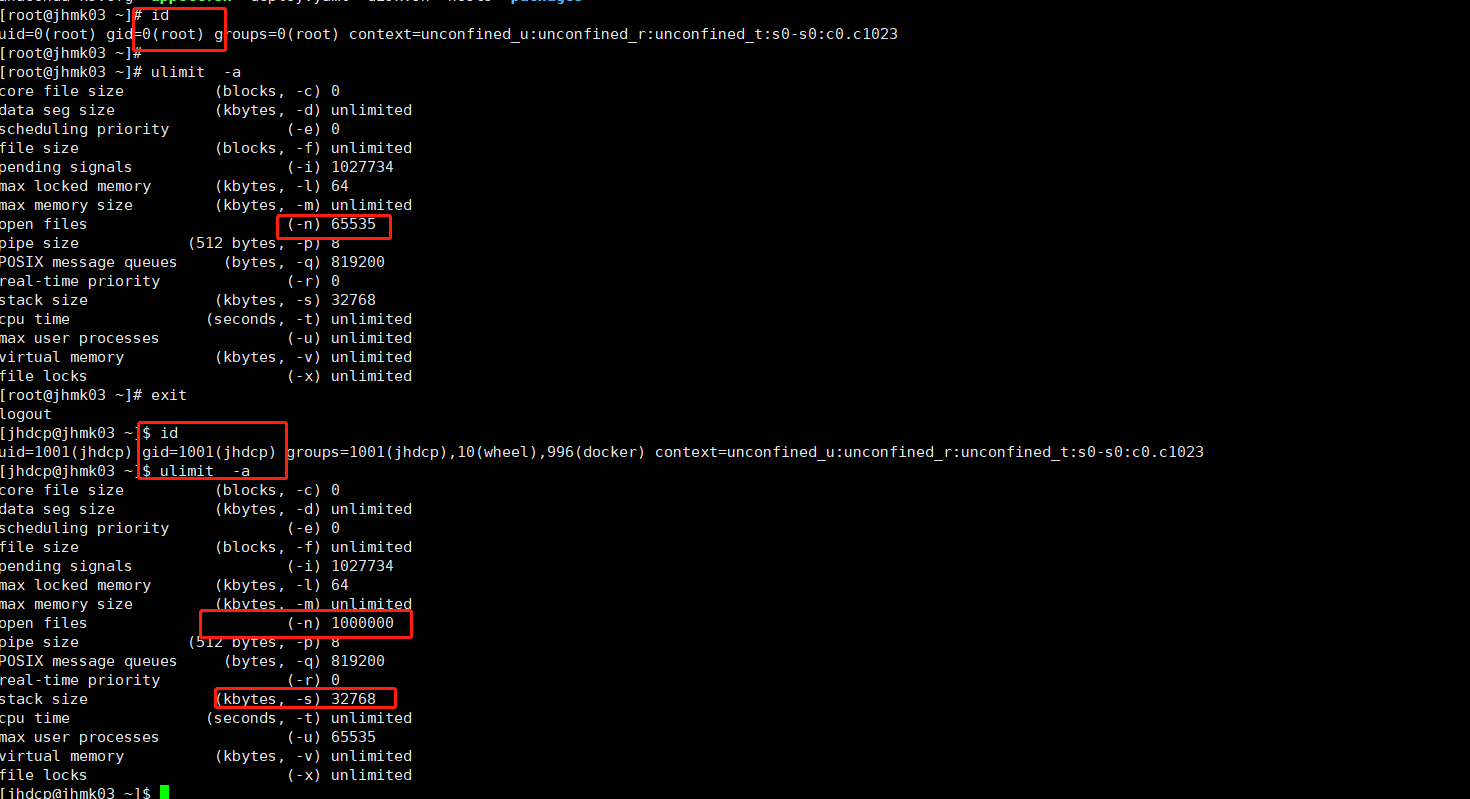
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.2
【复现路径】 部署后没有做任何操作
【遇到的问题 : 监控发现, pd 主节点 的连接数过多, 一直增长,不能释放, 直到tidb 重启后释放连接数。

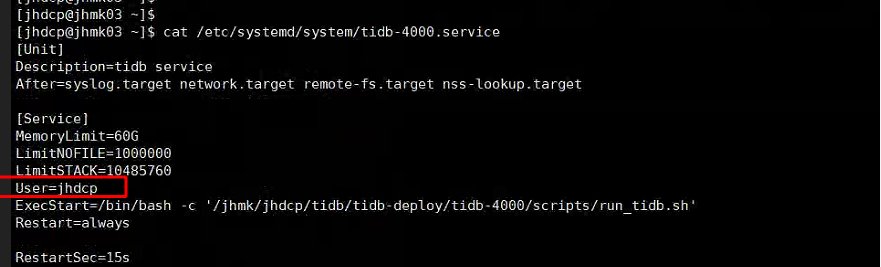
【资源配置】

【附件:截图/日志/监控】
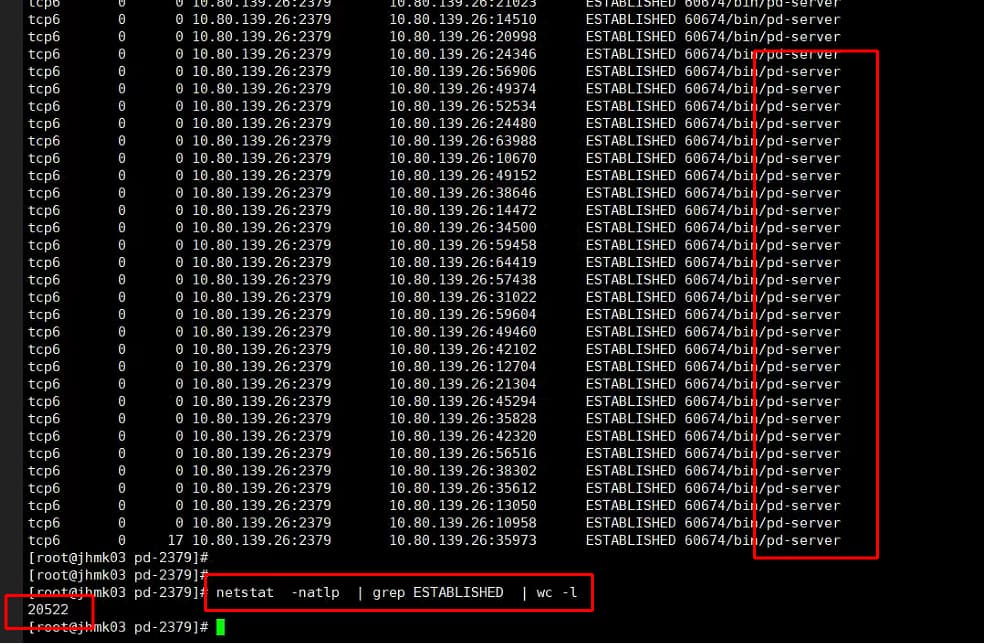
日志, 没有报错, 就是tidb 、pd 的 ESTABLISHED 过多。 而且是 tidb 连接 pd 。
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.2
【复现路径】 部署后没有做任何操作
【遇到的问题 : 监控发现, pd 主节点 的连接数过多, 一直增长,不能释放, 直到tidb 重启后释放连接数。
【资源配置】
【附件:截图/日志/监控】
日志, 没有报错, 就是tidb 、pd 的 ESTABLISHED 过多。 而且是 tidb 连接 pd 。
tiup cluster display [cluster-name]
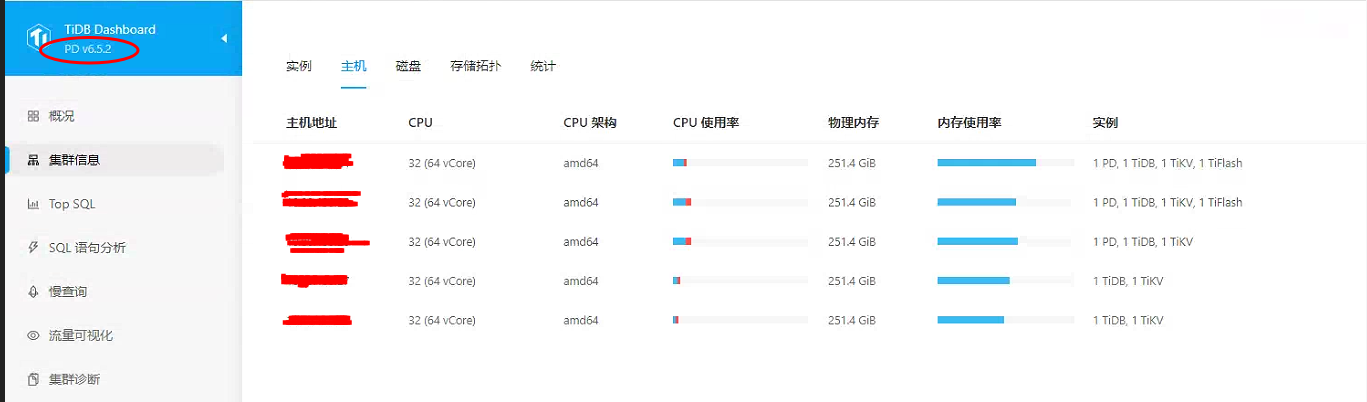
