老鹰506
(Ti D Ber Uhzt Tfx J)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
原始SQL如下
SELECT
termId,
couponId,
minAmount,
favorableAmount,
number,
limitNum,
remainNum,
notShow,
updateTime,
addTime
FROM
couponTerm
WHERE
(couponId IN (4342, 43540, 43763));
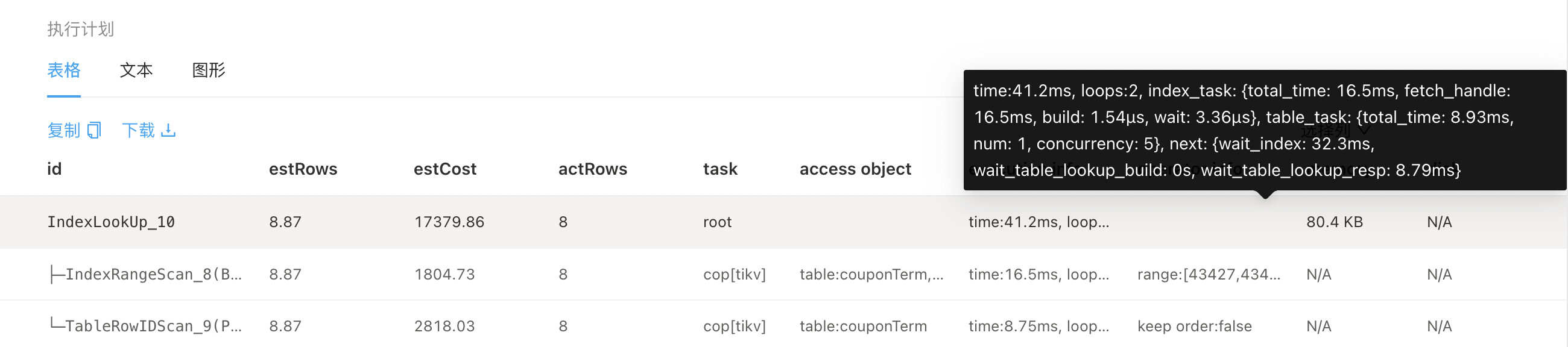
执行时间显示 其中解析耗时 1.4s
表格形式的执行计划看到 实际走了索引的执行也很快。
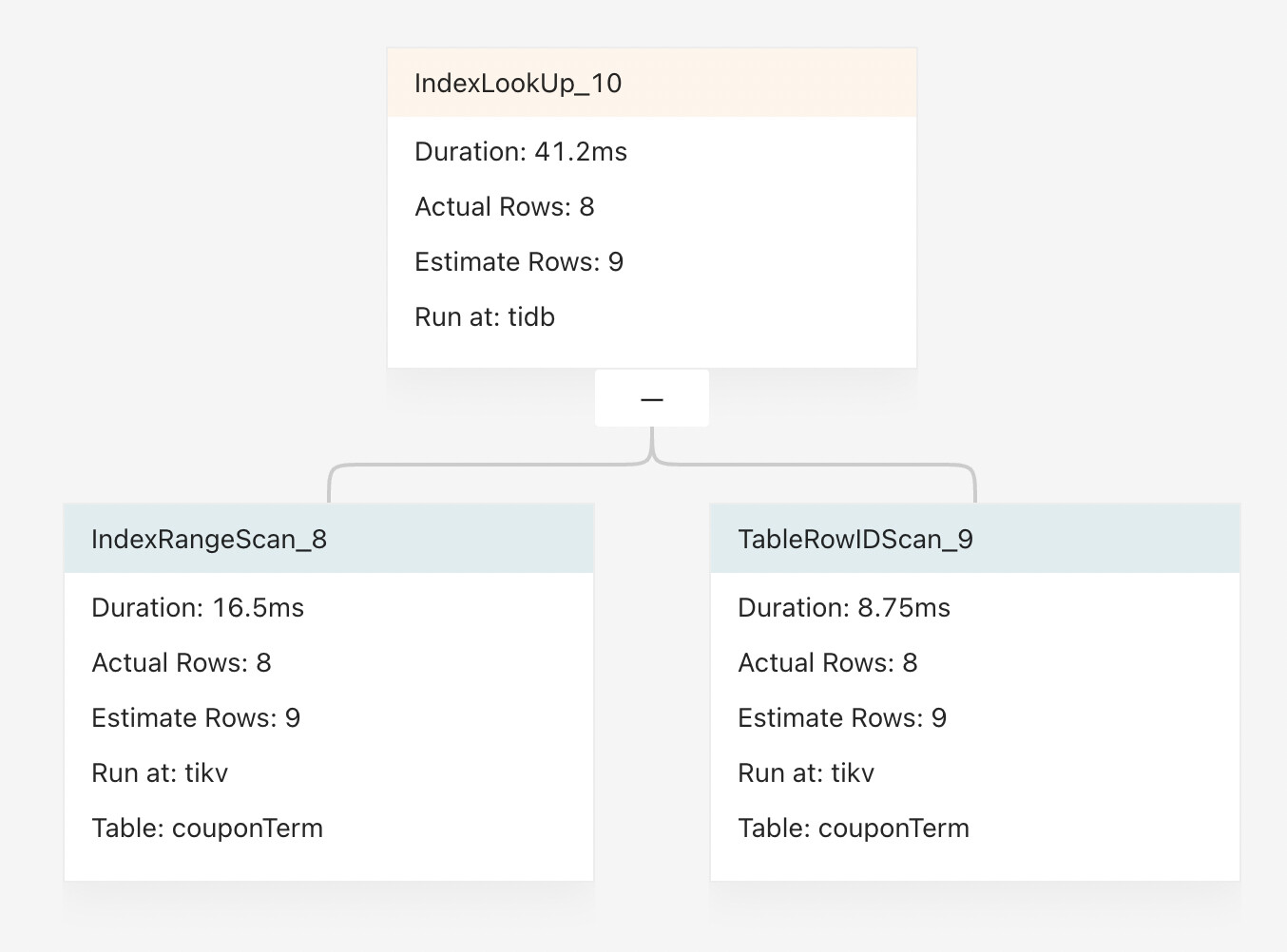
图形执行计划如下
大家有没有遇到这样的问题,如何优化呢?
