【 TiDB 使用环境】生产环境
【 TiDB 版本】6.5.2
【复现路径】无
【遇到的问题:问题现象及影响】
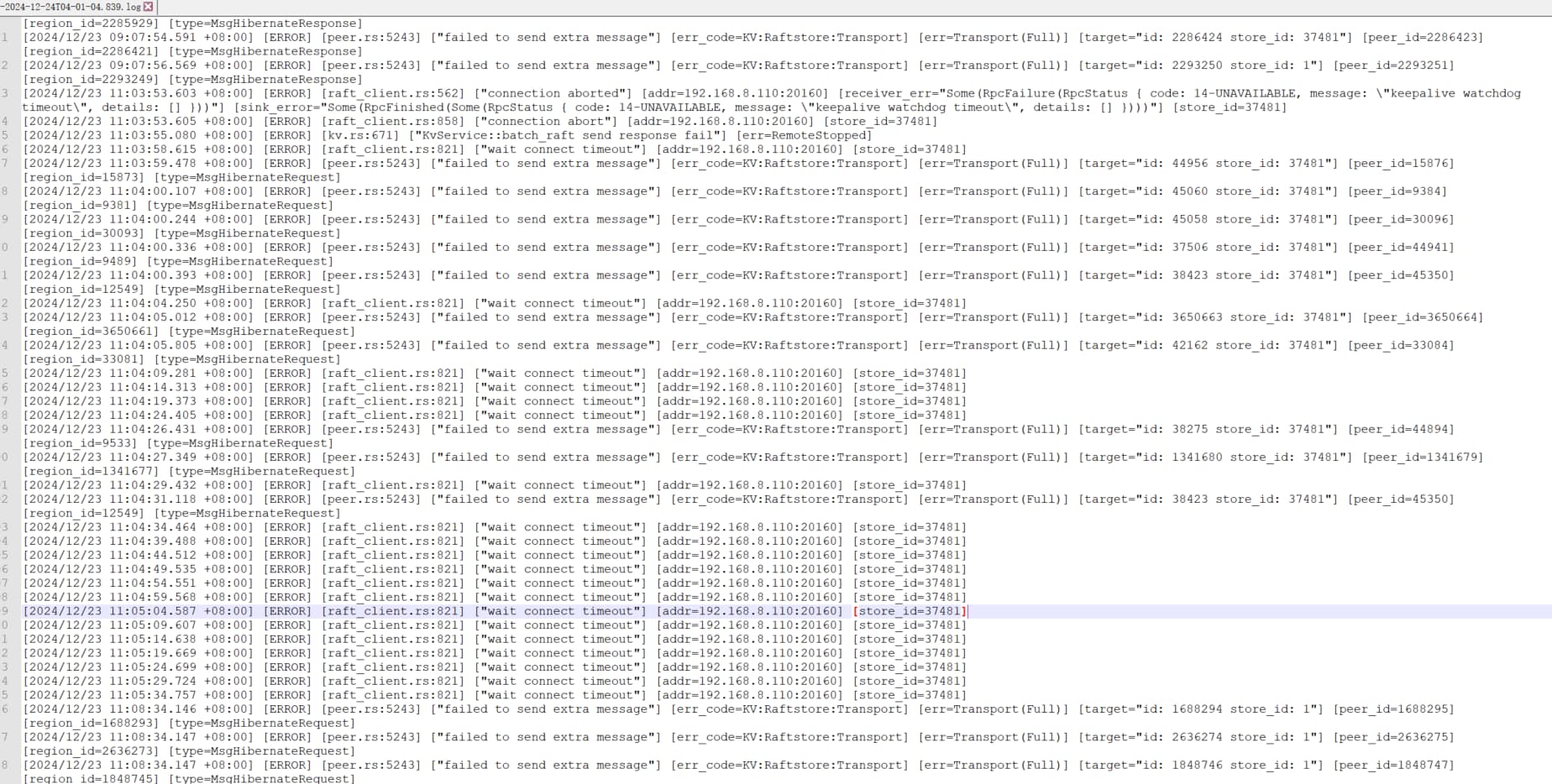
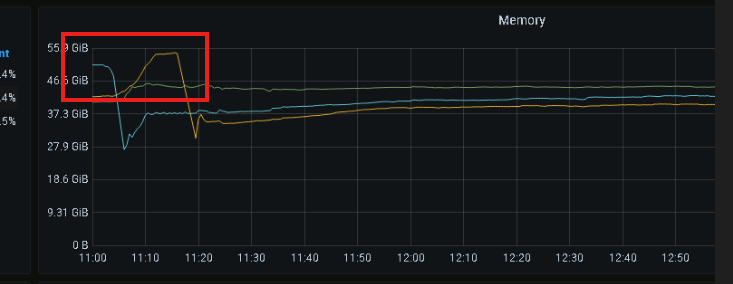
生产环境接口响应慢,卡顿
【资源配置】

【附件:截图/日志/监控】
千兆的网络环境么
网络是万兆
看看服务器tcp连接数是不是满了
192.168.8.110是不是掉线了
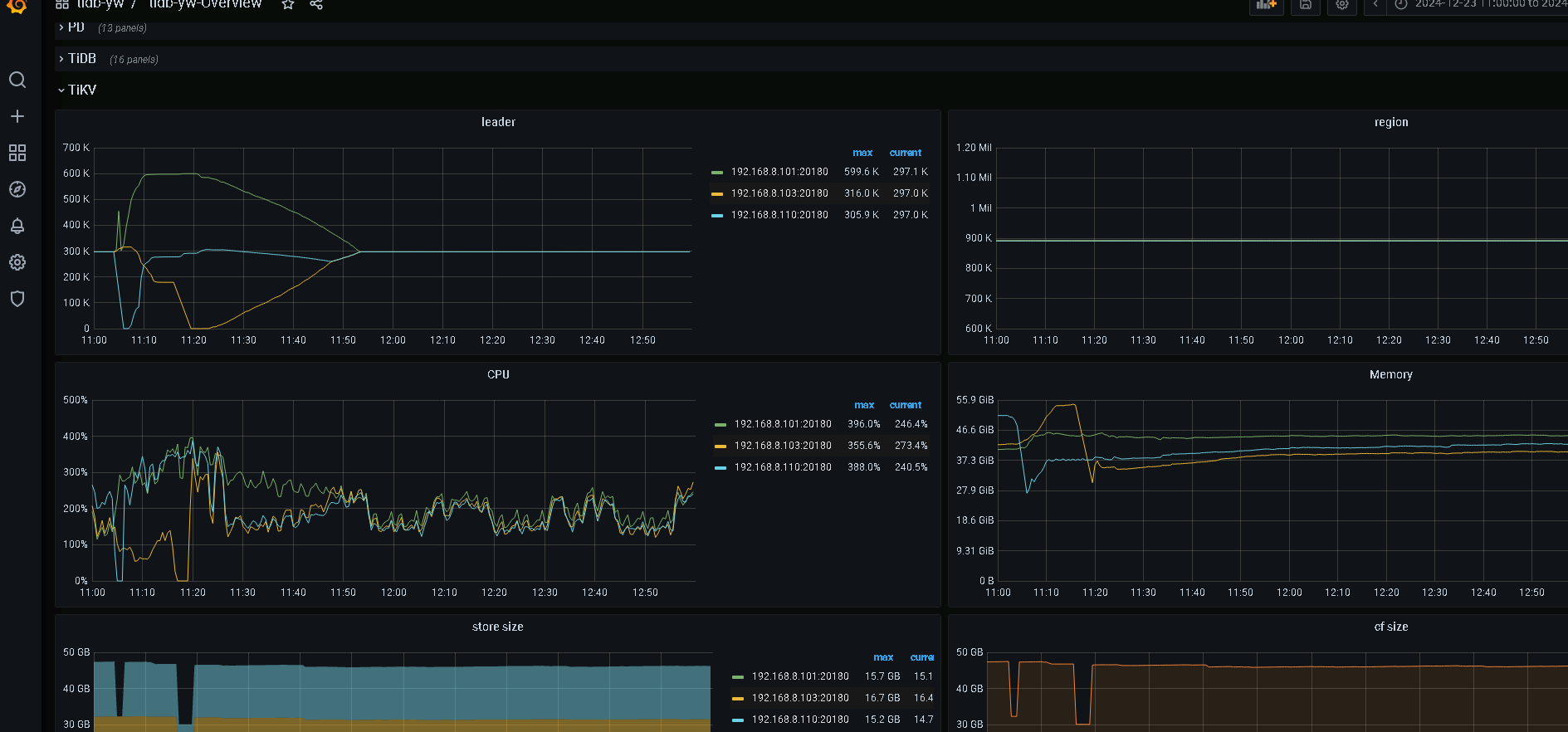
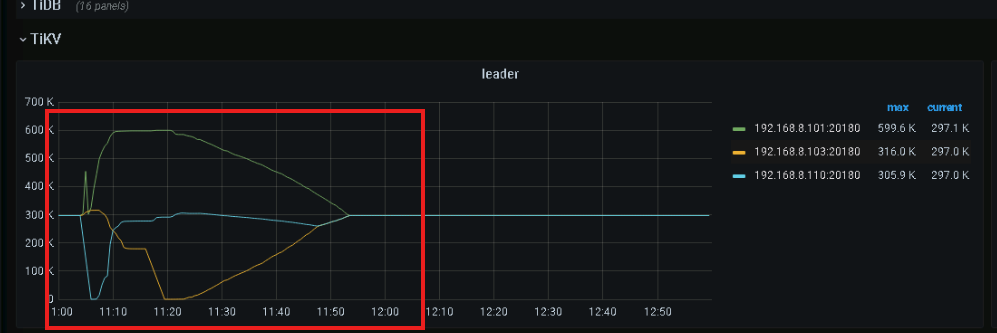
几十 GB 的 store size,但是单个 tikv 节点却有 90w region 。这个肯定是有问题的。可以看看 pd 监控为啥这么多 region。空 region 或者调整过 region 大小?
