【 TiDB 使用环境】生产环境
【 TiDB 版本】V6.5.9
【复现路径】无操作
【遇到的问题:问题现象及影响】21:10:08 左右,发现tiup 出来的所有的pd-server 都是down状态,整个集群数据无法访问
【资源配置】
【附件:截图/日志/监控】
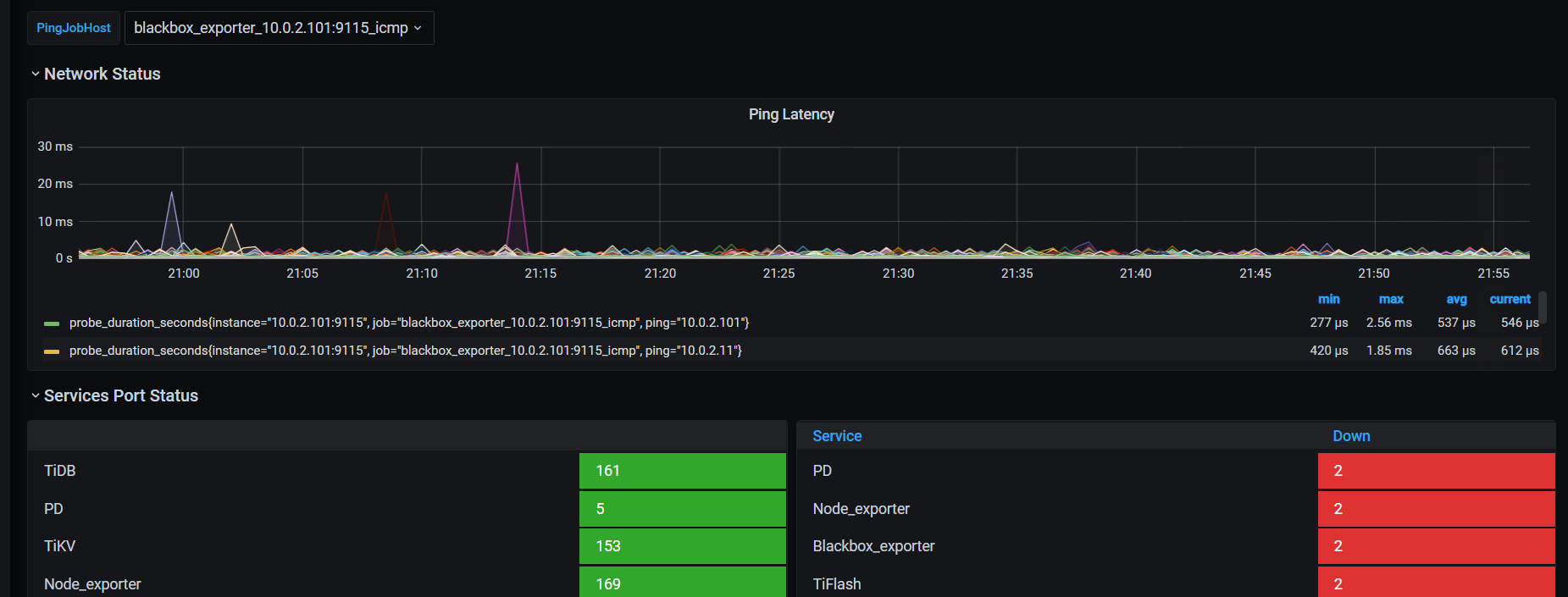
1, tiup 出来,所有的pd-server 都是down 状态

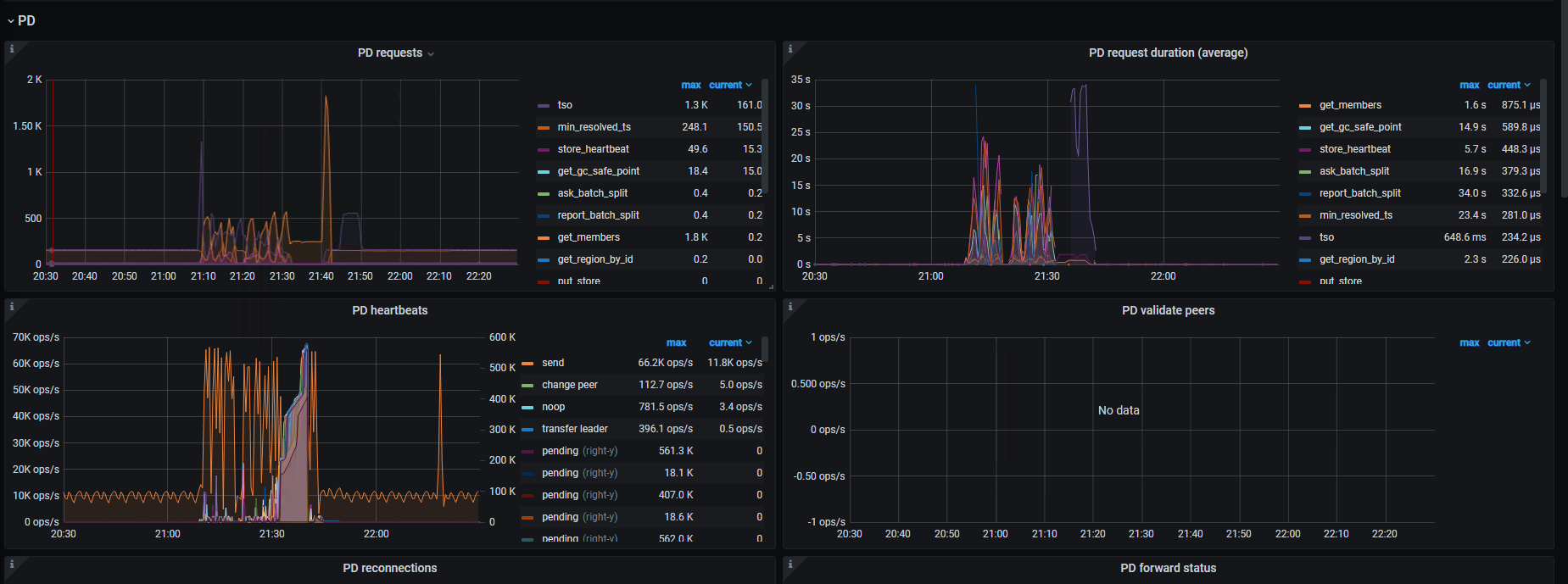
2,部分pd-server updatetime 在监控上出现跳变。
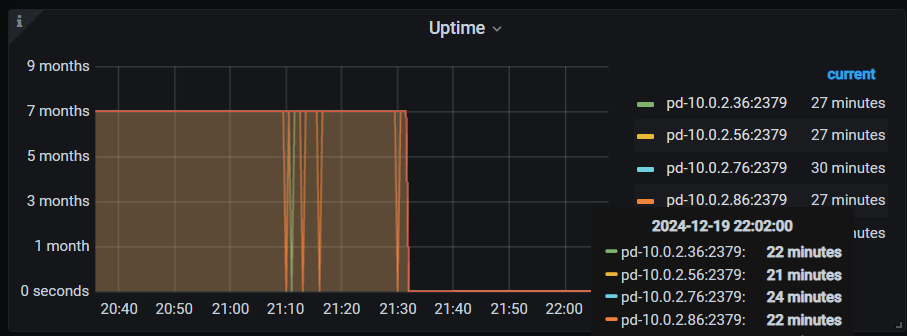
在21:30 左右,手动进行了重启