小龙虾爱大龙虾
(Minghao Ren)
2
in 那里写了多少个值? 服务器资源有没有到瓶颈了呢
感觉 tidb 侧多多少少有点问题,这个sql 的话并发度很大在执行吗?对应表中是不是有很多大的 varchar 了?
老鹰506
(Ti D Ber Uhzt Tfx J)
4
in只有三个值,服务器本身性能足够呢,只是在切换了查询到 TIDB之后slave节点CPU有所波动上涨,其他性能参数都正常
老鹰506
(Ti D Ber Uhzt Tfx J)
5
这个表没有varchar类型,除了正常 tinyint bigint之外就是 timestamp 和 decimal .
tidb server 目前也没有发现明显的性能问题
只有这一个sql出现这个问题吗?还是很多sql解析都很慢?
老鹰506
(Ti D Ber Uhzt Tfx J)
8
该语句的目前只发现这一个,后续因为影响业务,已经切换到MySQL库了。倒是发现类似其他的问题,比如 “生成执行计划耗时”也有很慢的情况
可以看一下tidb的cpu,慢的时候抓一下火焰图看看。
curl -sl http://127.0.0.1:10080/debug/zip?seconds=60 --output tidb_debug.zip
1 个赞
yg_2024
(yangguang)
11
我们也碰到了类似问题,目前是通过加大软解析比例去做的临时解决。首先是需要调大数据库里的tidb_session_plan_cache_size参数增加数据库侧对执行计划的缓存(该参数默认才100)。然后是调整应用的jdbc连接串,建议的URL配置如下:
spring.datasource.url=JDBC:mysql://{TiDBIP}:{TiDBPort}/{DBName}?characterEncoding=utf8&useSSL=false&useServerPrepStmts=true&cachePrepStmts=true&prepStmtCacheSqlLimit=10000&prepStmtCacheSize=1000&useConfigs=maxPerformance&rewriteBatchedStatements=true&defaultfetchsize=-2147483648
Prepare 相关参数
useServerPrepStmts
默认情况下,useServerPrepStmts 的值为 false,即尽管使用了 Prepare API,也只会在客户端做 “prepare”。因此为了避免服务器重复解析的开销,如果同一条 SQL 语句需要多次使用 Prepare API,则建议设置该选项为 true。
cachePrepStmts
UseServerPrepStmts = true 使服务端执行预处理语句,但默认情况下客户端每次执行完后会 close 预处理语句,并不会复用,导致预处理的效率甚至不如文本执行,所以建议开启 useServerPrepStmts = true 后同时配置 cachePrepStmts = true,这会让客户端缓存预处理语句。
prepStmtCacheSqlLimit
在配置 cachePrepStmts 后还需要注意 prepStmtCacheSqlLimit 配置(默认为 256),该配置控制客户端缓存预处理语句的最大长度,超过该长度将不会被缓存。
prepStmtCacheSize
prepStmtCacheSize 控制缓存的预处理语句数目(默认为 25),如果应用需要预处理的 SQL 种类很多且希望复用预处理语句,可以调大该值,结合内部测试及客户使用经验,建议配置为1000。
1 个赞
有猫万事足
13
tidb菜鸟一只
(小菜一颗)
14
如果是单个sql的话,应该就不是tidb-server的问题,一般这种都是tidb-server资源不足会出现这种情况,我的建议也是开启tidb_enable_non_prepared_plan_cache ,这样起码只会第一次慢,后面回复用执行计划不用每次解析了。
SET tidb_enable_non_prepared_plan_cache = ON;
老鹰506
(Ti D Ber Uhzt Tfx J)
15
昨天开启了结果遇到server节点内存持续上涨的情况,plan_cache涨了2G,但是server涨了好多,下的赶紧关了。还在分析中
老鹰506
(Ti D Ber Uhzt Tfx J)
16
不是一个SQL,是不同的SQL都会遇到,同一个SQL又不是每次都这样。昨天尝试开启这个参数了但是遇到server节点内存上涨的问题。在分析中
老鹰506
(Ti D Ber Uhzt Tfx J)
18
sql 过长是指sql 语句本身过长嘛,比如一个表有50个字段,select 列举了其中40个字段吗?
WalterWj
(王军 - PingCAP)
19
你这个不算长,sql 语句本身长,比如你 in 很多,sql 文本长度达到 MB 级别。
老鹰506
(Ti D Ber Uhzt Tfx J)
20
那到没有这么长的SQL,目前99分位响应时长还算可以,打算继续切业务过来在观察下。这个异常慢查在继续跟进