liusf1993
(Liusf1993)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.11
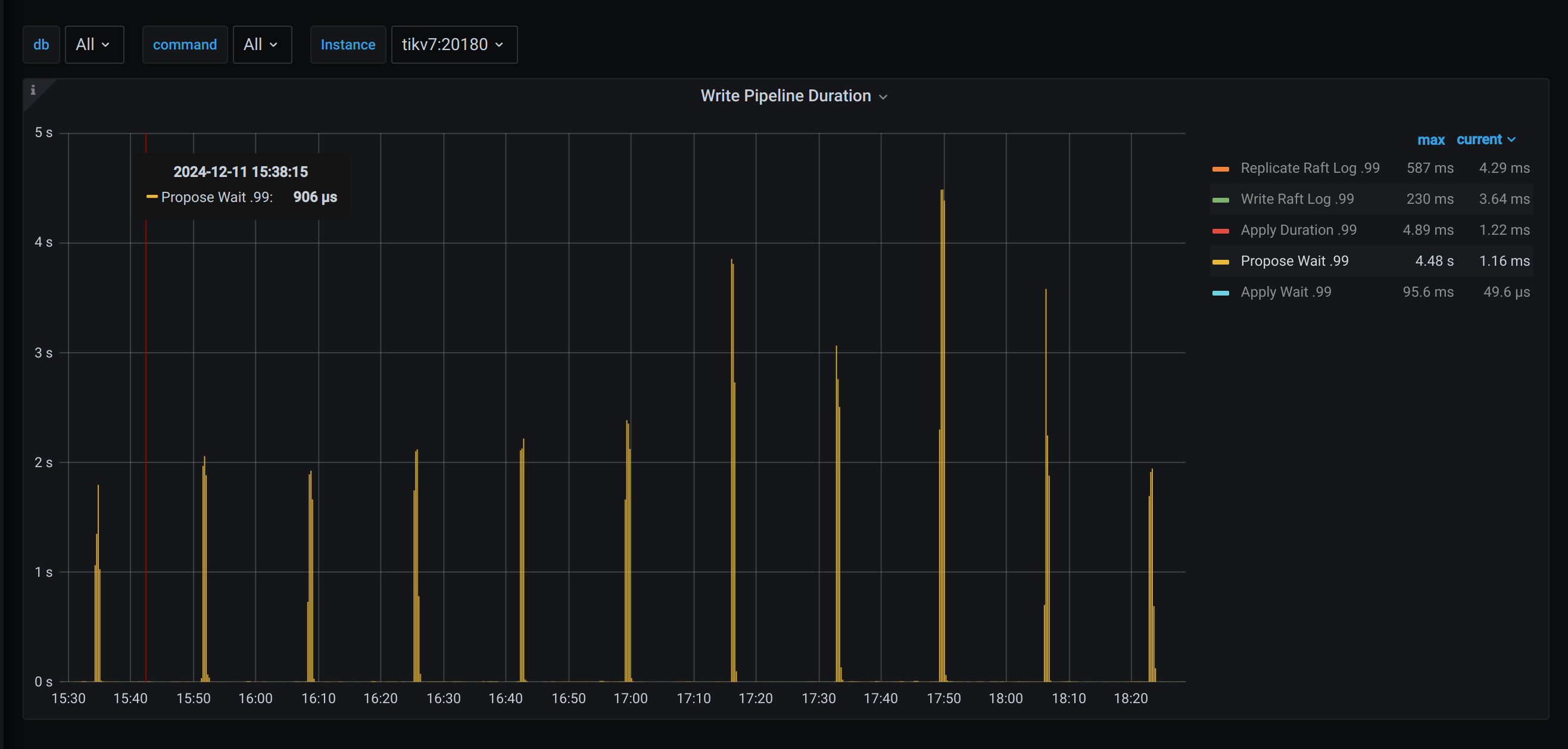
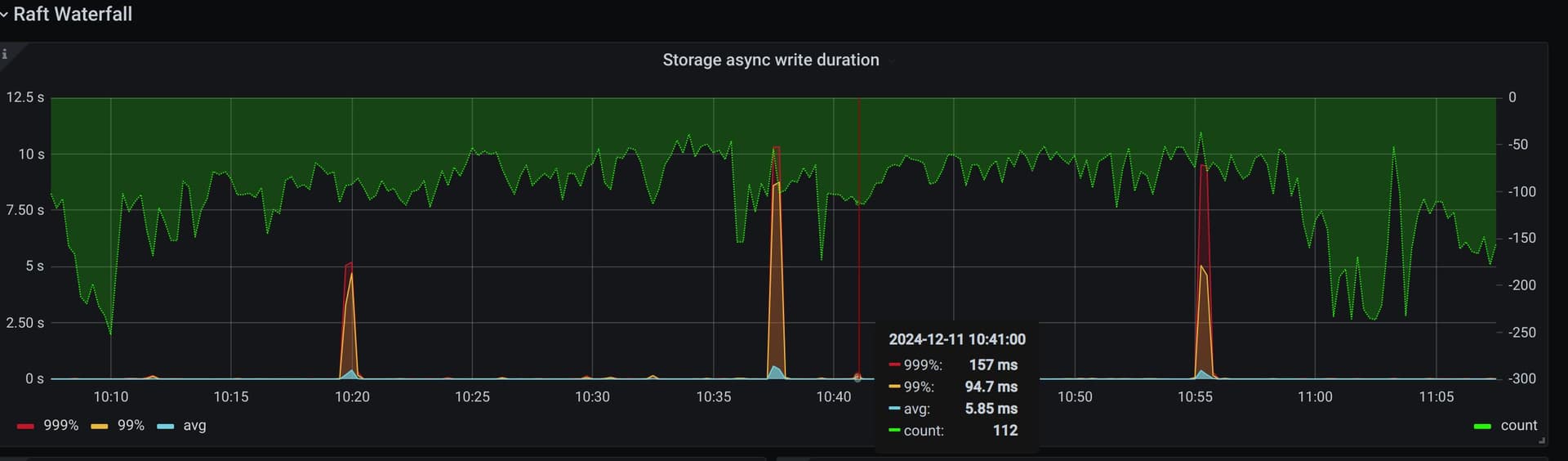
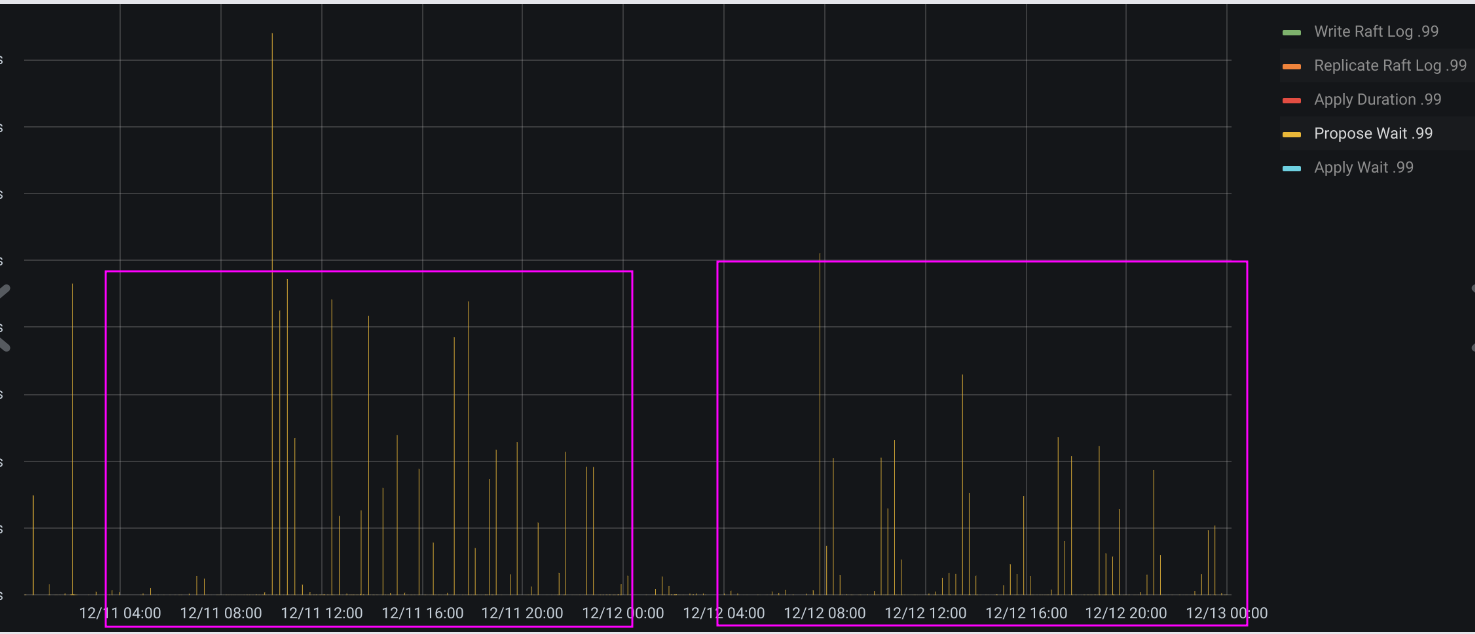
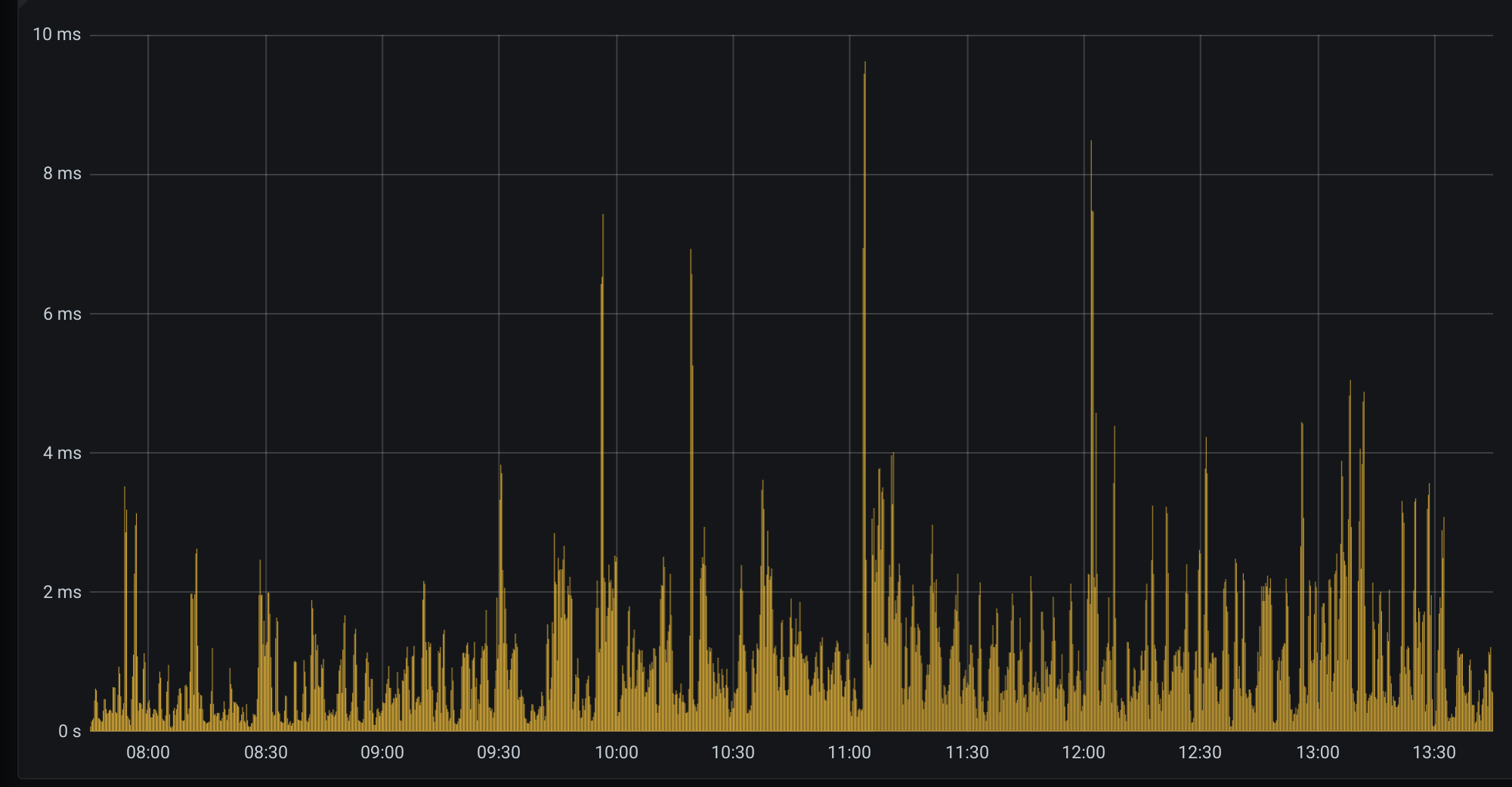
【遇到的问题:tikv 有一个节点Propose Wait.99 规律性每18分钟左右,跳高一次。