【 TiDB 使用环境】生产环境
【 TiDB 版本】v7.5.2
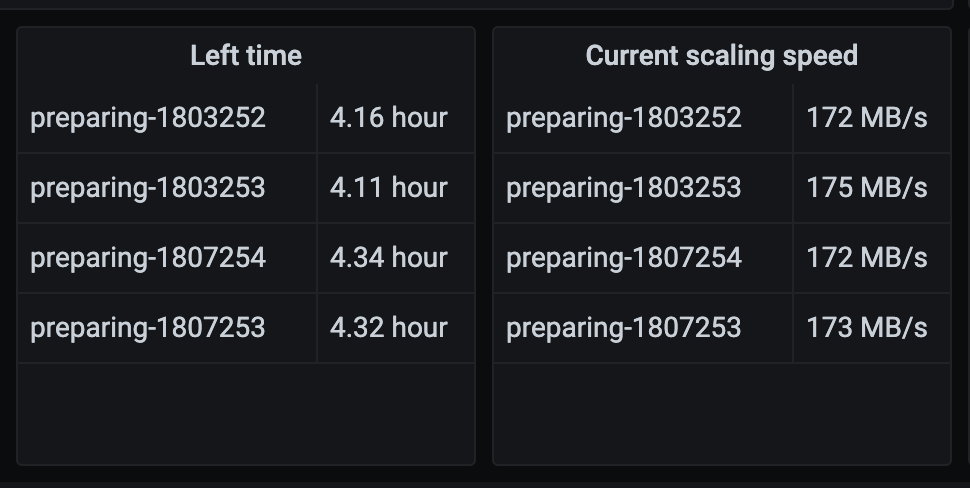
【遇到的问题:问题现象及影响】如何通过掉pd接口获取到正在有扩容tikv副本任务呢,类似如下图
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
1 个赞
感觉你说的不是扩容,而是副本迁移。这个是相关的API文档。
https://docs.pingcap.com/zh/tidb/stable/tidb-monitoring-api#pd-server
https://docs.pingcap.com/zh/tidb/stable/grafana-pd-dashboard#scheduler
确实是发起了tikv实例的扩容【scale-out】,我从grafana上能看到Current scaling speed的信息,region自动迁移完毕后这个页面自动就为空了,主要是想知道这个信息从PD接口里哪个key能看到是否tikv实例扩容的任务?
点进去看看公式。再找找对应的pd指标是哪一个。
点编辑之后就能看到了。
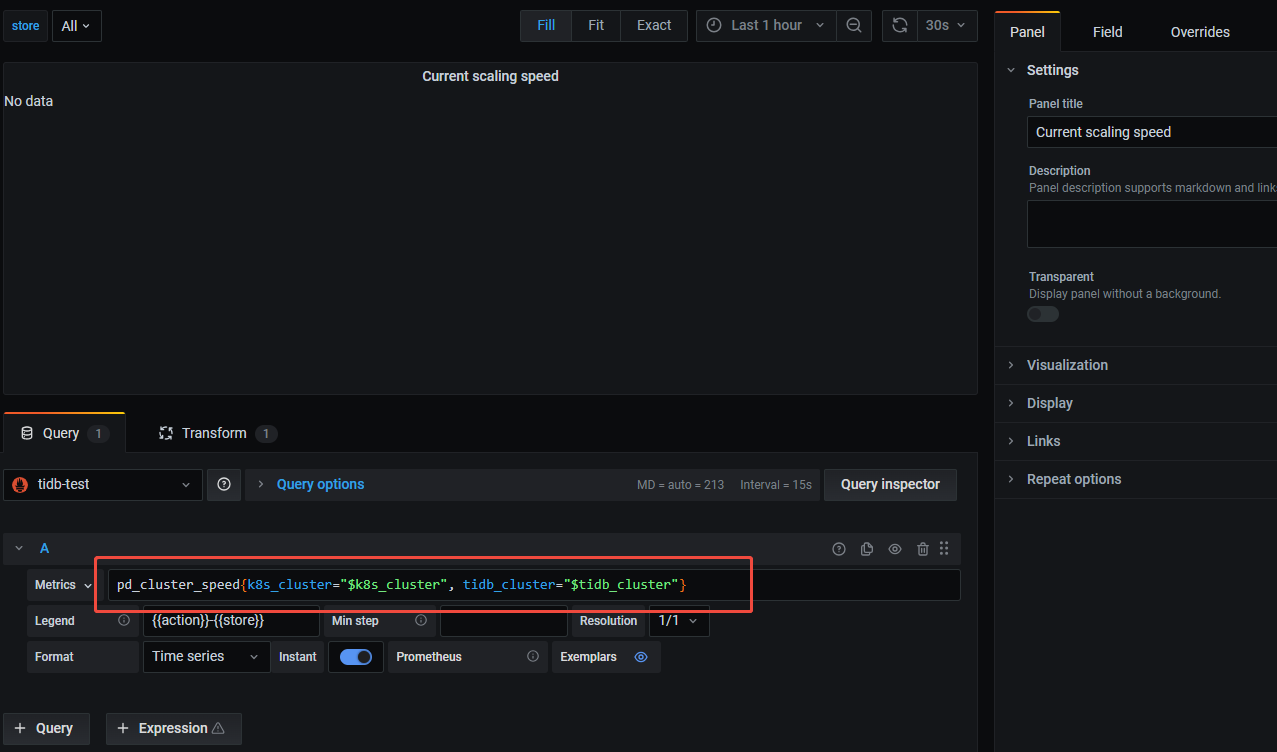
这个链接里官方有具体说明
https://docs.pingcap.com/zh/tidb/stable/grafana-monitor-best-practices#监控数据的来源与展示
1 个赞
我觉得这种情况还是最好从prometheus api访问里面取。而不是直接访问pd。
因为pd的承载的业务比较重要,访问的多了,如果造成pd本身不稳定是得不偿失的。
另外prometheus已经通过接口采集到了这部分数据的情况下,也没有必要从pd里面取。
https://docs.pingcap.com/zh/tidb/stable/release-8.5.0
支持限制 PD 处理请求的最大速率和并发度 #5739 @rleungx
