【 TiDB 使用环境】生产环境
【 TiDB 版本】
【遇到的问题:】 执行此sql的时候很慢 想请问怎么优化
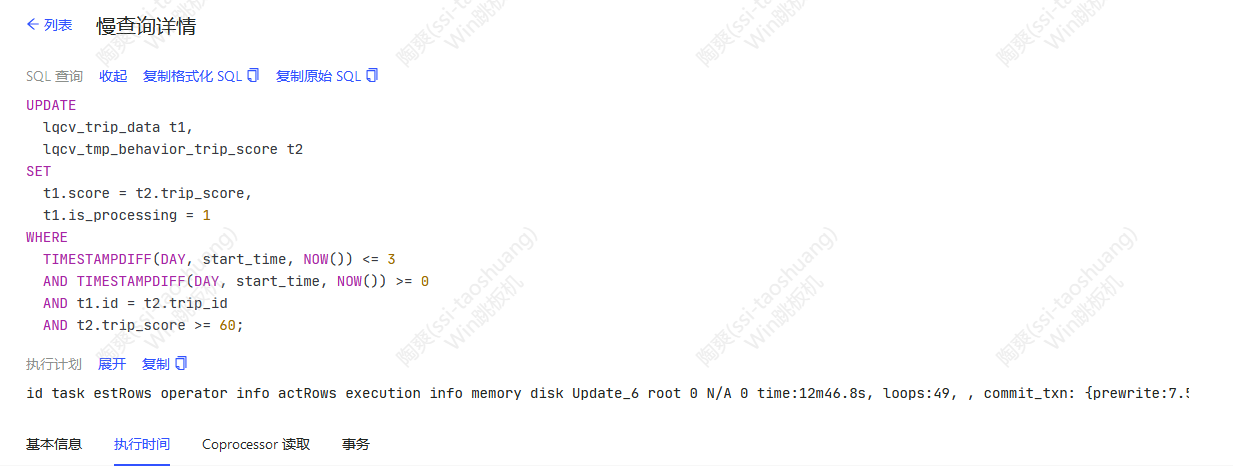
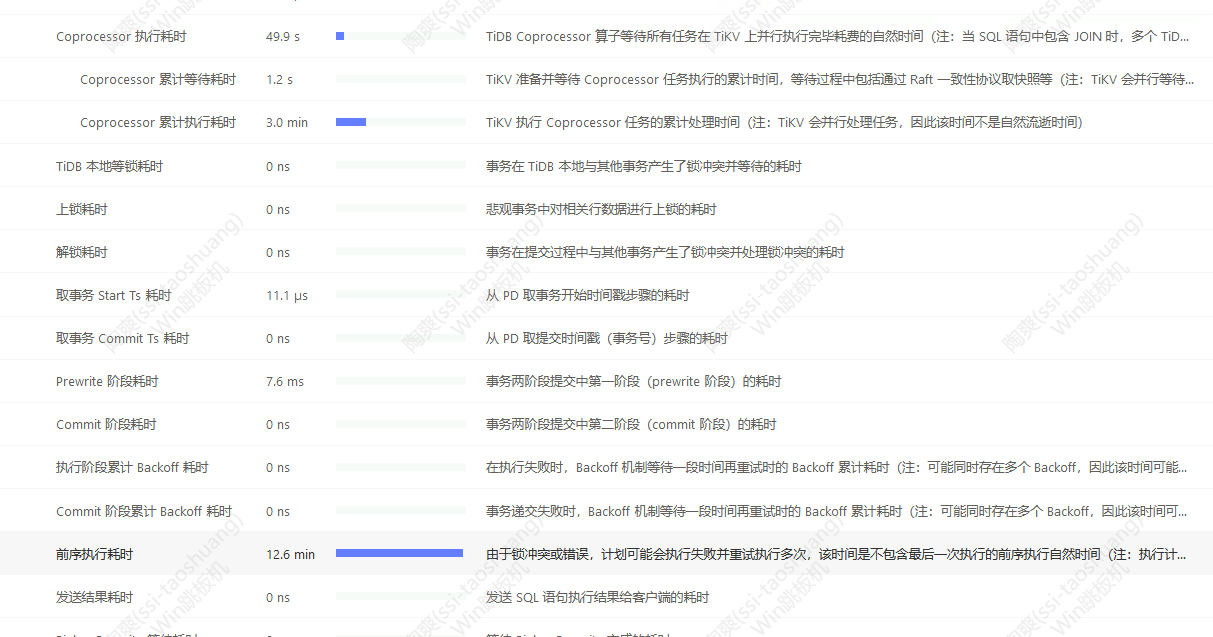
慢的时候可以需要40-50分钟
贴贴执行计划
先看看执行计划呢,确保正常走索引。
start_time上有必要用函数么?
缺少必要的条件,如哪些字段是索引,二个表的数据规模。
start_time这个,如果可以的话,不要函数;
从目前的条件来看,如果trip_score不是索引或者效率不高,SQL必定很慢
如果可能的话,尽量拆分成二个独立的SQL来执行,效率会高一些
1、t1 表的访问条件,start_time 字段要改写为范围条件,start_time 外不要套函数
2、看下 t1 表的结构,访问分区表要有分区键条件,否则走不上分去裁剪,你这里 start_time 是分去键吗,可以把 1 做了试试。
时间列加索引,时间列不要用函数处理,而是大于小于一个时间
确实挺难以判断,只能凭感觉,是不是要加索引,执行计划有没有走索引,范围查询可以改写……
你这全表改,还不如一条一条的改
大佬你好 我们按照这样改了 但是sql是快了很多 但是出现了一个很奇怪的问题 tidb的网卡下载带宽跑满了长期在2Gb 从慢sql里面看不到有慢sql 代码回退就没出现过了
大佬你好 我们按照这样改了 但是sql是快了很多 但是出现了一个很奇怪的问题 tidb的网卡下载带宽跑满了长期在2Gb 从慢sql里面看不到有慢sql 代码回退就没出现过了。。
![]() 按那种方式改的?改之后的sql和explain analyze执行计划发一下看看
按那种方式改的?改之后的sql和explain analyze执行计划发一下看看
update $tripData t1, lqcv_tmp_behavior_trip_score t2 set t1.score = t2.trip_score, t1.is_processing = 1 where start_time <= DATE_ADD(now(), INTERVAL 1 DAY) and start_time >= DATE_ADD(now(), INTERVAL -1 DAY) and t1.id = t2.trip_id and t2.trip_score >= 60
这是修改后的sql
这个写法看上去是没问题的,是否是因为数据都汇总到了tidb端然后导致的?或者不是这个语句导致的?
UPDATE lqcv_trip_data t1
JOIN lqcv_tmp_behavior_trip_score t2 ON t1.id = t2.trip_id
JOIN (
SELECT id, TIMESTAMPDIFF(DAY, start_time, NOW()) AS day_diff
FROM lqcv_trip_data
) t3 ON t1.id = t3.id
SET t1.score = t2.trip_score, t1.is_processing = 1
WHERE t3.day_diff <= 3
AND t3.day_diff >= 0
AND t2.trip_score >= 60;
1.考虑使用join语法
2.查看索引是否需要重建,比如你的 lqcv_trip_data表的id字段和 lqcv_tmp_behavior_trip_score的 trip_id 字段
3.简化一下时间的判断条件, 由于 TIMESTAMPDIFF(DAY, t1.start_time, NOW()) 会计算两次,可以考虑使用子查询或临时变量来避免重复计算
4.数据量如果太大太多的话,最终可以考虑批量更新,limit 10000或者更少,看你实际情况
