1、 有什么方式可以禁用 由于磁盘慢后添加evict slow store

2、pd-ctl config中的这个参数具体含义是什么? 应该怎样调整可以降低evict slow store的敏感度。
"slow-store-evicting-affected-store-ratio-threshold": 0.3
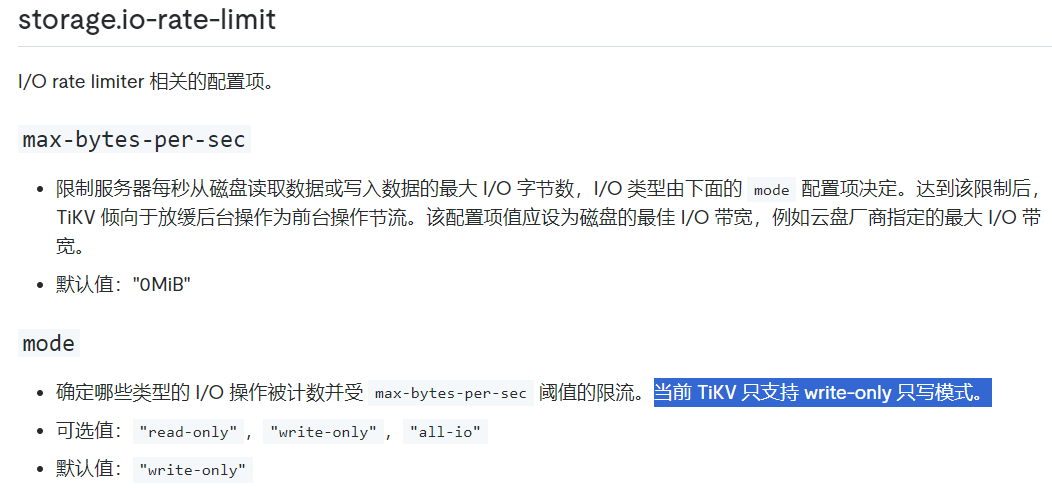
3、何时可以对磁盘读IO进行限制?
1、 有什么方式可以禁用 由于磁盘慢后添加evict slow store
2、pd-ctl config中的这个参数具体含义是什么? 应该怎样调整可以降低evict slow store的敏感度。
"slow-store-evicting-affected-store-ratio-threshold": 0.3
3、何时可以对磁盘读IO进行限制?
+1,我也觉得头疼,偶尔就会抖一下,很快就又能恢复。。
问题1: 有点没看懂,如果不手动添加evict-leader-scheduler 调度,就不会有evict-leader-scheduler调度,也就不需要禁用。
问题2:不手动增加evict-leader-scheduler调度器,就没必要修改这个敏感度了。如果担心磁盘空间较大影响集群,可以暂时"low-space-ratio": 0.8调整到0.9/0.95.
问题3:业务对延迟不敏感,io又有其他程序使用时,可以考虑限制tidb的io使用
1, 我也提问过
我大概看了下代码/ppt,粗浅的结论如下:
1, “slow-store-evicting-affected-store-ratio-threshold”: 0.3
这个参数的意思是,节点中有大于30%的节点被判断为慢节点,就会开始驱逐这些节点中最慢的一个节点的leader。也就是说只会一个一个驱逐。
这个0.3是指的整个集群中慢节点的占比。
所以你说的这个敏感度的问题就是数字越大越不敏感,越小越敏感。另外当数值是0的时候是不启用慢节点调度的。
如果节点数量小于3个,也不会触发这个调度。
具体的代码在
https://github.com/tikv/pd/blob/master/pkg/schedule/schedulers/evict_slow_trend.go#L454
2,慢节点的判断
这个逻辑有2个ppt来讨论,巨复杂。
顺序来是
https://docs.google.com/presentation/d/1oLpH8_s8tjKdZryRQWk2QvMWqL6m1FlvgEctZSMziXg/edit#slide=id.g17c2c0653a9_0_1076
和
https://docs.google.com/presentation/d/1TsCp2NcR8vgKs7heslApVEkVPEBhGSULyRMerdtt7kg/edit?pli=1#slide=id.g1d23a852ea4_0_310
第一个ppt讨论了readpool和qps的关系。
简单总结一下,当readpool中队列没有积压,而且readpoot对应线程池中没有空闲线程的时候,意味着集群的整体性能达到最佳,qps达到理论上的最大,没有队列等待也没有空闲的线程,物尽其用。
当有队列等待也没有空闲线程的时候,认为这个节点的负载已经开始增大。
同理无队列等待,有空闲线程,认为这个节点负载不满。
第二个ppt,先是在第一个ppt的基础上,使用请求在队列的等待时间,替换原来的模拟写入总时长,作为衡量一个节点是否已经开始变慢的输入指标之一。
然后就是给这个请求在队列的等待时间做了一个短中长的平均值,用长期平均值-短期平均值作为趋势变化的跟踪指标。
顺便说一下,如果你有股市经验的话,这个就是技术流中常见的趋势跟踪法。短期均值-长期均值为正数,即短期均线上穿长期均线——均线金叉,意味着趋势上升,反之则是死叉,趋势下降。 ![]()
当队列等待时间的趋势上升,同时间该节点的每秒请求数(RPS)趋势下降,两者同一时间发生反向波动,则认为节点消息的堆积导致了qps的下降,这个节点是慢节点。
除了这些主要的逻辑还有一些细节,我也没太明白具体是怎么做的。比如过滤掉尖刺什么的。
这块代码上的实现逻辑没有仔细跟踪,根据ppt上的内容整理。
![]() 我现在用这个替代了。
我现在用这个替代了。
1.关闭这个功能的话,使用 pd-ctl 删除 evict-slow-store-scheduler 即可
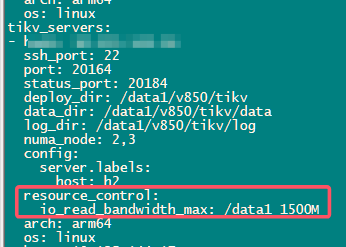
2.要降低敏感程度,调高这个也是个办法 raftstore.inspect-interval,减少 TiKV 侧检测 slow score 的频率
这个感觉是超时阈值吧。
“该配置项设置检测的时间间隔。当检测的延迟超过该时间” 你看这句 前面说是间隔 后面又表述的是个阈值
官网没写错,我确认了下:这个参数是检查频率 + 超时阈值
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。