个别节点(下图中的 tikv7)跳的特别高,中间一般是毫秒到微秒级,每隔18分钟左右,跳高到百ms甚至10s级别。请问下可能是什么原因导致,有哪些优化手段?
因为规规律性特别明显,我特意排查了系统的定时任务和tidb相关配置,没有看到哪些配置的值是18分钟。其中gc间隔配置的也是10分钟
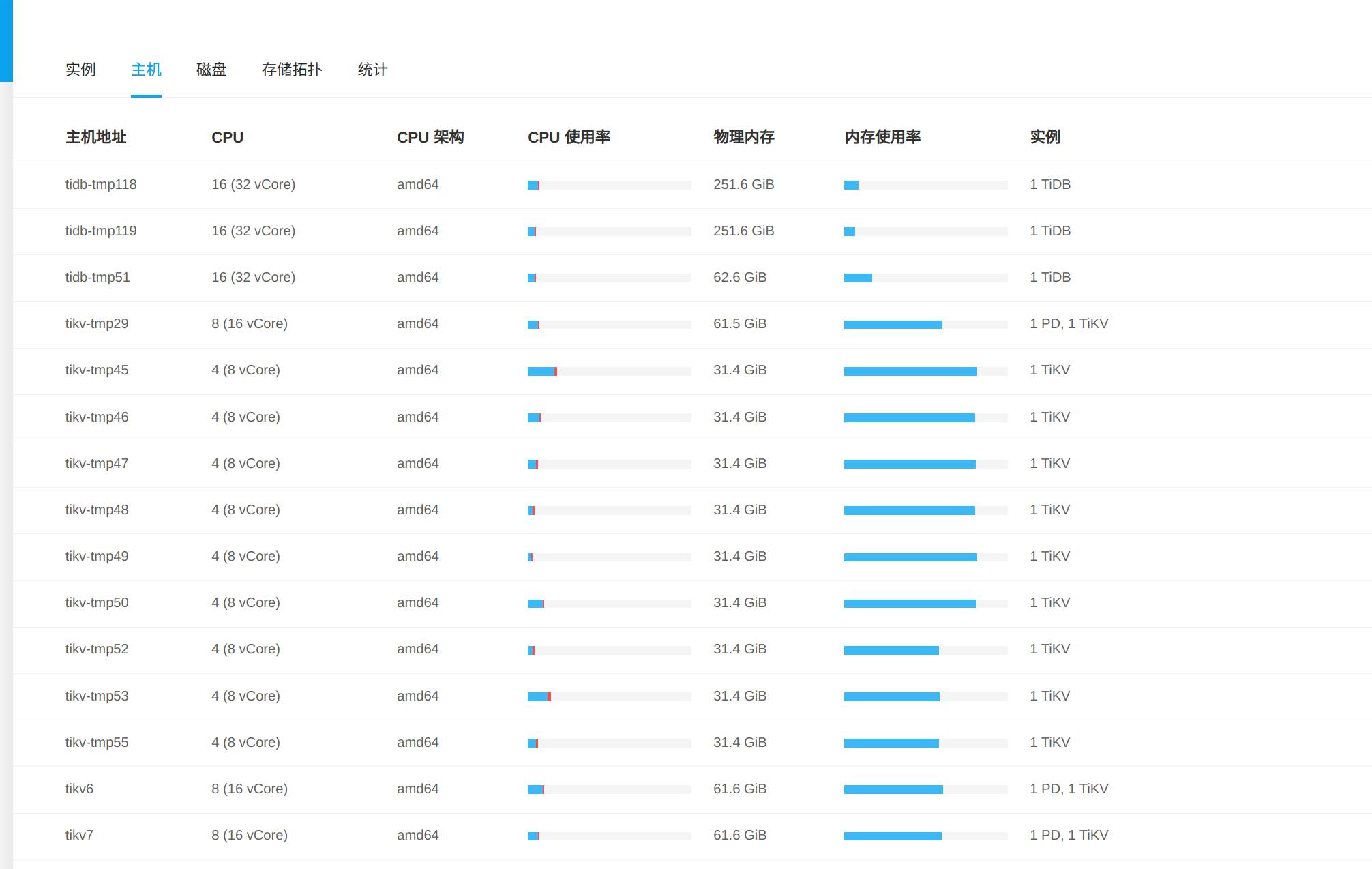
【资源配置】
【附件:截图/日志/监控】
kevinsna
(Ti D Ber P O Zcnp Ja)
3
如果磁盘使用量达到系统默认的60%,会引起Region调度,可能导致Propose Wait.99跳高。建议检查系统的high-space-ratio 和low-space-ratio 设置,并根据需要调整这些参数