然后报错大概率是因为 某个 tikv leader 掉底,触发 region 重新选举,短时间选举消息把 raftstore cpu 打满了。导致你 tikv 的报错。leader 掉底的原因可以详细排查下。
tidb-server和tikv混合部署的话,建议将tidb-server和tikv的内存严格限制,怀疑是内存争用导致tikv重启,然后产生了leader 迁移。
内存问题导致kv重启
能看下你的pd监控吗?这region数量多的离谱
网络协议栈需要足够的内存来维护连接状态、缓冲区等。内存不足,TCP/IP 栈可能无法有效地处理新连接或现有连接的数据包,导致连接超时或断开。引起一系列的问题。
3台机器每个机器1pd1tidb1tikv经典混部。
这种情况下,内存的参数要特殊调整的。
https://docs.pingcap.com/zh/tidb/stable/hybrid-deployment-topology#混合部署的关键参数介绍
看看这个,再看看自己部署的时候是不是没有调整这些参数。
服务器配置太低了把
3节点混合数要限制tidb和tikv内存的,否则一定会oom
混合部署一个是tikv内存,这个需要tiup配置参数才能永久生效,实际占用内存按storage.block-cache.capacity设定值的1.5倍计算
例如:
tiup cluster edit-config tidb-test
tikv:
storage.block-cache.capacity: 3GB
另外tidb-server内存限制用sql命令配置:
set global tidb_server_memory_limit=‘30%’;
服务器配置什么
先看看overview下的system info里的系统资源信息是不是有瓶颈,在看下tikv日志是不是有Welcome关键字