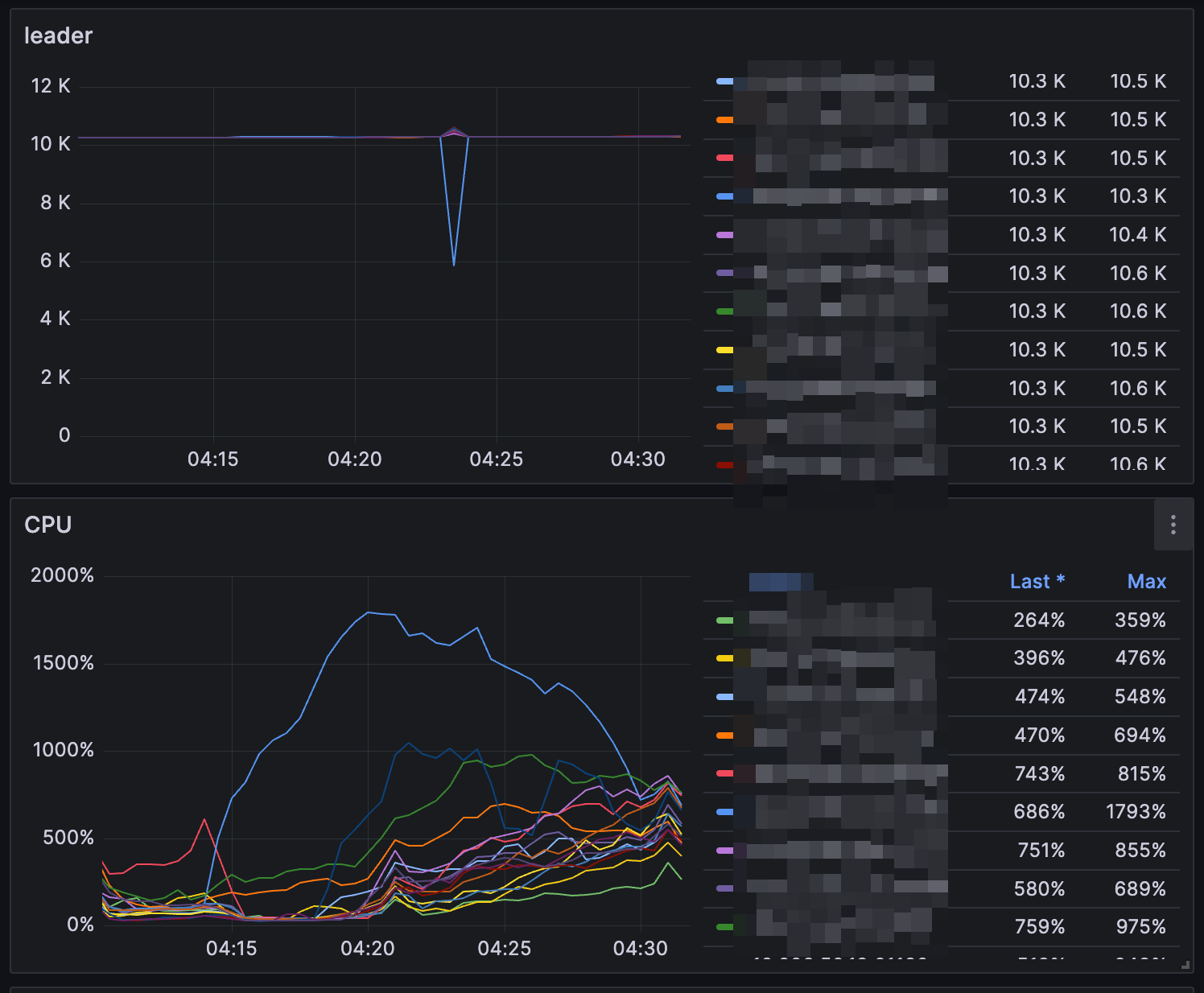
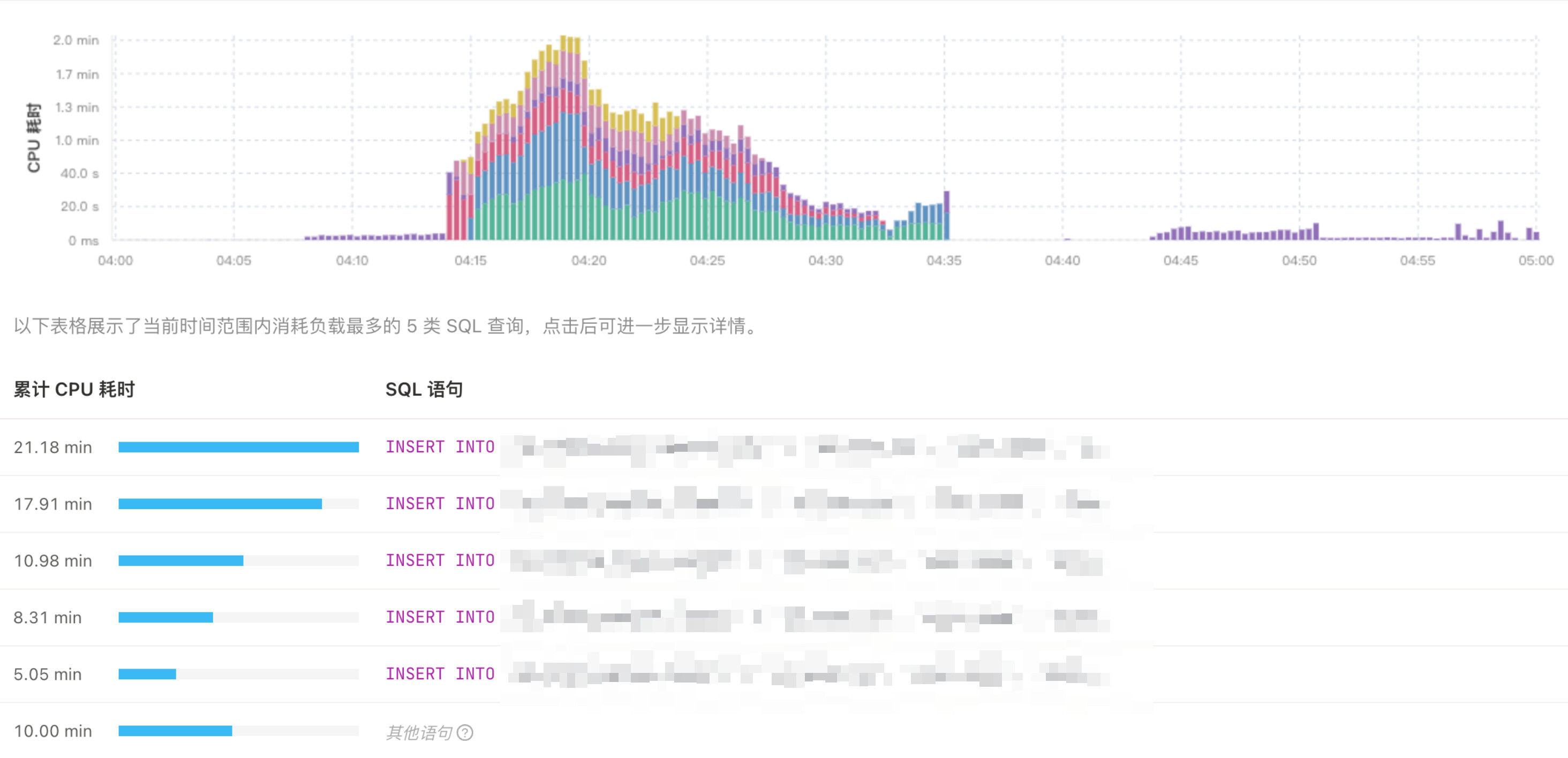
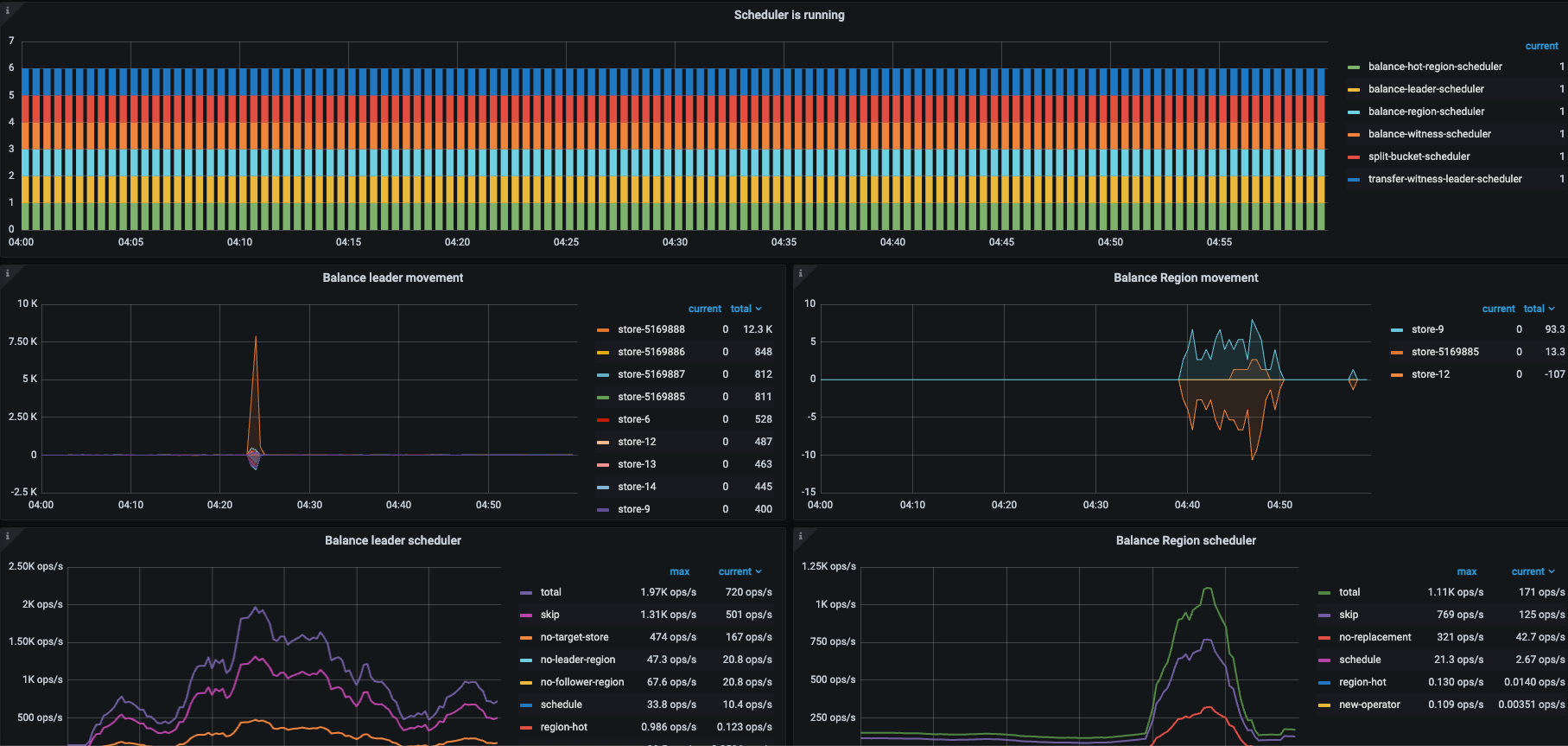
经观察业务高峰期(大约凌晨 4 点),在 6.5.7 上没有掉 leader 的情况,但是升级到 7.5.4 上发生了掉 leader 的情况,我们采用的是原地升级方式,配置都没有变,报错时间点 tikv 也没有 oom 的报错,我们的 TiDB 的部署方式为 tikv 节点单机多实例,一个机器上同时有 4 个 tikv 实例