3,10.0.2.86 pd-server 出现大量的如下日志:

4,PD-SERVER 中,有 leader is overloaded 日志

5,发现在出问题前短暂时刻,有tikv 上的leader 被逐步全部切走

6, PD → etcd → 99% Handle trasaction duration
7, PD → etcd → 99% peer round trim time seconds

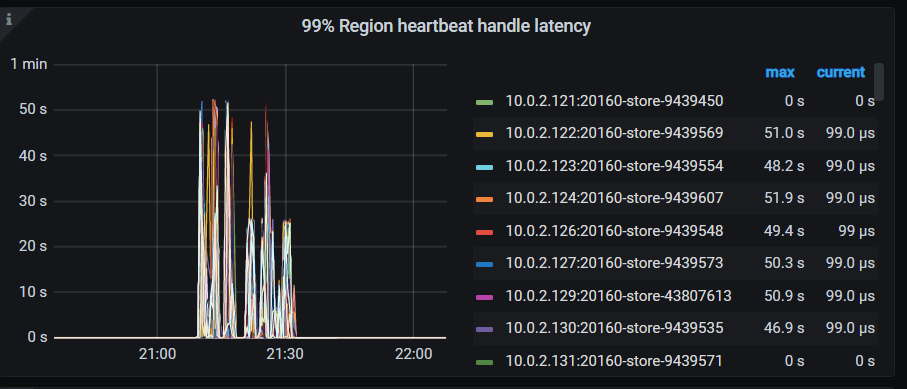
8, PD → Heartbeat → 99% region heartbeat handle latency