当突然有大量请求发送到 PD 时,这些请求可能导致 PD 工作负载过高,进行影响 PD 性能表现。从 v8.5.0 开始,你可以使用
pd-ctl来限制 PD 处理请求的最大速率和并发度,提升 PD 的稳定性。
云上这个问题可能更突出,所以8.5版本可以控制pd的grpc的RPS。
1 个赞
tiup ctl:版本 pd -u IP:端口 operator show
这个可以看到一些正在操作某些调度任务的region
看过这个公式了,还挺复杂的,之前一以为从PD接口那里能获取到呢
调用PD的接口不会很频繁,只是做个监控而已,哈哈
做监控 自己做个shell脚本 定期执行检查一下得了
用python写一个监控脚本,自己想看什么都比较方便
1 个赞
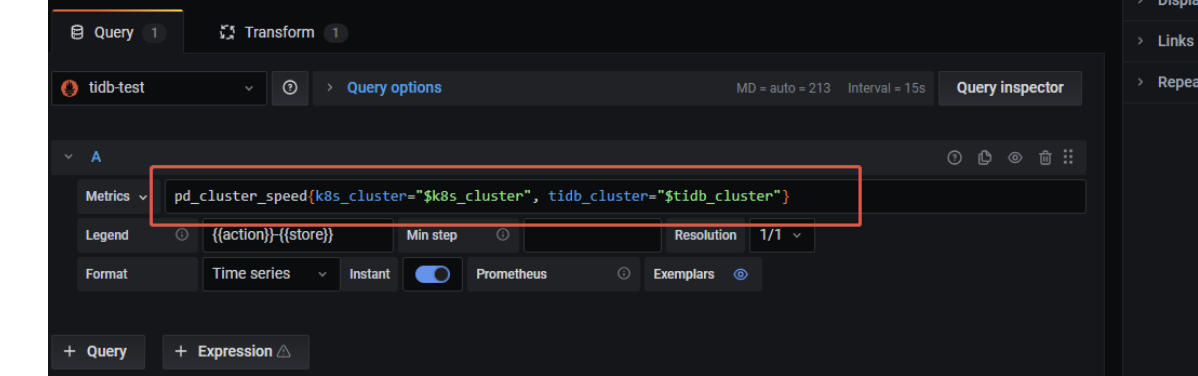
从prometheus api访问里面取,不要直接访问pd。
为何不能直接从pd接口获取呢?
pd接口有这个功能吗?
TiDB 不是已经有监控了吗,为啥还要弄?
想深入了解下原理
这些监控都是组件暴露 metrics 接口,然后 prometheus 自己去采集的
我再研究下,主要是想看到tikv实例在进行扩容,缩容,实例故障三类场景下,在prometheus上pd监控能看到【Current scaling speed】这个数据,如果没操作,这个数据是空白的,是不是因为这三个场景会出现schedulers任务了,所以才会有数据产生?
默认PD API接口: http://pd_ip:pd_port/pd/api/v1/schedulers返回的数据只有这五个任务
[
“balance-hot-region-scheduler”,
“balance-leader-scheduler”,
“balance-region-scheduler”,
“balance-witness-scheduler”,
“transfer-witness-leader-scheduler”
]
1 个赞
这得看 PD 的代码实现了,我不会 ![]()