之前也发生过一次类似的问题,通过修改 SQL 的方式规避了,但这次还是发生了这个现象,我比较担心找不到问题不敢往上升,而且 8.1 or 8.5 是否有这个问题也不太确定,麻烦大佬帮忙排查一下
大量插入的,可能是io问题引起的,比如磁盘响应速度过慢,导致了过载。
有猫万事足
5
掉leader的时间点附近, pd的日志里面,有这么一句嘛?
evict-slow-trend-scheduler captured candidate
1 个赞
h5n1
(H5n1)
8
tikv-detail → pd → store slow score 看看 ,还有leader drop时的磁盘性能
slow score 确实有增加,请问什么因素会导致这个增加呢,我查看过主机 cpu,网络,磁盘均没有瓶颈,就看到单机多实例中部署的其中一个 store 有热点写问题
1 个赞
h5n1
(H5n1)
10
你看这个store的磁盘了吗,一般这种磁盘出现问题的情况比较多,你的磁盘是什么类型的
磁盘没有满,要是满的话应该不会恢复把,单机多实例部署,每个磁盘都是 nvme2.0 ssd
WalterWj
(王军 - PingCAP)
12
你要不试试将 239 23180 的 leader 手动驱逐一下,然后观察下
看看tikv – cluster — IO utilization