9, PD → HeartBeat → 99% store heartbeat handel duraction
10, 参考这个专题,
tikv-details → PD → Store Slow Store
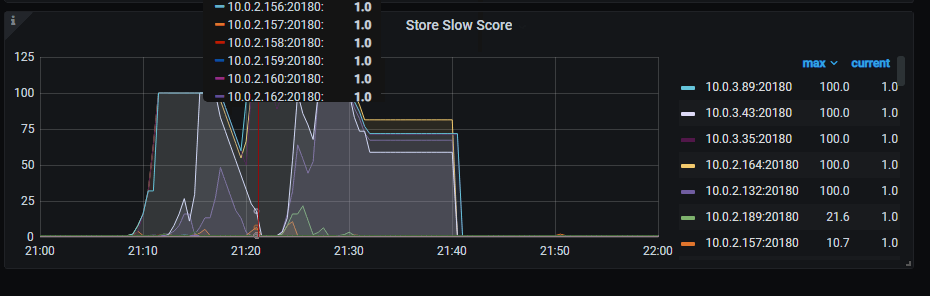
11,日志有send keepalive message fail, store maybe disconnected ,PD 给 Store 发送信息失败,认为其有可能失去连接。

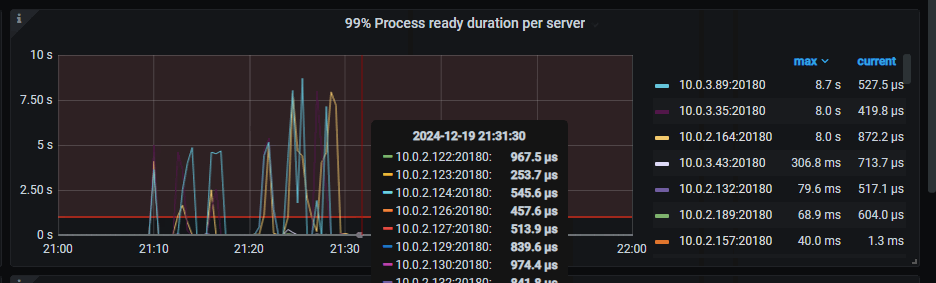
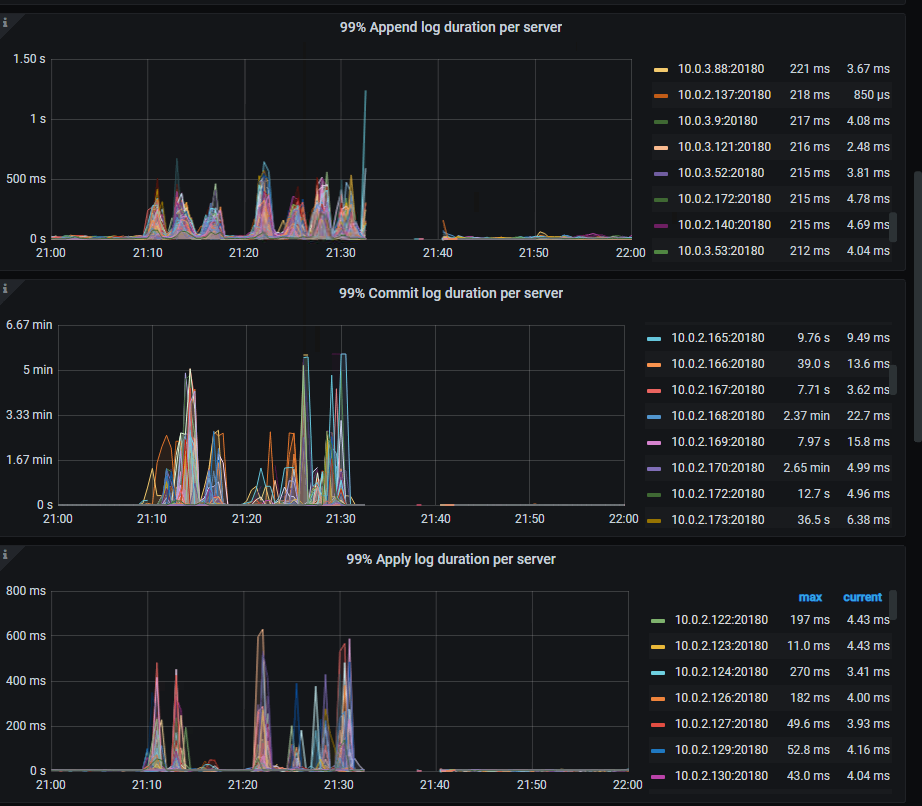
12,TiKV-Details → Raft IO → 99% Process ready per Servre