看看这个jhmk03是不是pd leader。如果是,这个连接数很正常。5个tidb要取tso都找这一个,5个tikv 2个tiflash要回报region心跳,调度region也都找这一个。
而且看
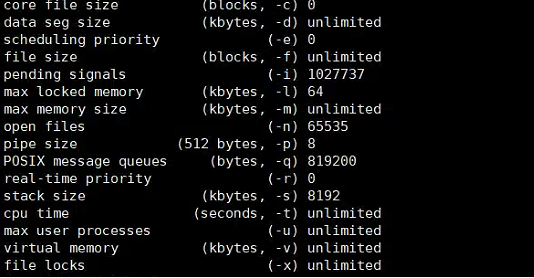
这个图,参数完全没调优。部署的时候肯定没看文档。直接就部上去了。
https://docs.pingcap.com/zh/tidb/stable/check-before-deployment
cat << EOF >>/etc/security/limits.conf
tidb soft nofile 1000000
tidb hard nofile 1000000
tidb soft stack 32768
tidb hard stack 32768
EOF
这是文档建议的参数,你看看一样嘛?这个比较简单的都没调,别的肯定更没调,建议从头到尾检查一下。
jhmk03 是 leader , 好的, 我检查一下系统参数
可以先按猫哥说的定位下问题:
之前碰到过一个类似的连接泄露的问题:
使用 auto_id_cache 的表特别多的时候,或者是 infoschema reload 过程,或者是有大量 DDL 的时候会发生这个连接泄露;
刚检查了一下, 发现tidb是jhdcp 用户部署, 参数都是按照文档设置的, 但是连接数会一直增长, 超过 65535的时候就会爆, pd 也会自动切主, tidb 会重启。 前天是 pd的主节点是jhmk02, 今天pd 的主节点是 jhmk03 。
好的, 感谢, 我看看连接泄露问题
