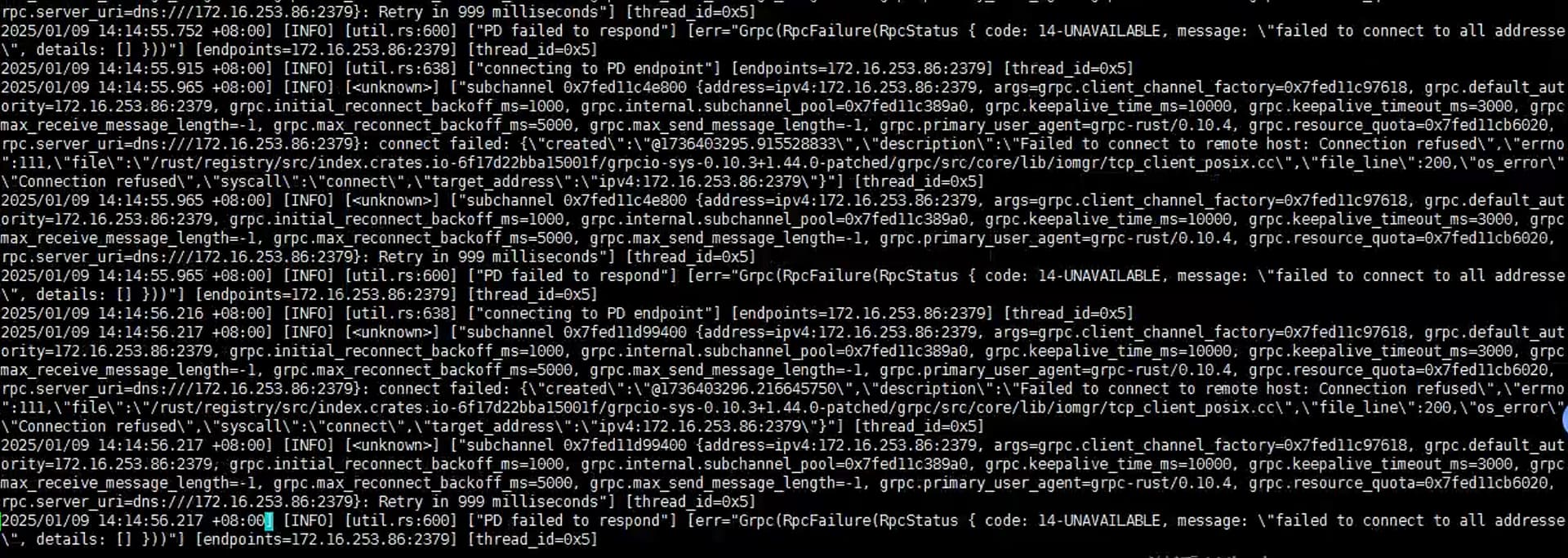
单独启动PD还是报这个错,不属于资源问题哦
display里面只有pd是up状态?
看看其他组件的错误日志
![]() 重启之后,是不是防火墙开了?检查一下防火墙,还有当前CPU、内存是否充足
重启之后,是不是防火墙开了?检查一下防火墙,还有当前CPU、内存是否充足
看日志是连PD有问题呀
非常的充足
有办法解决不 ![]()
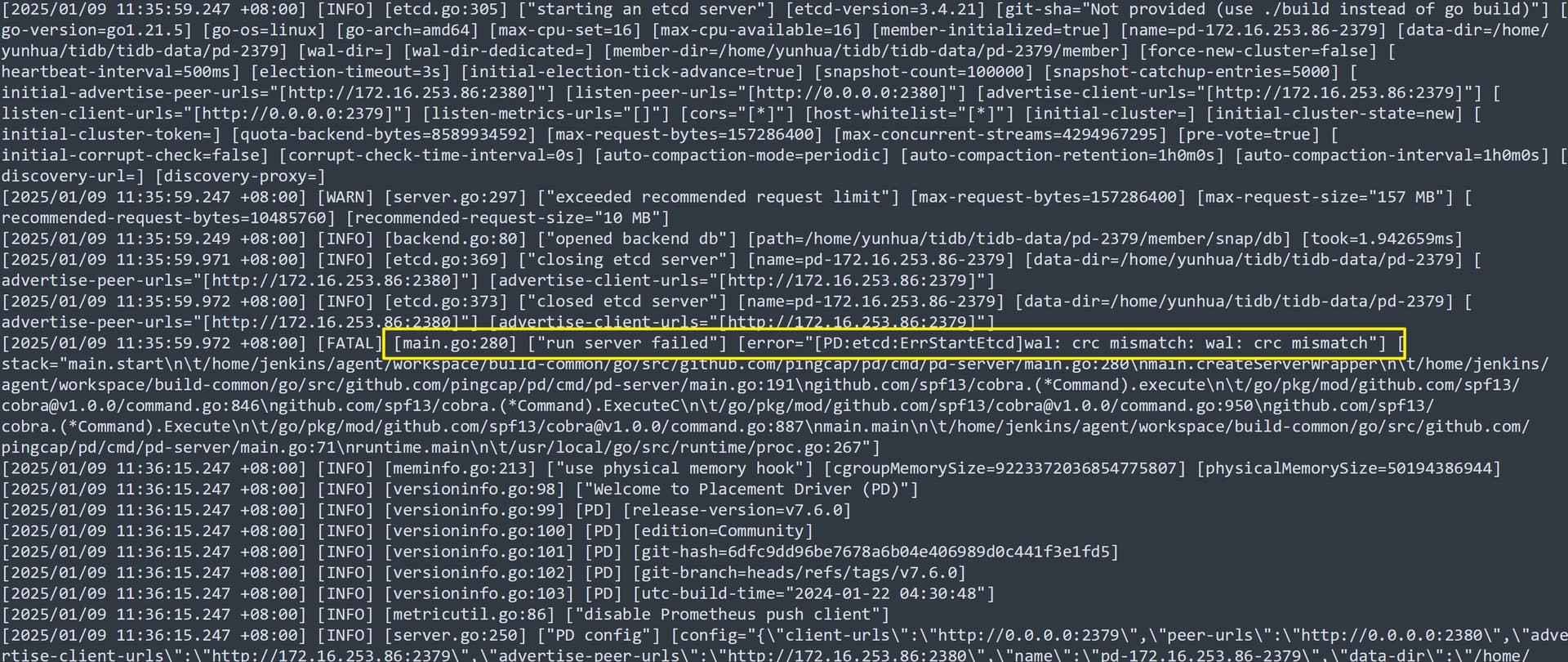
数据应该是坏了,都 cdc mismatch 了
pd日志里面有一段"[2025/01/09 11:36:15.254 +08:00] [WARN] [server.go:297] [“exceeded recommended request limit”] [max-request-bytes=157286400] [max-request-size=“157 MB”] [recommended-request-bytes=10485760] [recommended-request-size=“10 MB”]"
试试把max-request-bytes设置成10M试试? 不知道有没有关系 ![]()