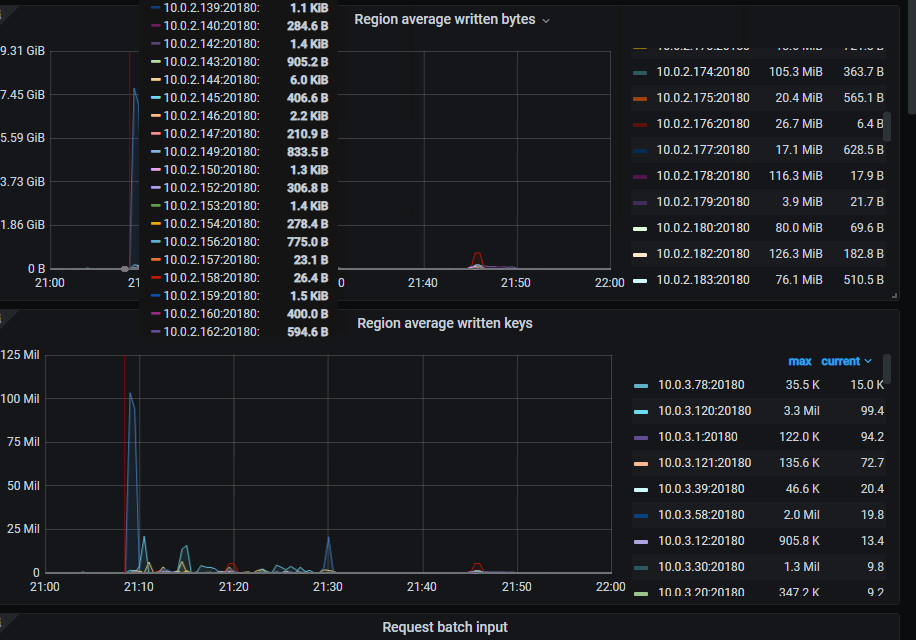
13, tikv-details → Region average write bytes
在出问题前(大概率是根因)有一个大量的写入
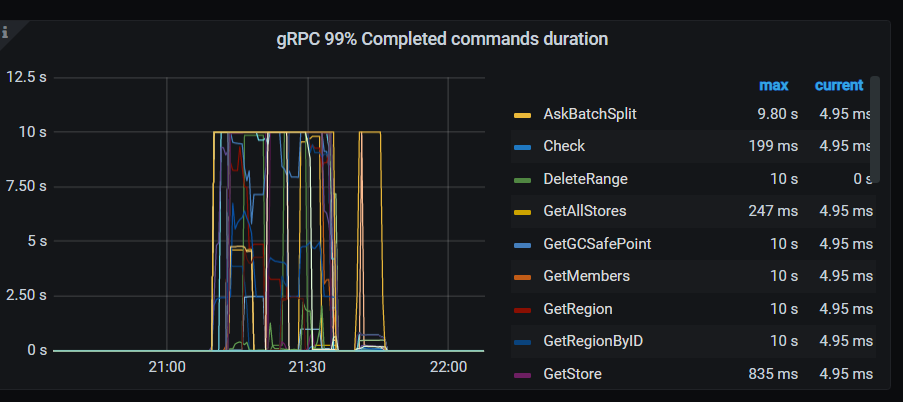
14,Overview → PD → 99% completed cmds duration seconds

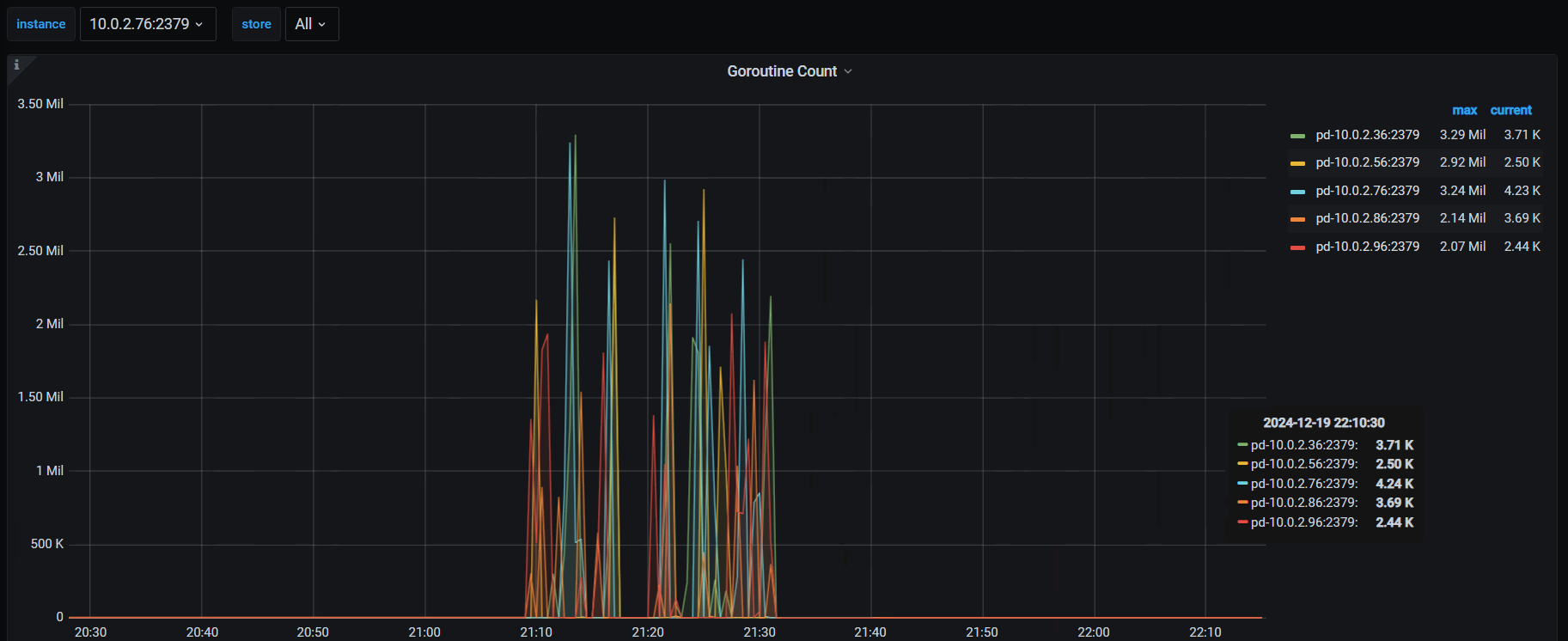
15,PD → Cluster → Goroutine Count
15 PD-> Cluster → CPU Usage & Memory Usage

推测,大概原因某时刻大量的写入,导致某几个tikv节点磁盘存在平静,pd-server认为某几台tikv-server 为慢节点,从而对某个Store(tikv)节点上的Region 的leader角色进行了驱逐。
PD 负责管理 TiKV 集群的调度任务,比如副本调度、负载均衡等。如果集群的负载波动较大,或者数据分布不均衡,在这个case中pd-server 发起了大量的leader 驱逐,PD 频繁进行调度操作,从而导致较高的 CPU 和内存使用。
进而诱发pd-server 响应网络请求不及时,导致tiup 无法获取pd-server信息,进而认为其为 down的状态。
需要处理的问题:
1,找出写热点业务,对表结构和数据分布进行优化?
跪求大佬,帮忙分析下这个问题的原因