设置没问题,大概率是bug
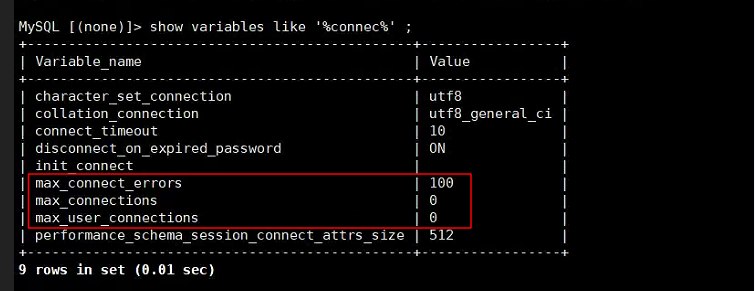
这个设置有点低吧。我的貌似是设置的error那个参数是10万
cat >> /etc/security/limits.conf <<EOF
请问 error 具体是哪个参数呢?
这个参数是按照官方设置的, 现在好像是连接数不释放, 不是连接数不够用
请问, 这个是否升级就可以解决 ? tidb 6.5.10 是否可以?
看下操作系统的 net.ipv4.tcp_retries2 是什么? 感觉可能是网络质量不好,导致 TCP 连接一直没有释放。
看错了,mysql的max_conncet_error 是10w tidb的不是
我的配置是这样你参考下:
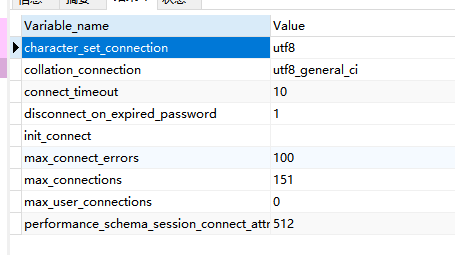
好的, 感谢分享
AUTO_ID_CACHE=1 and auto_increment
这两个条件确实用过是吗?如果确认是这个问题,我看6.5.6以上版本就能解决。
这两个都没有用 AUTO_ID_CACHE=1 and auto_increment , 这边有要求, 不能用自增列
那看起来和这个bug的描述不符。
把 net.ipv4.tcp_retries2 设置为 5 吧,这个是遵循指数退化逻辑的,15次代表要910多s 才能会将异常的 TCP 连接释放,改成 5 代表 20多秒 就不再重试了,现在网络质量都比较好,没必要重试那么多次。
看下改过后,能不能将连接稳定到一定的数目吧。