在生产环境为客户部署时,发现客户提的需求无法满足,在此罗列一下客户的需求,大家看看基于TIDB数据库,要怎么样的架构设计才能实现。
客户准备两地三中心,两中心分布在中国南端海南,另一中心分布在中国北京,网络延迟在20ms,且存在较多次的网络波动,服务器是X86架构,Linux系统,最基础的要求是当数据库出现问题时能接近无感切换,且因为数据安全性要求高,需要保证切换前后的数据一致性。
这里呢,应用有一个问题,当主数据库切换到与应用不同城的节点时,网络传输的延迟极大影响应用使用,设置某些功能无法使用,因此要求数据库切换到不同城节点时上层的网络层和应用也要同步切换到对应城市节点。
还有一个需求是当一个乃至几个非主节点出现问题导致非主节点数据库卡顿或者不可用但是TIDB服务还在时,不能影响其他节点的数据库提供服务。
要求最大程度减少分片副本数量,缩小空间使用。
我在部署时遇到的最大的问题还是当我TIDB迁移到其他机房时,如何让上层的网络层和应用和文件同步应用也同步切换到对应城市节点,这个前端能感受到的时间最短甚至无感知且能确保切换成功,不丢数据。
客户在此基础上还想双活,不过这个需求让我回绝了,那如果想要进一步实现双活的话,这个架构整体上又该如何建设,除了TIDB外,上层又该存在哪些组件,如果都采用开源的软件的话,哪些适用?
1 个赞
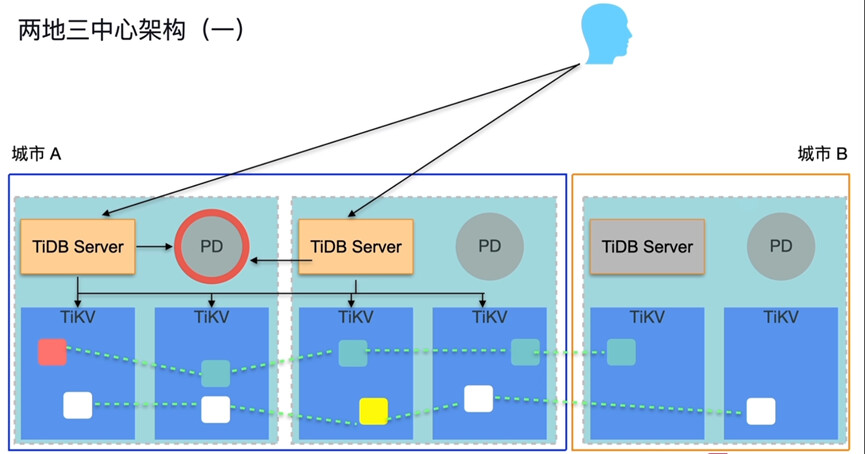
• TiDB集群部署:在海南和北京各部署一个TiDB集群,每个集群包括TiDB Server、PD Server和TiKV Server。TiDB Server负责SQL解析和执行计划生成,TiKV Server作为分布式存储层,PD Server负责集群调度和元信息管理。
• 数据副本分布:配置TiKV的数据副本策略,确保每个数据中心至少有一个副本,以实现数据的高可用和容灾。例如,可以设置为每个Region有三个副本,分别分布在海南的两个数据中心和北京的一个数据中心。
• 网络层和应用层切换:当主数据库切换到不同城市节点时,需要同步切换网络层和应用层。可以使用负载均衡器(如HAProxy)和DNS服务来实现流量的自动切换。例如,当海南的主节点出现问题时,负载均衡器可以将流量切换到北京的节点,同时DNS服务更新域名解析,指向北京的节点。
数据一致性和高可用性
• Raft协议:TiDB使用Raft协议来保证数据的一致性和高可用性。在主节点发生故障时,Raft协议会自动选举新的leader节点,确保服务的连续性。
• 数据同步:TiDB通过TiKV的分布式存储和Raft协议实现数据的实时同步。即使在网络延迟和波动的情况下,TiDB也能保证数据的最终一致性。
故障隔离和资源优化
• 故障隔离:TiDB的分布式架构天然支持故障隔离。当某个非主节点出现问题时,其他节点可以继续提供服务,不会影响整个集群的运行。
• 资源优化:为了减少分片副本数量和空间使用,可以合理配置TiKV的存储策略。例如,根据数据的访问频率和重要性,调整副本的数量和分布。
双活架构扩展
如果客户希望实现双活架构,可以考虑以下方案:
• 多活集群:在海南和北京各部署一个完整的TiDB集群,并通过TiCDC(TiDB Change Data Capture)实现两个集群之间的数据同步。我也觉得这个没必要怕出问题多弄几个tikv副本就得了6版本以后支持多副本
1 个赞
部署方式:20ms的延迟,更建议使用多主从集群部署方式【主在北京地域->TICDC->从在海南地域】
无感切换:这个实现起来比较难,毕竟探活集群故障也是需要花费时间,再加上决策…
非常赞。两地三中心提高系统的可靠性、可用性和灾难恢复能力。
可以参考专栏中的实践案例
1 个赞
海南到北京只有20ms延迟吗?你有实际测试过吗?表示怀疑。
这个网络延迟是设计方案的决定性因素。
如果真的只有20ms延迟并且稳定的话可以用官方建议的2地3中心方案,如果网络延迟较大切不稳定建议使用主从架构。
开源组件可以考虑这些,除了 TiDB 外,还可以使用以下开源组件来支持双活架构:
HAProxy:用于负载均衡和高可用性。
Consul:用于服务发现和配置管理。
Prometheus + Grafana:用于监控和可视化
网络开销太贵了, 得弄大通道宽带专线。
一般企业不敢主备切换。
cdc考虑
客户给的回复是20ms,但实际测试下来的效果你也能想到,这就是我说的很不稳定的问题。
这种无法解决磁盘空间不足导致的集群不可用。
什么架构都没办法解决这种问题吧 ![]()
负载均衡层和DNS服务如何判断需要切换流量并进行自动切换这是我们设计这个架构时遇到的难点。另外海南和北京应该加起来三个TIDB集群吧?要不然这个节点数怎么设计?
之前遇到的某个从节点磁盘空间不够,然后提交等待,导致整个集群卡住的问题。暂时没想到什么解决方案。
这已经是个很高的要求了,跨城容灾不可能是一个小课题,这只能说是客户对系统的复杂度考虑不足。 如果还要求 RPO 为 0的话,那要求就更高,只能是三地五中心,并且做强同步。
两地三中心,也能保证单中心故障。例如海南发生海啸,导致两中心都不可用了,北京的单中心,只能保证可用性,并不能保证 RPO 为 0。
这里边一般都是事件触发式,数据库层、中间件层、服务层分别来搞自己的切换逻辑,当真正故障发生时,通过发送事件的方式,各个层分别调用自己的接口来将流量切换到另外一个中心。
放心吧,机房容灾是一个特大故障,一般都是需要领导拍板来决定切不切,别太想着完全自动化。(没办法做到自动化的最大原因,其实就是上面讲的,跨城很难保证强同步,数据大概率会丢一些,得均衡一下成本,看是等待自愈还是主动切换)
1 个赞
增加监控啊,这种很容易提前发现的,TiDB 自身监控就有,还是没人跟进导致的。
2个集群,同城一个集群,异地ticdc同步
至于自动切换流量非常复杂,一般还是人工切
你让客户去咨询下运营商稳定的专线要多少钱,可能他就放弃了这种异地容灾的想法了。