liusf1993
(Liusf1993)
4
看了下,目前磁盘空间才30%左右,high-space-ratio是0.7,low-space-ratio是0.8,应该不是这个原因
liusf1993
(Liusf1993)
5
18分钟是个特殊的时间,系统定时任务和配置都没查到相关的参数
这种有规律的 时间18 ,不像系统的配置,更像自定义的值。问问其他人。配置的什么。
nobody
(不定时出现)
9
峰值和低谷期分别观察下 dashboard topsql 即可,看看峰值点多了哪些 sql ,可能会有帮助。
liusf1993
(Liusf1993)
11
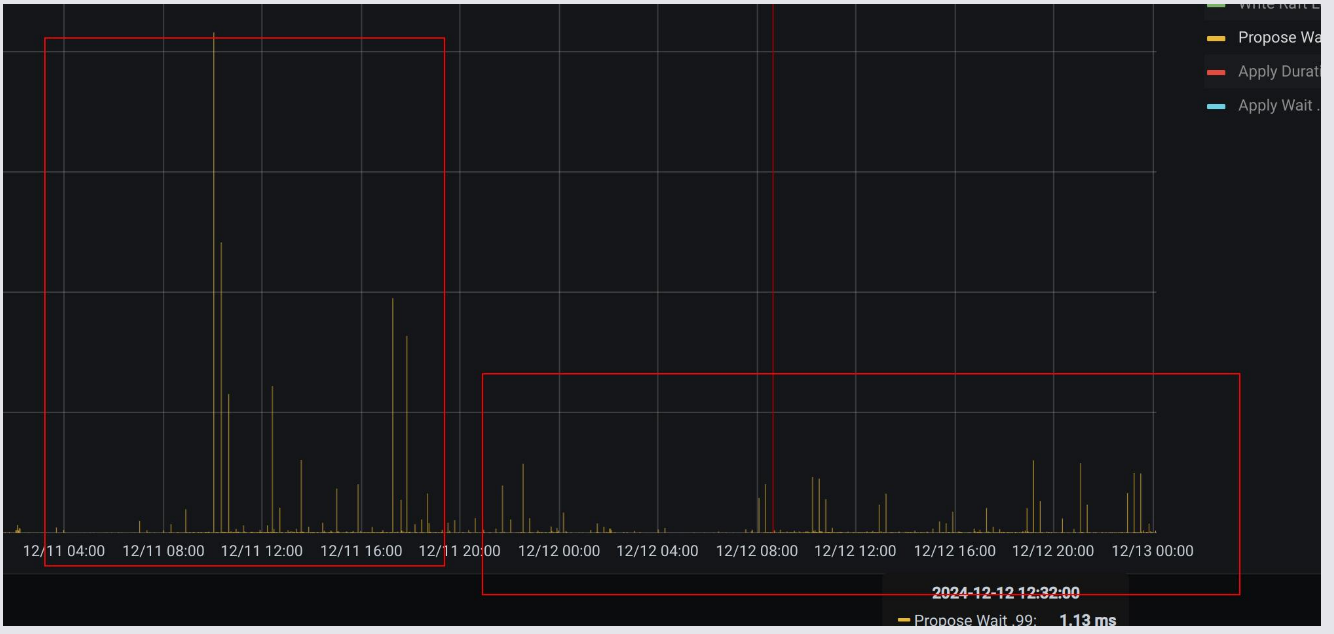
统一回复下:大家都怀疑是定时任务和热点的问题,我最开始也这么怀疑的。
定时任务排查了系统的定时任务和tidb的参数,没有找到18分钟相关的参数,慢sql和流量可视化都排查了,没发现什么线索。
这个现象在流量特别低的时间也会出现。在把热点region到其他节点后,其他节点的指标没出现跳高的情况。
现在比较怀疑可能是SSD的问题,用smartctl检测了下,也没发现啥问题。
现在没啥头绪,先把那个节点权重降低了,整体指标下降的比较明显,但那个节点单独的指标没太明显的变化。现在没啥头绪,那个节点对应的机器相对其他节点还是高配,准备把这个节点下了,重置那台服务器再看下,还有问题的话就换机器了。
2 个赞
Jasper
(Jasper)
12
只有一台 tikv 有问题,可以看下 node exporter 监控里面有没有规律的 18min, 内存和cpu 相关指标都可以看一下
会不会有xxl job之类的,定时执行了什么sql,比较慢导致的,可以排查一下看看
liusf1993
(Liusf1993)
15
统一回复下最后处理结果:
一共有12个tikv节点,有个别tikv(tikv6、tikv7)节点延迟比较高。通过迁移热点region、降低节点的权重(降到0.1),tikv、tikv7的延迟都无明显下降
最后是直接把相应节点下线了,重新换了新的机器,目前已恢复正常,所有节点表现已无明显差异。
tikv6、tikv7降权前后对比,所有节点整体服务延时下降明显,因为tikv6、tikv7对整体延时的影响降低了
tikv7降权前后对比,tikv7节点服务延时无明显变化,说明热点region和负载对tikv6、tikv7的延迟影响不大
tikv7机器更换后,整体延时基本正常,各个节点无明显差异
1 个赞
system
(system)
关闭
17
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。